Perder tus hábitos tras cada recarga frustra y dificulta el debug. Aquí verás cómo integrar persistencia con localStorage guiándote de la AI sin sacrificar buenas prácticas: usa back coding con criterio, aplica repository pattern y respeta Open-Closed para cambiar de fuente de datos sin tocar la lógica central.
¿Por qué la persistencia con localStorage mejora tu app de hábitos?
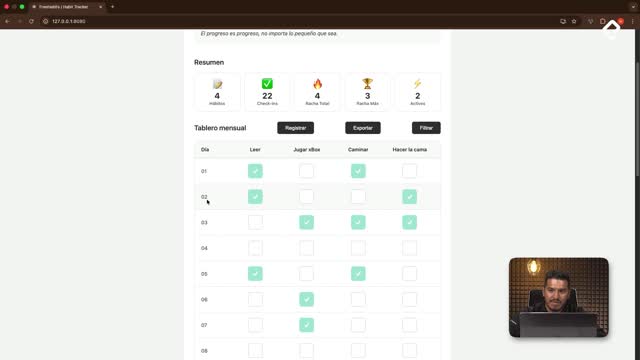
Agregar localStorage permite que los datos sobrevivan a recargas y hard reloads. No reemplaza una base de datos, pero es ideal para prototipos y para enfocarte en la UX mientras preparas un backend.
Mejora la experiencia: los hábitos y sus rachas permanecen entre sesiones.
Facilita el desarrollo: hace más simple debuggear al mantener el estado.
Es inmediata: no dependes aún de APIs ni servidores.
La validación es directa: crea hábitos, marca check-ins, recarga o abre en otra pestaña; la data debe persistir. Si ocurre, la integración es correcta y limpia.
¿Cómo guiar a la AI con prompts claros y buenas prácticas?
Un prompt vago como “Implementar persistencia” es insuficiente. Detalla la técnica, el archivo y el patrón deseado. Itera: trata la primera respuesta como borrador, revisa cambios y pide explicaciones si algo no cuadra. Aplica rollback cuando sea necesario.
Sé específico: “usar localStorage en app.js”.
Indica arquitectura: “seguir repository pattern y principio Open-Closed”.
Define reglas de identidad: “el ID se recibe en el constructor; si viene nulo, usar createID()”.
Solicita serialización clara: “objetos a plano con JSON y reconstrucción al leer”.
Cuando la AI propuso un options para el constructor, se evaluó y se prefirió pasar el ID como tercer parámetro. También se movió la sincronización al servicio de dominio, evitando llamadas imperativas en clics.
¿Qué ajustes de código son clave?
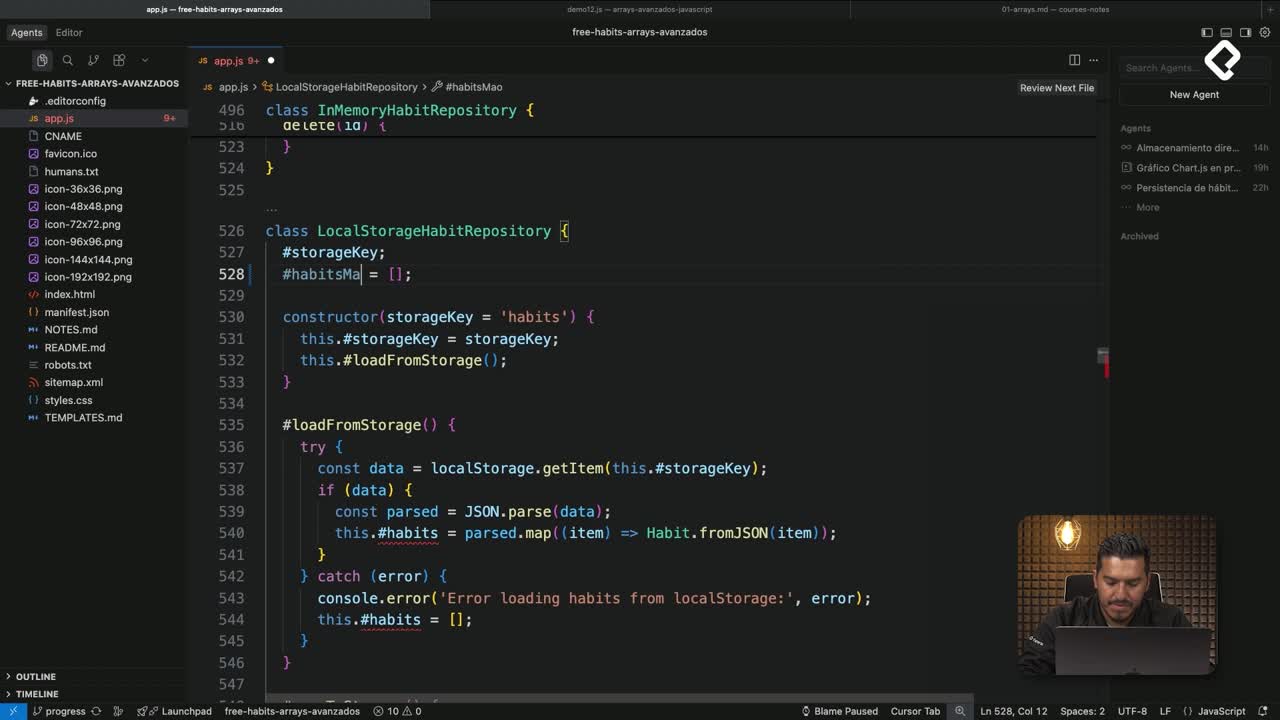
Serializar entidades antes de guardar: el navegador almacena datos planos.
