Cómo la IA genera endpoints desde OpenAPI
Contenido del curso
Herramientas y Validación de APIs
- 5

Validación automática con Express OpenAPI Validator
07:19 min - 6

Validación automática con OpenAPI en Express
13:53 min - 7

Múltiples respuestas HTTP en OpenAPI
04:10 min - 8
Cómo la IA genera endpoints desde OpenAPI
Viendo ahora - 9
Esquemas reutilizables de productos en OpenAPI
09:15 min - 10
Endpoints de productos con esquemas reutilizables
05:36 min - 11
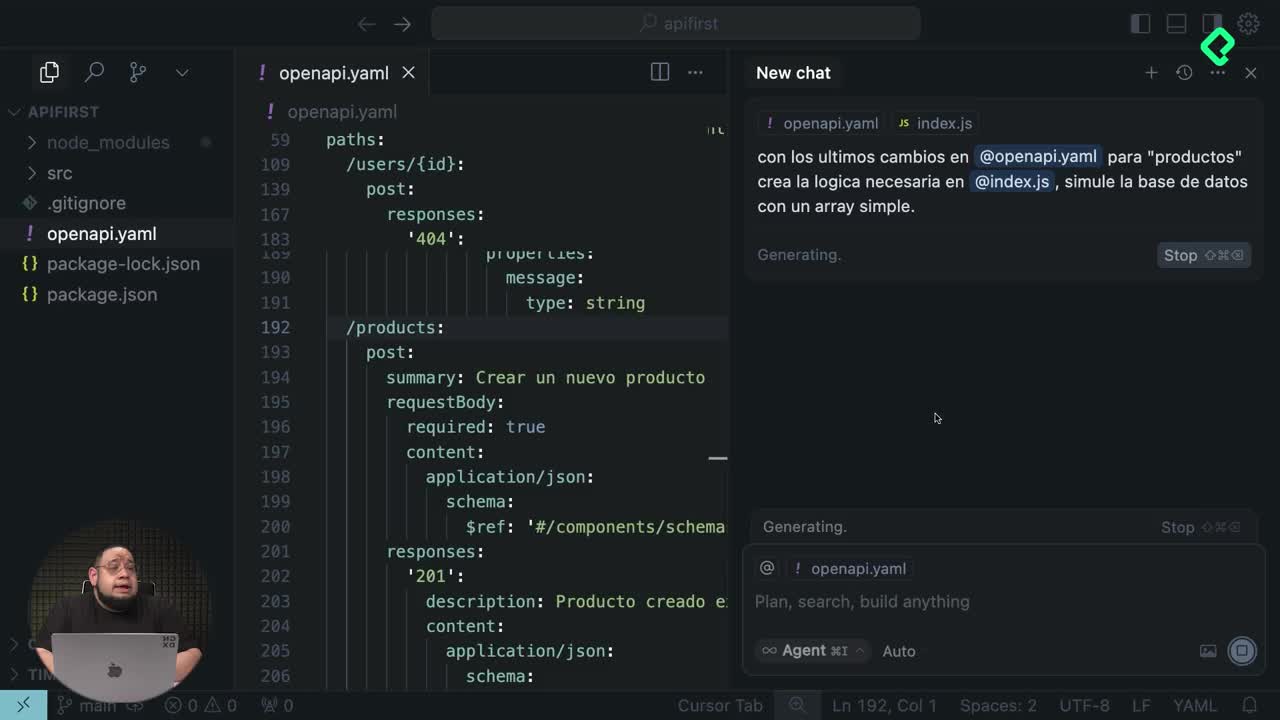
API First con IA: construye CRUD sin codificar
14:52 min
Versionado, Prototipado y Documentación
Validación y Pruebas de Contratos
Seguridad
Cómo la IA genera endpoints desde OpenAPI
Resumen
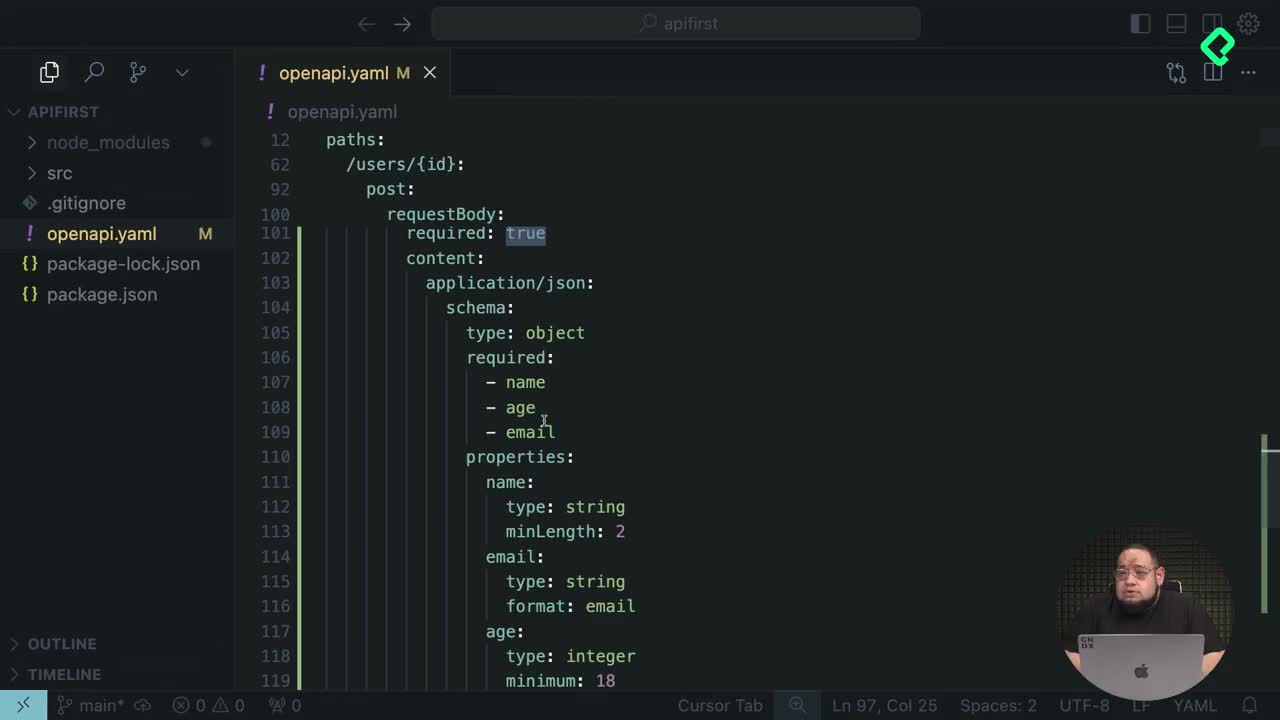
Diseñar una API antes de escribir código en Express es posible cuando defines el contrato en OpenAPI y dejas que la inteligencia artificial traduzca esa especificación a código funcional. Aquí verás cómo construir y probar endpoints para obtener y actualizar usuarios por ID, respetando reglas de validación declaradas en el archivo openapi.json.
¿Cómo definir un endpoint POST en OpenAPI antes de codificar?
El reto inicial pedía documentar el método para actualizar un usuario por ID dentro del archivo OpenAPI antes de tocar Express. Esa práctica fija el contrato y evita ambigüedades cuando la herramienta de IA genere el código.
La especificación necesitaba estos elementos clave:
- Un parámetro
idmarcado como requerido, con su tipo de dato definido. - Un request body obligatorio con la información a actualizar del usuario.
- Un esquema con campos
name,ageyemail, donde el nombre tiene mínimo 2 caracteres, el correo cumple formato email y la edad mínima es 18. - Respuestas tipadas:
200con el usuario actualizado (id, name, age, email) y404cuando el usuario no existe.
¿Qué es un request body en OpenAPI? Es el bloque de datos que el cliente envía al servidor en operaciones como POST o PUT. En este caso contiene los campos del usuario que quieres actualizar y puede marcarse como requerido para que la API rechace peticiones vacías.
¿Cómo generar el código de Express desde la especificación con IA?
Una vez que el contrato vive en openapi.json, basta con seleccionar el bloque de users y pedirle a la herramienta de inteligencia artificial que construya el endpoint en index.js cumpliendo las reglas de OpenAPI. El prompt apunta directamente a la línea donde se declara el punto de entrada /users/{id} para que la IA tenga contexto completo.
El resultado generado incluye varias piezas:
- Una simulación de base de datos con un array en memoria.
