Desarrollo de un agente de code review con análisis paralelo
Clase 20 de 26 • Curso para Crear Agentes de AI con LangGraph
Contenido del curso
El Núcleo del Agente: Estado y LLMs
Lógica y Estructura de Nodos
Agentes ReAct
Grafos Avanzados y Colaboración
- 17

Enrutamiento de agentes con conditional edge en LangGraph
09:49 min - 18
Routing inteligente con LLM para derivar conversaciones automáticamente
22:14 min - 19

Paralelización de nodos en agentes con LangGraph
06:58 min - 20
Desarrollo de un agente de code review con análisis paralelo
Viendo ahora - 21
Patrón orchestrator para selección dinámica de nodos en paralelo
16:31 min - 22
Evaluator Optimizer: ciclos de autocrítica para agentes de IA
12:48 min
Puesta en Producción
Resumen
Diseña un flujo de revisión de código sólido y rápido con un agente especializado que ejecuta análisis en paralelo. Con un patrón de paralelización, dos revisores independientes detectan vulnerabilidades y problemas de mantenibilidad, y un tercer nodo agrega los hallazgos en un informe final claro. Aquí verás cómo se define el estado tipado, cómo se usan structured output y schema, y cómo se orquestan los nodos para ganar tiempo sin perder calidad.
¿Cómo funciona el agente de code review con patrón de paralelización?
El objetivo es ejecutar revisiones simultáneas sobre un mismo fragmento de código y consolidarlas en un resultado único. No es conversacional: recibe código, lo analiza y devuelve un reporte.
¿Qué flujo sigue el estado y los nodos?
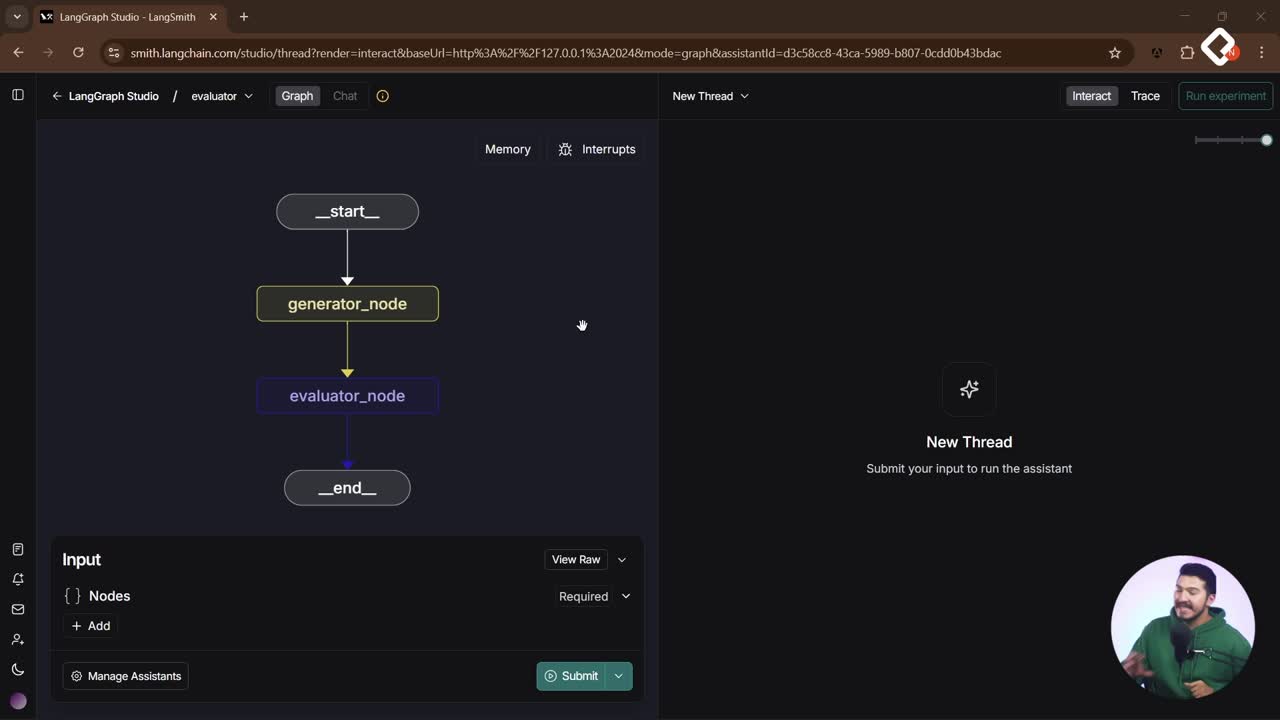
- Se define un estado con el código de entrada y los espacios para los resultados parciales y finales.