Reconstruir objetos al leer: mapear a instancias preservando el ID.
Sincronizar en el servicio (no en manejadores de eventos): más limpio y confiable.
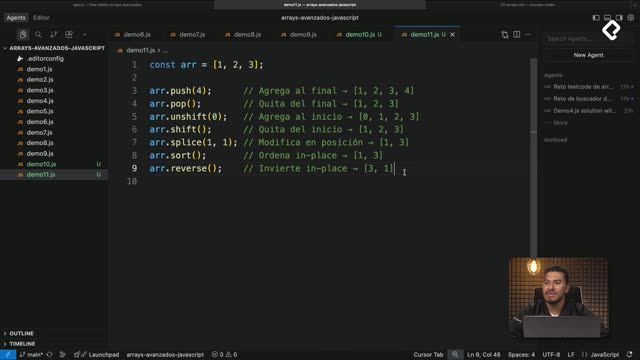
// Entidad Habit: preserva o genera IDclassHabit{constructor(name, frequency, id){this.id= id ??createID();this.name= name;this.frequency= frequency;// ...otras props.}toJSON(){return{id:this.id,name:this.name,frequency:this.frequency/* ... */};}}
Guarda en plano con JSON.stringify y lee con JSON.parse.
Usa map para serializar y deserializar de forma consistente.
// Utilidad de persistencia básicaconstKEY='habits';constreadAll=()=>JSON.parse(localStorage.getItem(KEY)||'[]');constwriteAll=(items)=>localStorage.setItem(KEY,JSON.stringify(items));
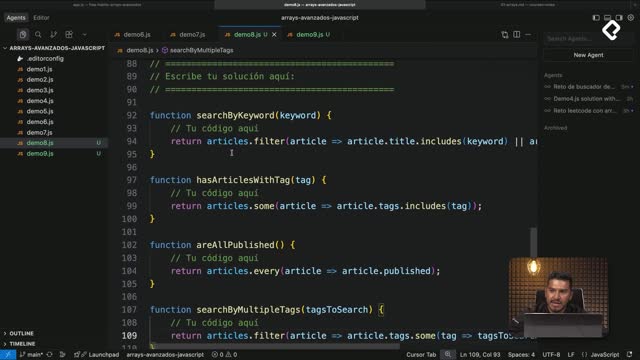
¿Cómo aplicar repository pattern y principio open-closed en JavaScript?
El repository pattern permite cambiar de fuente de datos (in memory, localStorage, IndexedDB o un API) sin tocar la lógica de negocio. Así se respeta Open-Closed: abierto a extensión, cerrado a modificación.
Define un contrato común para repositorios.
Implementa una variante para localStorage.
Conecta el servicio de hábitos al contrato, no a una implementación.
Algunas AI incluso propusieron una clase base (p. ej., HabitRepository) que otras extienden con extends, lo que facilita pruebas y reemplazos.
¿Ejemplo de repository para localStorage?
// Contrato base (opcional, útil para guiar a la AI)classHabitRepository{save(habit){thrownewError('not implemented');}remove(id){thrownewError('not implemented');}findById(id){thrownewError('not implemented');}findAll(){thrownewError('not implemented');}}// Implementación con localStorageclassLocalStorageHabitRepositoryextendsHabitRepository{save(habit){const list =readAll();const idx = list.findIndex(h=> h.id=== habit.id);if(idx >=0) list[idx]= habit.toJSON();else list.push(habit.toJSON());writeAll(list);}remove(id){writeAll(readAll().filter(h=> h.id!== id));}findById(id){const raw =readAll().find(h=> h.id=== id);return raw ?newHabit(raw.name, raw.frequency, raw.id):null;}findAll(){returnreadAll().map(raw=>newHabit(raw.name, raw.frequency, raw.id));}}
Integra la sincronización dentro del servicio de dominio (p. ej., al hacer check-in o remove), no en clics individuales. Así el estado se guarda siempre que las entidades cambian y el código queda más limpio.
¿Qué habilidades y conceptos se refuerzan?
Redacción de prompts efectivos y específicos.
Criterio al usar back coding: nunca implementar lo que no se entiende.
Serialización con JSON y uso de map para transformar colecciones.
Gestión de IDs estables entre sesiones.
Iteración con rollback y revisión crítica de cambios.
Aplicación de repository pattern y Open-Closed.
Diseño orientado a entidades y servicios, evitando lógica imperativa dispersa.
Pruebas manuales en navegador con nuevas pestañas y recargas.
Uso comparado de Cursor, Gemini y ChatGPT con contexto adjunto.
¿Quieres comentar cómo estructurarías el contrato del repositorio o qué prompt te funcionó mejor con tu stack?
LocalStorage con AI: repository pattern sin código basura