- Un endpoint GET
/users/:idque convierte el parámetro a entero y busca al usuario. - Una validación que responde
404cuando el usuario no existe. - Un endpoint PUT (o POST según el diseño) que localiza al usuario, aplica el update y devuelve el JSON actualizado.
Un detalle a tener presente es que la validación del esquema ocurre a nivel API, pero también necesitas verificar la existencia del usuario en tu fuente de datos, que aquí es solo un array en memoria.
¿Por qué revisar el código que entrega la IA?
El mismo prompt puede dar resultados distintos si cambias valores o si la indicación no es clara. Por eso conviene leer línea por línea lo que la herramienta propone, confirmar que respeta el contrato y ajustar lo que haga falta. Si quieres mejorar tus instrucciones, el curso de Prompt Engineering en Platzi profundiza en esa habilidad.
¿Cómo simular la base de datos para probar la API?
Como el foco está en el diseño desde OpenAPI y no en la persistencia, la solución usa un array con usuarios precargados que cumplen el esquema: un id, un nombre, una edad mayor a 18 y un correo válido. Esa estructura permite probar los endpoints sin levantar un motor de base de datos.
Entre los usuarios de prueba aparece María García con id 2, que sirve para validar tanto la lectura como la actualización.
¿Cómo probar los endpoints en Swagger?
Con el servidor corriendo y sin errores en la terminal, la documentación generada por Swagger muestra los dos recursos listos: obtener un usuario por ID y actualizar uno por ID. Desde ahí puedes ejecutar peticiones reales contra la API.
Estas son las pruebas que confirman que el contrato se cumple:
- GET con id
1devuelve solo el id y el nombre, tal como definiste en la respuesta200del OpenAPI. - GET con id
20responde404con el mensaje de usuario no encontrado. - PUT con id
2enviando un payload válido actualiza a María García por el nuevo valor y la siguiente lectura confirma el cambio en memoria. - PUT con id
1enviando un nombre de solo tres caracteres devuelve400 Bad Requestporque rompe la regla de longitud mínima.
¿Qué diferencia hay entre un 400 y un 404 en una API REST? Un
400indica que la petición está mal formada o no cumple las reglas de validación, como un nombre demasiado corto. Un404significa que el recurso solicitado no existe, por ejemplo un usuario con id 20 que no está en la base de datos.
La lógica de validación queda lista sin haber escrito reglas manuales en Express: la especificación OpenAPI dicta el comportamiento y la IA lo traduce a código que respeta esos límites. ¿Qué endpoint vas a documentar primero en tu próximo proyecto?