El aprendizaje supervisado es el corazón del machine learning aplicado: con datos etiquetados, modelos y buenas prácticas, permite predecir números o clasificar categorías en finanzas, medicina, automoción y más. Aquí verás cómo funciona, cuándo usar regresión o clasificación, qué algoritmos considerar y por qué la calidad de datos y la ética no son negociables.
¿qué es el aprendizaje supervisado y cómo funciona?
El enfoque es simple y poderoso: aprender de ejemplos etiquetados para generalizar a casos nuevos. Igual que aprender a conducir con señales claras, un “profe” guía al modelo corrigiendo errores. Como resume Hands-On Machine Learning: recoges datos, entrenas y predices.
¿cuál es el proceso paso a paso?
- Definir con claridad qué se quiere predecir.
- Recolectar datos de calidad con etiquetas confiables.
- Entrenar el modelo con esos datos.
- Probar qué tan bien funciona.
- Usarlo para predecir sobre datos nuevos.
¿por qué “garbage in, garbage out” importa?
- Si los datos están mal, el resultado será malo.
- Sesgos, errores o incompletitud contaminan el modelo.
- La fuente y la forma de etiquetar importan tanto como el algoritmo.
¿qué exige el despliegue en producción?
- Monitorear porque el modelo aprende de lo que ve.
- Actualizar si cambian las condiciones y no estaban en el entrenamiento.
- Validar continuamente desempeño y deriva.
Habilidades clave: definir objetivos de predicción, gestionar datos etiquetados, evaluar y monitorear modelos, y diagnosticar sesgos.
¿cuándo usar regresión y clasificación en problemas reales?
Hay dos grandes familias de tareas:
¿qué es regresión y para qué sirve?
- Predecir un número continuo.
- Ejemplos: precio de una casa, temperatura de mañana, ventas del próximo mes.
- Casos reales: Netflix predice si te gustará una película con “cuatro punto dos” estrellas. Bancos estiman cuánto puede pedir un cliente. En medicina, ajustar la dosis de un fármaco. En automoción, el consumo de gasolina. En agricultura, rendimiento de cosechas.
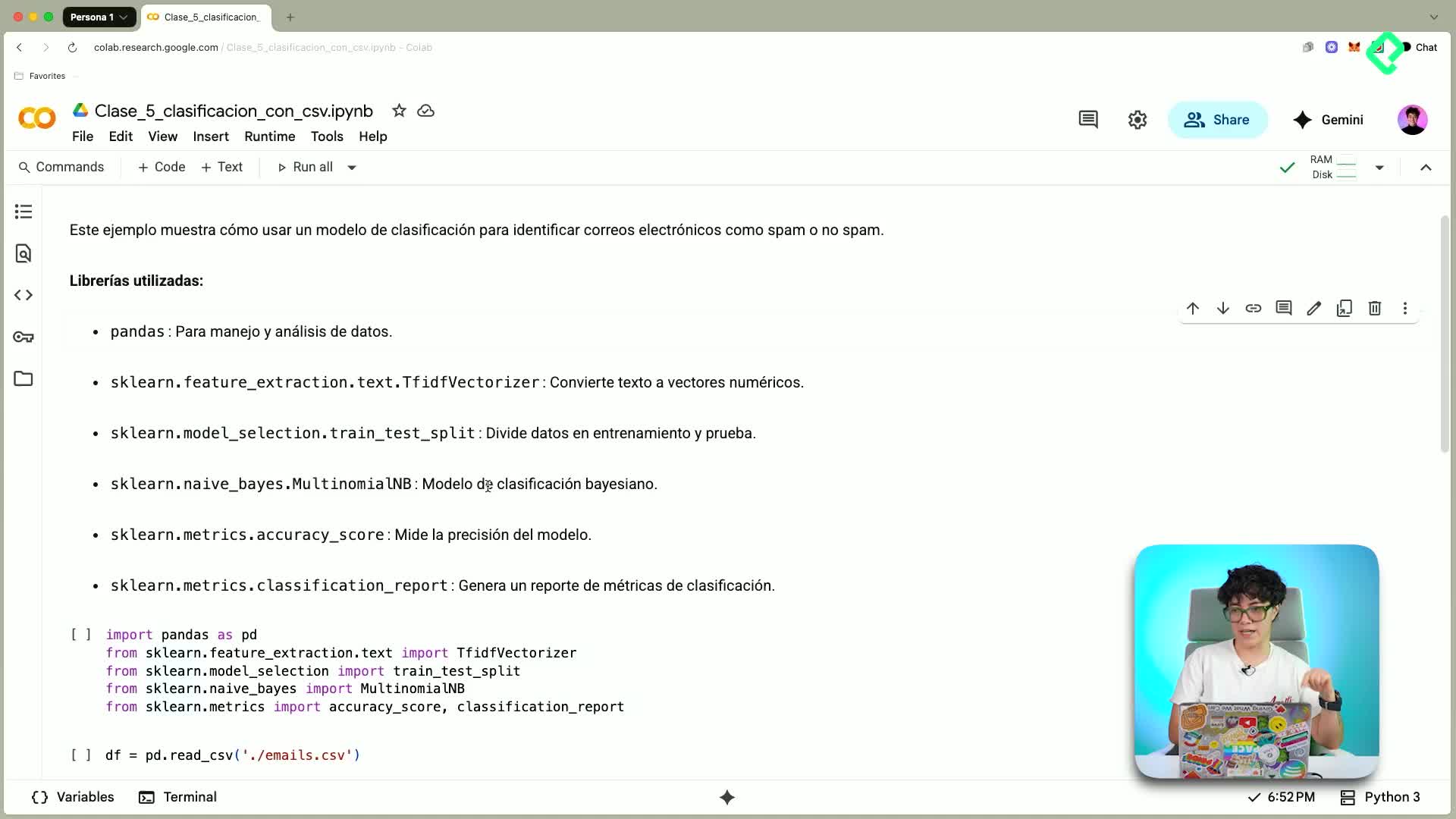
¿qué es clasificación y para qué se usa?
- Predecir una categoría.
