Mejorar el rendimiento de un proyecto web puede ser tan sencillo como identificar y reducir consultas innecesarias a la base de datos. Cuando el sistema realiza muchas consultas en el home sin una causa clara, es clave analizar la raíz y ajustar el código desde el repositorio. A continuación, se presentan los puntos clave para lograrlo y se destacan prácticas recomendadas directamente basadas en el proceso mostrado en la transcripción.
¿Cómo identificar un problema de rendimiento por consultas excesivas en el home?
Comprobar el número de consultas que se ejecutan en el home es crucial. Herramientas de depuración pueden mostrar fácilmente si existen, por ejemplo, 61 consultas ejecutándose en una sola vista. Observar cada consulta permite entender dónde surge el problema. Normalmente, esto sucede cuando en el controlador o en la vista se generan múltiples consultas por cada ciclo, como loops for.
- Realizar consultas dentro de la vista (template) incrementa innecesariamente el número total.
- Contar y visualizar elementos relacionados (como usuarios) dentro del ciclo añade más consultas por cada elemento procesado.
¿Cómo optimizar el acceso a datos desde el repositorio?
La solución es clara: devolver toda la información desde el repositorio y el controlador, evitando nuevas consultas en la vista. Para ello hay que crear un método personalizado en el repositorio, apoyado en la estructura existente para manejar entidades y sus relaciones.
¿Qué pasos seguir para construir un método personalizado eficiente?
- Revisar y entender la estructura base del repositorio, verificando qué métodos están predefinidos para búsquedas generales.
- Escribir un nuevo método de consulta personalizada, nombrado claramente en el repositorio y documentado según las convenciones del proyecto.
- Utilizar el query builder con alias descriptivos, por ejemplo, nombrar cada entidad con su nombre completo en lugar de iniciales ambiguas.
- Incluir joins para cargar relaciones necesarias (comentarios, autores) en una sola consulta.
- Definir correctamente los select y nombres, asegurándose de alinear lo consultado con las relaciones registradas en el sistema.
- Ordenar los resultados según sea necesario, como por el identificador descendente.
- Retornar el resultado con un método adecuado como getQuery y luego obtener el resultado final para pasarlo desde el controlador hasta la vista.
¿Qué beneficios se logran al reducir consultas en la vista?
Al consolidar la información en una única consulta personalizada:
- Se elimina la generación de múltiples consultas por cada elemento procesado en la vista.
- El rendimiento mejora de inmediato, reflejando una sola consulta en vez de varias decenas.
- El proyecto queda preparado para escalar y manejas casos con mayor número de datos sin afectar la velocidad.
¿Qué reto permite reforzar este aprendizaje?
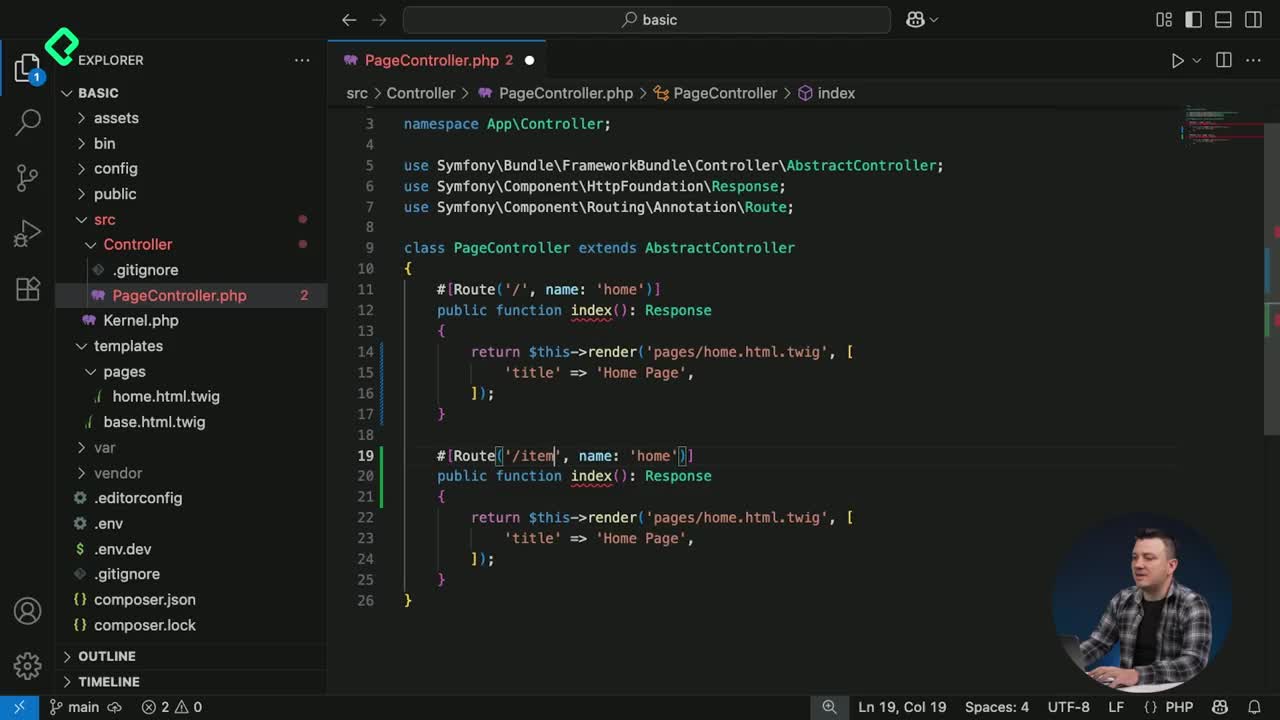
Como práctica adicional, se propone crear un método personalizado para la consulta de un solo ítem. El objetivo es evitar que la cantidad de consultas varíe según los datos asociados (como el número de comentarios o autores). Así lograrás eficiencia y uniformidad también en la visualización de elementos individuales.
Participa en la discusión: ¿cuáles son tus estrategias favoritas para optimizar consultas en tus proyectos? ¿Qué patrón te ha sorprendido al reducir consultas redundantes?