Un agente eficaz no sigue un guion fijo: se adapta, decide y ejecuta lo imprescindible para resolver la tarea. Aquí aprenderás cómo el patrón orchestrator permite elegir dinámicamente qué nodos correr, cuándo hacerlo en paralelo y cómo sintetizar una única respuesta final con un aggregator.
¿Qué es el patrón orchestrator y por qué supera la paralelización y el routing?
El objetivo del patrón es claro: seleccionar de forma dinámica los nodos a ejecutar según el contexto y correrlos en paralelo solo cuando haga falta. A diferencia de otros patrones:
En paralelización, siempre se ejecutan todos los nodos.
En routing, se ejecuta uno u otro, nunca varios a la vez.
En orchestrator, la selección es dinámica: uno, dos o tres, según la decisión del motor.
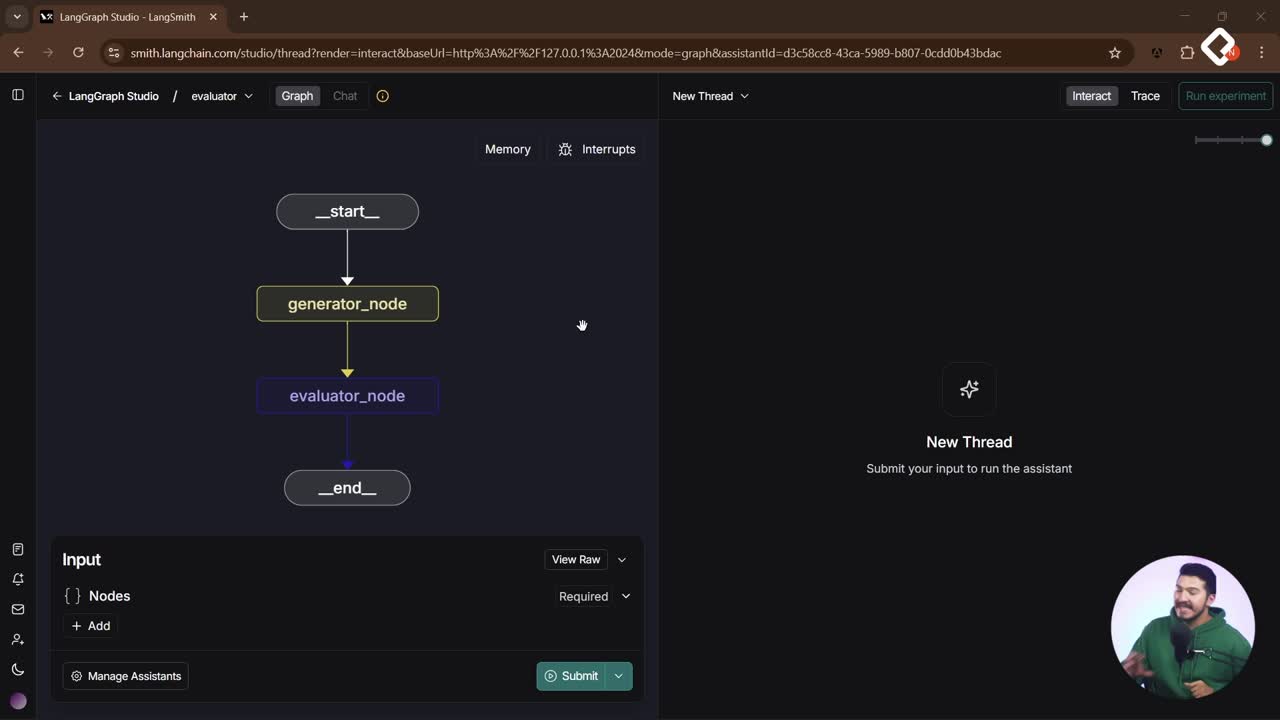
Esta decisión puede apoyarse en AI, el historial o reglas. El flujo típico: selección de nodos, ejecución en paralelo de los elegidos y síntesis con un aggregator. La estructura de salida y el historial ayudan a que el motor tome decisiones consistentes.