- Ejemplos: ¿spam o no spam?, ¿gato o perro?
- Casos reales: Gmail separa promociones o social. Bancos deciden aprobar o no un crédito. En medicina, detectar enfermedades en estudios clínicos. En automoción, señales de falla de sensores. En agricultura, detectar enfermedades en cultivos.
¿qué hace realmente potente al aprendizaje supervisado?
- Encuentra patrones sutiles que a veces los humanos no ven.
- Ejemplo citado: indicadores en electrocardiogramas que anticipan problemas cardíacos.
- Como resalta Kevin Murphy en Machine Learning: A Probabilistic Perspective: si existe relación entre entradas y salida, el modelo debe descubrirla con datos.
Keywords esenciales: regresión, clasificación, etiquetas, predicción, patrones, datos de calidad.
¿qué algoritmos elegir y qué riesgos éticos considerar?
La elección depende de datos, complejidad, necesidad de explicación y tiempo de entrenamiento. No hay un modelo que gane siempre: el No Free Lunch Theorem lo deja claro.
¿qué algoritmos son más comunes?
- Para regresión: regresión lineal, árboles de decisión, random forest, redes neuronales.
- Para clasificación: regresión logística, Naive Bayes, máquinas vectoriales de soporte (support vector machines), redes neuronales.
¿cómo decidir con criterio?
- ¿Cuántos datos tienes y con qué calidad?
- ¿Qué tan complejo es el problema?
- ¿Necesitas alta explicabilidad o máxima precisión?
- ¿Cuál es tu presupuesto de tiempo de entrenamiento y mantenimiento?
¿qué dilemas éticos no puedes ignorar?
- Sesgo en datos, sesgo en modelo: si un sistema de selección se entrena con historial discriminatorio, perpetúa desigualdades.
- Privacidad: entrenar modelos puede requerir datos personales; pregunta qué usar y cómo proteger.
- Transparencia y monitoreo: valida impacto y corrige sesgos con ciclos de revisión.
Contexto actual: el aprendizaje supervisado convive con enfoques no supervisados y reforzados. Modelos como GPT se entrenaron con métodos supervisados a gran escala, y hoy emergen híbridos que combinan técnicas.
¿Te gustaría aportar un caso de uso o una duda sobre tu conjunto de datos y objetivos de predicción? Comparte en comentarios.