Un agente que se autocritica y mejora antes de responder eleva la calidad de salida. Con el patrón Evaluator Optimizer, un flujo con ciclo controla cuándo una respuesta está lista: genera, evalúa con criterios claros, recibe feedback, reintenta y solo finaliza si pasa la evaluación. Aquí verás cómo se arma en LangGraph Studio con routing edge, conditional edge y structured output.
¿Qué es el patrón evaluator optimizer y cómo funciona?
Este patrón crea un ciclo de autocrítica entre un generator node y un Evaluator. El generador produce una respuesta con un language model. El Evaluator la juzga según criterios definidos en el prompt y devuelve un veredicto. Si es correcta, se envía al final; si no, retorna al generador con feedback para mejorar.
Generador. Produce un primer intento con un large language model.
Evaluator. Aplica reglas definidas en el prompt y escribe su evaluación en el state.
Loop. Si falla, el generador reintenta usando el feedback previo. Si aprueba, finaliza.
Criterios configurables. Se definen en el prompt del Evaluator: tú decides qué es “bueno”.
Así, un simple chain evoluciona a un ciclo controlado donde el Evaluator decide si “va al end” o “regresa al generator”.
¿Cómo configurar el chain con routing edge y conditional edge?
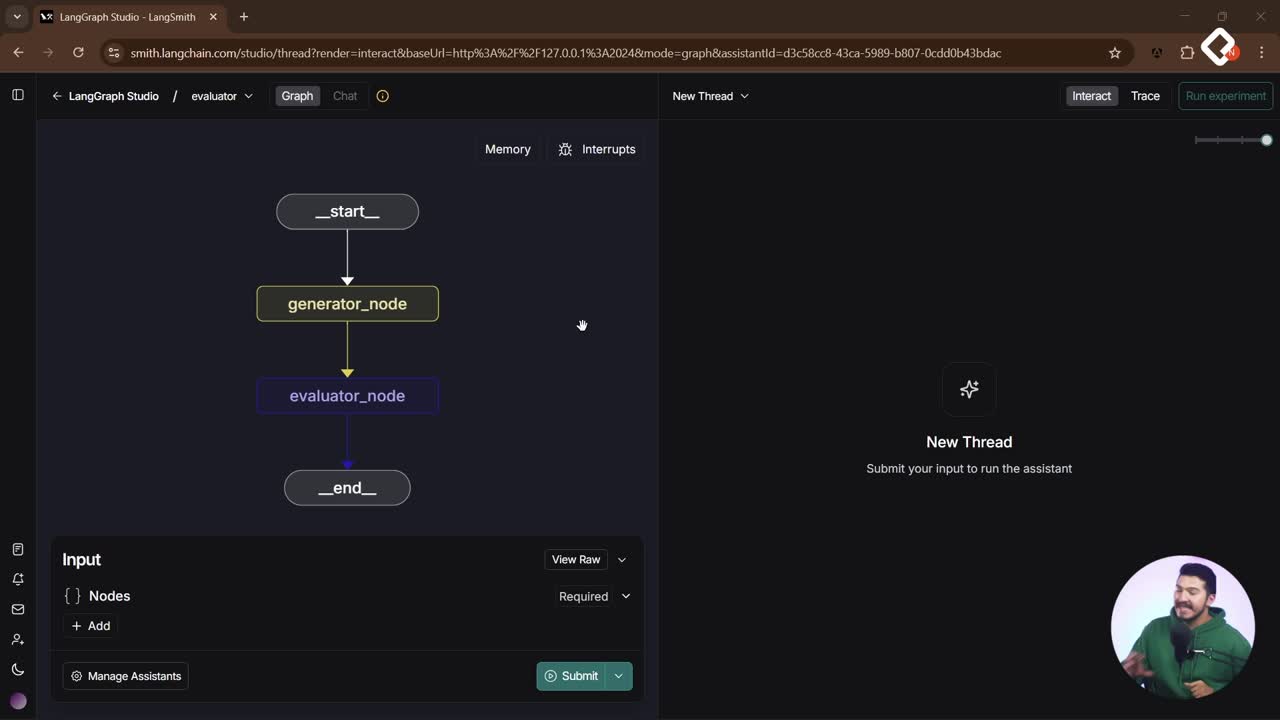
Se parte de un template de chain con tres nodos: inicial, generator node y Evaluator. Para cerrar el ciclo, se agrega un conditional edge desde el Evaluator hacia un routing edge, que decide si se finaliza o se reintenta.
Routing edge con random. Regla base: si el “promedio” es < 0.5, va a end; si no, regresa al generador. Esto permite ver ciclos aleatorios.
Flujo visual en LangGraph Studio. El generador siempre va al Evaluator. El Evaluator puede finalizar o devolver. Se observan uno o varios ciclos según la condición.
Estado compartido. El Evaluator deja su veredicto y feedback en el state. El routing edge lee el state y decide.
Ejemplo de la lógica del routing edge:
if promedio <0.5: goto("end")else: goto("generator")
¿Cómo integrar un ejemplo con language model para chistes y feedback?
Se implementa un generador de chistes con structured output en el Evaluator. El Evaluator devuelve si el chiste fue “gracioso” y, si no, un feedback para mejorar. El generador usa ese feedback y reintenta hasta pasar.
Structured output. El Evaluator no responde conversacionalmente, sino con un esquema.
{"gracioso":true | false,"feedback":"texto con sugerencias para mejorar"}
Prompting del generador. Si hay feedback en el state, el prompt cambia: “Escribe una broma sobre [topic] considerando el feedback y responde en español”. Si no hay feedback, solo usa el topic.
Parámetros del LLM. Generador con temperatura 1 para variedad; Evaluator con temperatura 0 para consistencia. Para forzar el loop, se bajó la temperatura a 0 en ambos y se usaron prompts que favorecen chistes más “aburridos”.
Reglas explícitas en el Evaluator. Se añadió un system prompt con un criterio: “un chiste gracioso debe tener más de dos párrafos”. Así, chistes cortos fallan, generan feedback y el generador los extiende en la siguiente iteración.
¿Qué criterios define el prompt del evaluator?
Longitud mínima del chiste en párrafos.
Calidad percibida: gracioso sí/no como booleano.
Razón del fallo en feedback accionable.
¿Qué rol cumplen state, topic y feedback?
State. Guarda el veredicto y el feedback del Evaluator.
Topic. Tema base para generar la broma.
Feedback. Instrucciones específicas para mejorar la siguiente versión.
¿Cómo se ve el ciclo completo con LangGraph Studio?
Generador crea un chiste sobre el topic.
Evaluator juzga con structured output y escribe en state.
Routing edge lee el state: si gracioso, end; si no, regresa al generador.
Generador reescribe aplicando feedback hasta aprobar.
Palabras clave y habilidades que se practican:
Evaluator Optimizer. diseño de ciclos de mejora automática.
Routing edge y conditional edge. control de flujo dinámico.
Structured output. evaluación determinística con esquema.
Prompt engineering para criterios y reintentos.
Temperatura del LLM para creatividad vs. consistencia.
Gestión de estado para pasar feedback entre nodos.
¿Te gustaría ver este patrón aplicado a otro caso, como resúmenes, SQL o verificación de fuentes? Cuéntame en qué flujo lo implementarías y qué criterios usarías en el Evaluator.
Evaluator Optimizer: ciclos de autocrítica para agentes de IA