¿Cómo decide qué nodos ejecutar?
La decisión puede estar guiada por un large language model, reglas o incluso algo aleatorio para ilustrar el concepto. Lo importante es que el orchestrator actualiza el estado con los nodos seleccionados y esos se lanzan en paralelo. El orden de inicio puede variar y el de finalización también, por lo que el aggregator debe consolidar solo los resultados presentes y generar un summary robusto.
Usa historial para identificar subtareas y prioridades.
Emplea structured output para marcar qué agentes se requieren.
Ejecuta en paralelo solo los nodos elegidos.
Agrega resultados con un aggregator en una sola respuesta.
¿En qué ayuda HuggingGPT con el task planning?
Como inspiración, se emplea la idea de HuggingGPT para descomponer un request y asignar el mejor modelo por paso. Flujo típico:
Task planning: dividir la solicitud en subtareas.
Selección de modelos por subtarea.
Task execution: correr cada modelo.
Aggregator y response generation: integrar respuestas en una única salida.
Ejemplos comentados: describir una imagen y contar objetos, o generar una imagen con la pose de otra y luego describirla con voz. El orchestrator replica esta lógica: divide, elige modelos, ejecuta en paralelo y sintetiza.
¿Cómo implementarlo con send y una función asignar nodos?
Se parte de un template que hoy imita paralelización (siempre corre nodo 1, 2 y 3). El ajuste clave es mover la decisión al orchestrator para que elija qué nodos ejecutar y luego los dispare en paralelo con el comando send.
¿Cómo preparar el estado y actualizar los nodos?
El orchestrator decide y guarda en el estado la lista de nodos a ejecutar. Para ilustrar la idea se puede usar un criterio aleatorio; en producción, la decisión puede venir de un LLM con structured output y el historial.
import random
deforchestrator(state:dict)->dict:# Ejemplo pedagógico: decisión aleatoria de qué nodos correr posibles =[["nodo_1"],["nodo_2"],["nodo_3"],["nodo_1","nodo_2"],["nodo_2","nodo_3"],["nodo_1","nodo_3"],["nodo_1","nodo_2","nodo_3"]] elegidos = random.choice(posibles) state["nodos"]= elegidos
return state # el orquestador actualiza el estado con los nodos elegidos
Puntos clave:
El estado conserva la lista de nodos a ejecutar.
La lógica de selección es intercambiable.
¿Cómo disparar ejecuciones en paralelo con send?
El edge de asignación lee el estado y envía, con send, una lista de nodos a ejecutar en paralelo. Cada envío puede llevar su propio estado.
defasignar_nodos(state:dict):# Ejecuta en paralelo los nodos seleccionados por el orquestadorreturn[ send(nodo,{})for nodo in state.get("nodos",[])]
De forma explícita, sería equivalente a:
# Ejemplo ilustrativo si se hubieran elegido los tressend("nodo_1",{})send("nodo_2",{})send("nodo_3",{})
Consideraciones prácticas:
No es routing porque pueden ejecutarse varios.
No es paralelización fija porque la lista es dinámica.
El aggregator debe consolidar solo los resultados disponibles.
¿Cuándo aplicarlo en customer support y tareas multimodales?
En soporte, si el usuario pide dos cosas a la vez, por ejemplo: consejos para optimizar el sitio y agendar una cita con el doctor Pérez, el orchestrator podría lanzar en paralelo el agente de conversación y el de reservas, y luego unificar la respuesta. Aun así, se recomienda en soporte guiar a una sola tarea por turno, especialmente si se integra con canales como WhatsApp.
Dónde brilla el patrón:
Solicitudes largas con múltiples subtareas en un solo mensaje.
Casos multimodales: imagen, pose, voz y texto en cadena.
Escenarios donde distintas herramientas o nodos deben coordinarse.
¿En qué otros escenarios aplicarías un orchestrator para ganar velocidad y claridad? Comparte ideas y casos que te gustaría explorar.