Aprender a usar local storage con vibe coding te permite agregar persistencia a una aplicación de hábitos sin perder buenas prácticas. Esta guía te muestra cómo guiar a la IA con prompts detallados, aplicar el repository pattern y revisar el código generado para evitar deuda técnica.
¿Qué es el vibe coding y por qué revisar el código generado?
El vibe coding es la práctica de delegar implementaciones a una IA como Cursor, Gemini o Claude, guiándola con prompts en lugar de escribir cada línea manualmente. Suena cómodo, pero tiene una regla de oro.
¿Cuál es la regla de oro del vibe coding? Nunca copies ni implementes código que no entiendas. Si tú no lo comprendes, nadie en tu repositorio lo hará y vas a generar deuda técnica rápido.
Hoy se están creando productos a punta de IA generativa sin entender qué pasa por detrás. Tú, como desarrollador, revisa siempre lo que sugiere Copilot o Cursor antes de aceptarlo. Si algo no te cuadra, pregúntale a la propia IA por qué llegó a esa decisión [2:00].
¿Por qué usar local storage en vez de una base de datos?
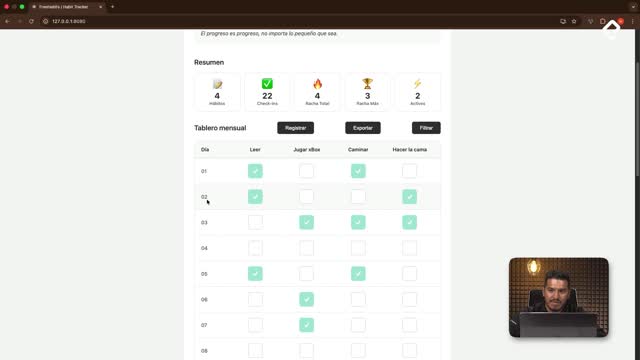
En una aplicación real lo ideal es tener un backend con una base de datos como MySQL. Pero mientras llegas a ese punto, local storage es una persistencia del navegador que sobrevive a recargas y hard reloads, perfecta para prototipos [4:30].
No es la mejor opción a largo plazo, pero te sirve para practicar antes de conectarte con APIs o equipos de backend.
¿Cómo escribir un buen prompt para implementar persistencia?
Un prompt vago como “implementar persistencia” no sirve. Entre más conceptos de arquitectura y buenas prácticas le des a la IA, mejor será el resultado. El modelo lee tu archivo completo como contexto, así que si tu código ya tiene buenas prácticas, las va a seguir; si tiene malas, también [6:00].
Un primer intento típico sería algo como “implementar local storage en App.js”. Funciona, pero deja muchas decisiones al modelo.
¿Qué pasa cuando el prompt es muy general?
En la primera iteración, Cursor agregó serialización con toJSON, modificó el constructor del habit para recibir un objeto options con el ID y persistió cada cambio dentro del click handler. La solución funciona, pero introduce un patrón options que rompe la consistencia del constructor original [10:30].
¿Por qué la IA agregó un parámetro options al constructor? Para mantener la identidad del hábito entre sesiones. Si recargas, no quieres que se genere un nuevo ID con createID, sino reutilizar el que viene de local storage.
Trata siempre la primera versión como un draft. Léela, identifica qué no te gusta y decide si iteras encima o haces rollback para empezar con un prompt mejor.
¿Cómo aplicar el repository pattern con IA?
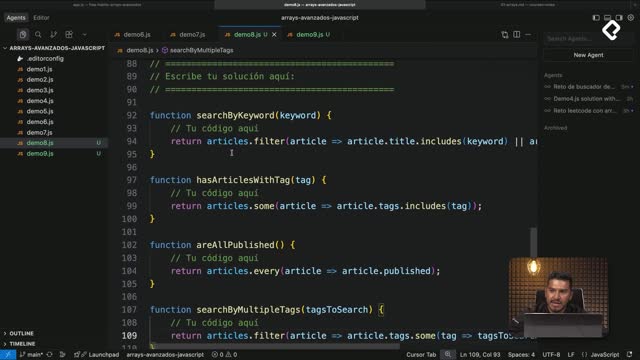
El repository pattern es un patrón de programación orientada a objetos que te permite cambiar la fuente de datos (memoria, local storage, IndexedDB, una API) sin tocar la lógica de negocio. Lo verás muy usado en ORMs como TypeORM, donde un mismo repositorio puede hacer save, find o remove contra distintas fuentes [14:00].
¿Cómo se ve un prompt detallado y bien guiado?
Después del rollback, el prompt mejorado le pide a la IA tres cosas concretas:
- Crear un nuevo
LocalStorageHabitRepository siguiendo el patrón del InMemoryHabitRepository ya existente.
- Mantener el principio open-closed de SOLID, para que agregar IndexedDB o una API en el futuro no rompa nada.
- Recibir el
id como tercer parámetro del constructor de Habit; si llega null, ejecutar createID.
Este prompt funciona porque tú ya conoces los patrones. Sin esa base, jamás llegarías a pedirlo así.
¿Qué es el principio open-closed? Es uno de los principios SOLID: tu código debe estar abierto a extensión pero cerrado a modificación. Agregar una nueva fuente de datos no debería obligarte a reescribir las existentes.
¿Qué cambió en la segunda iteración del código?
Con el prompt detallado, la implementación quedó mucho más limpia [18:00]:
- El
id entra como tercer parámetro del constructor, sin objetos options raros.
- Se creó un
LocalStorageHabitRepository independiente que serializa con JSON.stringify y deserializa con JSON.parse usando map.
- La sincronización con el storage se movió al
HabitService, evitando programación imperativa dentro de los click handlers.
- Cambiar de
InMemoryHabitRepository a LocalStorageHabitRepository es una sola línea.
Al probar en el navegador creando hábitos como hacer la tarea, leer un libro y cocinar, los datos sobreviven al cerrar la pestaña y abrir una nueva. La persistencia quedó funcional [21:30].
¿Qué alternativas tienes si no usas Cursor?
Si no tienes acceso a un IDE con IA integrada, puedes usar Gemini, ChatGPT o Claude adjuntando tus archivos como contexto. Gemini tiene una capa gratuita amplia y modelos de thinking bastante competentes [23:00].
En una prueba con Gemini usando el mismo prompt, la IA generó una clase abstracta HabitRepository de la que otros repositorios extienden con extends. Es un contrato común que obliga a todos los repositorios a implementar los mismos métodos, una práctica excelente de orientación a objetos.
Probar el mismo prompt en distintos modelos te enseña dónde difieren y cuál se adapta mejor a tu estilo. ¿Tú con cuál modelo te llevas mejor para este tipo de refactors? Cuéntame en los comentarios.