- Desde el nodo inicial se lanzan en paralelo: security review y maintainability review.
- Ambos resultados llegan al nodo aggregator, que sintetiza y deja el informe final en el estado.
- La interfaz muestra líneas fijas: inicio ejecuta ambos nodos en paralelo, luego el aggregator y el final. En otros flujos (por ejemplo, con React o tools), algunas transiciones son opcionales o exclusivas, pero aquí son simultáneas por diseño.
¿Qué roles cubren security review y mantenibility review?
- Security review: detecta vulnerabilidades, inyección, riesgos y sugiere mitigaciones.
- Maintainability review: evalúa legibilidad, estructura, buenas prácticas y calidad del código.
- Ambos escriben en el estado usando formatos definidos por schema para facilitar el parsing y la agregación.
¿Qué hace el aggregator para el informe final?
- Lee los dos schemas del estado y produce un resumen accionable.
- Puede generar texto libre (sin structured output) cuando el objetivo es un reporte legible para el usuario.
- Recomienda acciones claras: sanitización de entradas, restricciones de API, tipado, nombres más expresivos, entre otras.
¿Cómo se definen el estado y el structured output del agente?
El estado es la columna vertebral: organiza entradas, salidas parciales y el reporte final. Usar structured output tipa cada nodo y mejora la consistencia del resultado.
¿Qué contiene el estado tipado del proceso?
- code: el fragmento de código a revisar.
- security_review: resultado del revisor de seguridad según su schema.
- maintainability_review: salida de mantenibilidad con su schema.
- final_review: texto del informe consolidado para el usuario.
¿Cómo se usa structured output y schema en los nodos?
- Security review define un schema con: lista de suggestions de vulnerabilidades, risk level y suggestions descriptivas.
- Maintainability review define: concerns sobre el código, code quality en escala de 1 a 10 y recomendaciones de mejora.
- Se menciona el uso de “Pandantic” para tipar los resultados: el LLM devuelve datos ya estructurados, listos para inyectarse en el estado sin post-processing complejo.
¿Qué modelo LLM y prompts se emplean?
- Modelo: OpenAI GPT-4-4.1 mini.
- Mensajería: system message y user message definidos con tuplas para simplicidad.
- Ejemplo de instrucción al usuario: “review this code” junto al código fuente.
- Recomendación: ampliar el prompt (no de una sola línea) para mejorar calidad, controlar inyección y, si conviene, usar formatos como XML para guiar la salida.
¿Cómo se implementa y prueba el flujo en paralelo?
El desarrollo prioriza agilidad: un archivo único llamado codereview, sin scaffolding complejo, útil para prototipado. Para proyectos grandes, conviene dividir prompts y nodos en carpetas.
¿Cómo se invocan los nodos con system message y user message?
- Cada nodo recibe el código desde el estado inicial.
- Se prepara el system message con el rol experto: seguridad o calidad.
- Se invoca el LLM con structured output y su schema correspondiente.
- Se guarda solo la parte del estado que cambió para mantener el flujo limpio.
¿Qué se observa en Landgraf Studio durante la ejecución?
- Los dos nodos corren en paralelo y escriben sus resultados.
- El aggregator crea un reporte final legible con acciones priorizadas.
- El estado registra: vulnerabilidades medias con su lista, preocupaciones de mantenibilidad, puntuación de calidad y recomendaciones claras.
- Aunque no hay chat como tal, el estado concentra toda la evidencia del proceso.
¿Qué mejoras y reto final se proponen?
- Añadir un tercer revisor: performance para evaluar optimizaciones de rendimiento.
- Mejorar prompts: versiones extensas, con instrucciones, formato de salida y manejo de riesgos.
- Escalar la arquitectura: separar archivos por nodos y prompts cuando el proyecto crezca.
¿Te animas a implementar el revisor de performance y a pulir los prompts? Comparte tus resultados y aprendizajes en los comentarios.