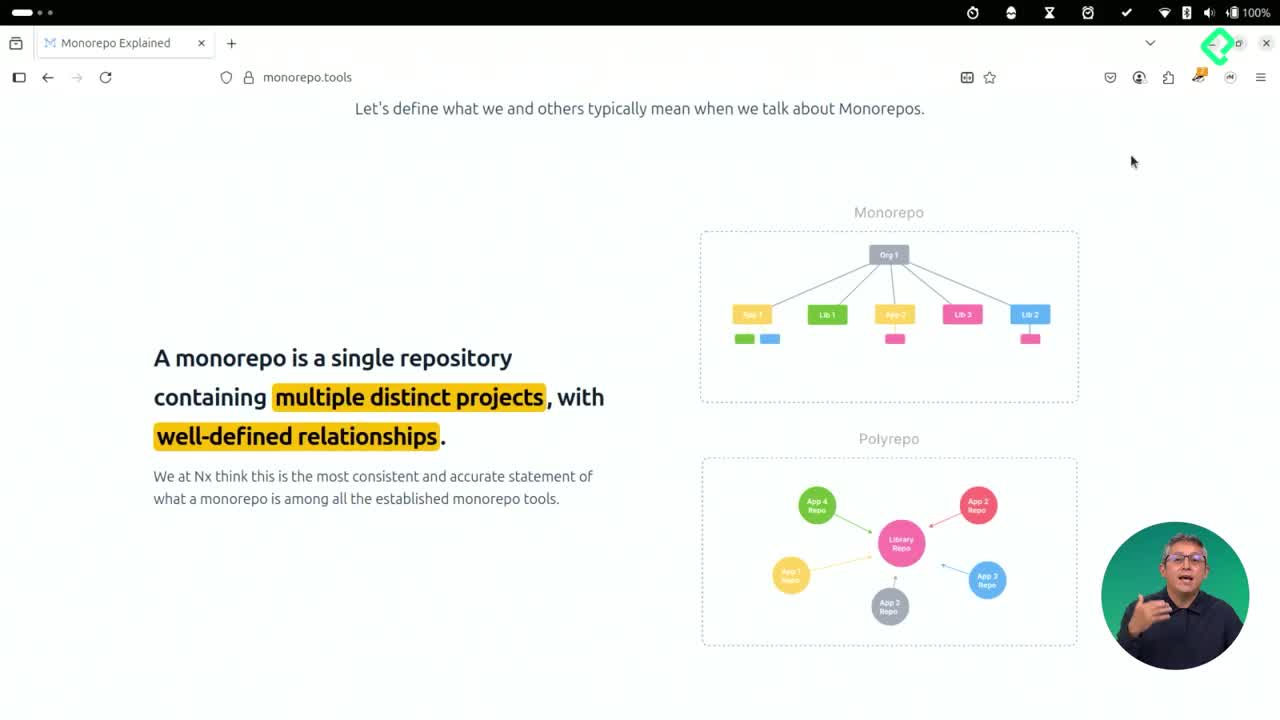
La infraestructura como código ha transformado la manera en que equipos de software gestionan entornos complejos para pruebas, desarrollo y producción. Al trabajar en un monorepo, es fundamental aprovechar herramientas y patrones reconocidos, manteniendo siempre enfocadas las implicaciones técnicas y económicas de las plataformas.
¿Qué es la infraestructura como código y por qué es esencial en un monorepo?
Tener infraestructura definida como código permite replicar, versionar y mantener entornos consistentes. Es importante distinguir entre los diferentes entornos: desarrollo, pruebas y producción. Esta separación facilita la integración y el despliegue continuo en proyectos donde múltiples equipos colaboran.
Elegir estándares abiertos como Kubernetes ayuda a abstraerse de infraestructuras fuera de nuestro control, algo crucial en escenarios como la integración con entidades gubernamentales o sistemas aduaneros. Así, se pueden usar diversas opciones del mercado, incluso multi cloud, sin depender de un único proveedor.
¿Qué aspectos considerar al desplegar microservicios con infraestructura como código?
El despliegue de microservicios requiere prestar atención a recursos del sistema, latencias de red y pruebas de rendimiento. Hay que considerar detalladamente:
- Pruebas de rendimiento para cada componente.
- Latencia de red, sobre todo en cargas de trabajo en tiempo real.
- Ownership: definir si la infraestructura la gestiona cada equipo de desarrollo o un equipo centralizado.
- Comunicación eficaz entre equipos para evitar conflictos.
- Revisión frecuente de la cultura de equipo en torno a la infraestructura.
¿Cómo afectan los proveedores y los costos al manejar infraestructura como código?
Al utilizar SDKs de proveedores de nube, se generan dependencias técnicas y económicas. Es vital revisar los well-architected frameworks de cada opción. Considera:
- Posibles recargos por intercambio de datos fuera de la nube.
- Restricciones si necesitas integrar sistemas on premises o con infraestructura gubernamental.
- Impacto económico al diseñar arquitecturas escalables para el sistema y microservicios.
¿Cuáles son los patrones recomendados para cambios de infraestructura y despliegues?
Los dos patrones más útiles descritos son:
- Blue-green deployments: Permiten una transición transparente entre versiones de servicios con mínimo impacto al usuario. Consiste en mantener dos entornos (blue y green) y migrar paulatinamente el tráfico.
- Canary deployments: Consiste en enviar un pequeño porcentaje del tráfico a la nueva versión (por ejemplo, 5 %) y el resto (95 %) a la versión estable. Si todo va bien, se va incrementando el tráfico hacia la nueva versión.
Ambas técnicas exigen cuidado en los costos y rigurosidad con los modelos de datos, en especial para migraciones entre bases de datos.
¿Tienes preguntas sobre cómo se implementan los blue-green deployments o los canary deployments en tu flujo de trabajo actual? Comparte tus dudas y experiencias en los comentarios.