Construir una API serverless que permita insertar usuarios en DynamoDB mediante una función Lambda es uno de los pasos fundamentales para dominar arquitecturas en la nube. Aquí se desglosa todo el proceso: desde reorganizar la estructura de carpetas hasta desplegar y probar con Postman, pasando por el refactoring necesario cuando un proyecto crece de un solo endpoint a múltiples operaciones CRUD.
¿Por qué reorganizar el folder structure antes de crear el POST?
Cuando un proyecto arranca con una sola función Lambda (como el GET), todo el código puede vivir en un único handler. Sin embargo, al añadir operaciones como create, update y delete, es buena práctica separar cada función en su propia carpeta [0:55]. Esto se conoce como una estructura modular y es un patrón habitual en la industria.
El proceso consiste en:
- Crear una carpeta create-users al mismo nivel que get-users.
- Copiar los archivos compartidos: carpeta de DynamoDB, node_modules,
package.json, package-lock.json y la carpeta de Serverless.
- Mantener el archivo
serverless.yml en el root del proyecto.
Una vez reorganizado, se copia el handler del GET como punto de partida y se adapta para el POST. Es importante renombrar la función exportada de getUser a createUser para evitar confusiones [2:40].
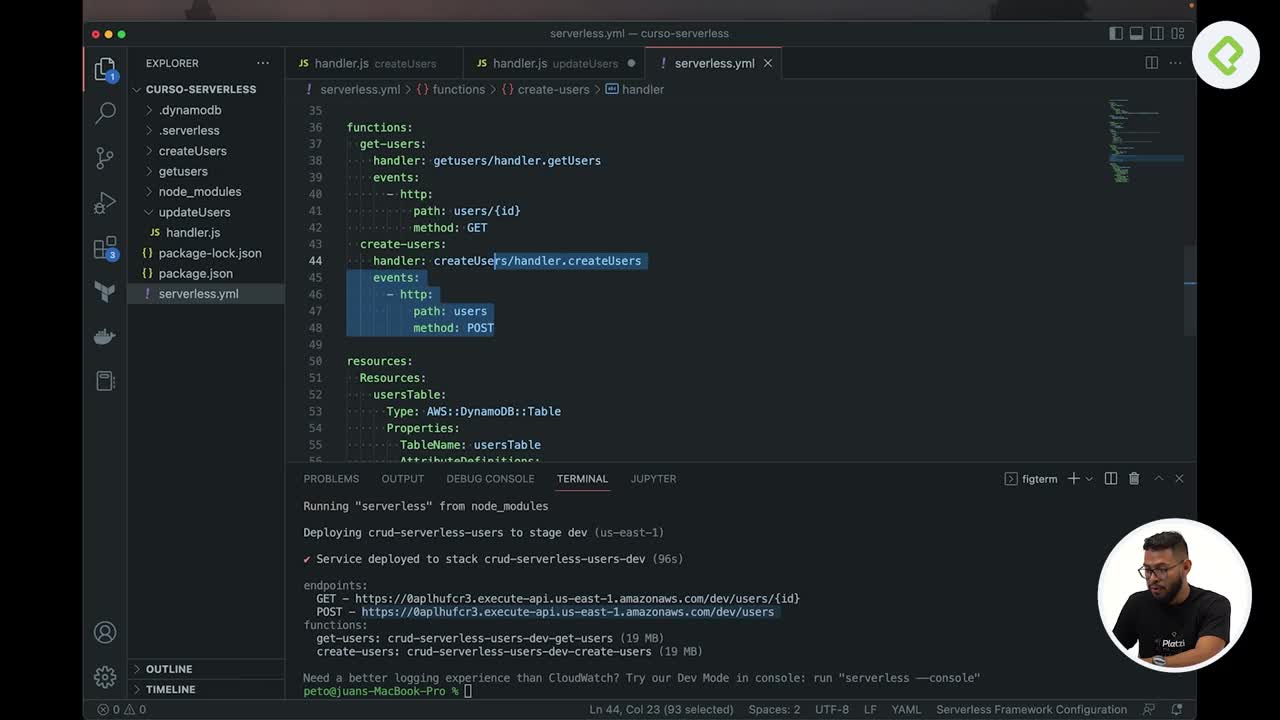
¿Cómo se configura el serverless.yml para múltiples funciones Lambda?
El archivo serverless.yml debe reflejar la nueva estructura. Ahora se definen dos funciones Lambda con sus respectivos handlers apuntando a las carpetas correctas [3:05]:
- get-users: asociado al método HTTP
GET y al path users/{id}.
- create-users: asociado al método HTTP
POST y al path users.
Cada handler referencia su carpeta específica, por ejemplo create-users/handler.createUser. Un error común es olvidar actualizar estas rutas cuando cambia el folder structure.
¿Qué es el random UUID y por qué no enviar el ID en el body?
Para generar identificadores únicos sin depender del cliente, se importa la función randomUUID de la librería nativa crypto de Node.js [6:15]. Esto garantiza que cada usuario insertado tenga un primary key diferente y evita falencias a nivel de seguridad que surgirían si el ID viniera directamente en el cuerpo de la petición.
El flujo dentro del handler queda así:
- Se genera un
id con randomUUID().
- Se extrae el cuerpo de la petición con
JSON.parse(event.body), una transformación necesaria porque el body llega como string [7:50].
- Se asigna dinámicamente el ID al objeto del usuario:
userBody.pk = id.
¿Cómo se adaptan los parámetros para insertar en DynamoDB?
A diferencia del GET, que utiliza expression attribute values y condiciones de consulta, la operación de inserción requiere únicamente definir un item dentro de los parámetros [7:20]. Se eliminan las líneas relacionadas con expresiones y se usa el método .put() del cliente de DynamoDB en lugar de .query().
Para facilitar el debugging, se agrega un console.log(params.item) que permite visualizar en CloudWatch exactamente qué datos se están insertando [9:00]. La respuesta de la función devuelve params.item, lo que permite al cliente conocer el ID generado para usos posteriores.
¿Cómo probar el endpoint POST con Postman y Serverless Offline?
Antes de desplegar, se valida todo en local con el comando serverless offline start [10:10]. En Postman se configura:
- Método POST apuntando a la URL local.
- Body de tipo raw con sintaxis JSON.
- Un objeto con campos como
nombre, telefono y direccion.
Durante la primera prueba apareció un error 502 Bad Gateway con el mensaje randomUUID is not a function [12:05]. La solución fue corregir la sintaxis del import. Tras reiniciar, la petición respondió con un 200 en aproximadamente 264 milisegundos.
¿Qué es el package pattern y cómo reduce el tamaño del despliegue?
Al ejecutar serverless deploy, el paquete inicial pesaba 63 MB porque incluía DynamoDB local y todas las dependencias [14:00]. Usando la configuración de package en el serverless.yml, se empaqueta de forma individual cada Lambda y se excluyen carpetas innecesarias con el signo de exclamación:
!dynamodb/**!node_modules/**
Esto redujo el tamaño a aproximadamente 19 MB. En producción, la optimización ideal sería utilizar Lambda Layers, pero eso queda para una clase posterior [15:30].
Tras el despliegue exitoso, la prueba en la nube confirmó una respuesta 200 OK en 153 milisegundos. La validación final consistió en usar el endpoint GET con el ID recién generado para confirmar que el usuario existía en la base de datos [17:00].
Comparte una captura de pantalla de tu resultado y cuéntanos cómo se comportó tu Lambda al insertar usuarios en DynamoDB.