Las comprensiones en Python permiten escribir código más claro y conciso para procesar listas, diccionarios y sets. Aquí verás cómo extraer fuentes únicas y cómo categorizar artículos por su fuente usando set, list comprehension y dict comprehension. El enfoque prioriza legibilidad, evitar duplicados y menos código sin cambiar la lógica.
¿Cómo extraer fuentes únicas con set comprehension en Python?
Usar un set es ideal para mantener valores únicos. Primero, se construye con bucles tradicionales y luego se refactoriza a una comprensión que condensa el for y el if en una sola expresión.
¿Por qué usar un set para evitar duplicados?
Un set no admite duplicados y simplifica la deduplicación automáticamente.
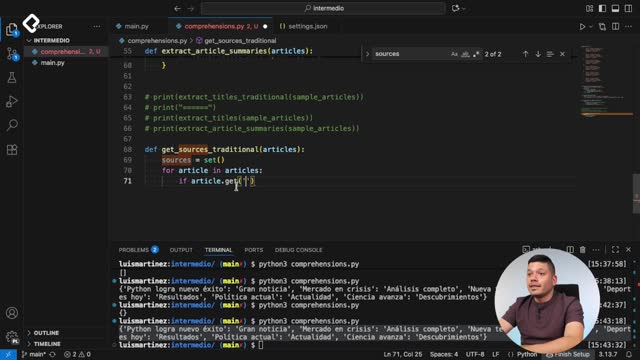
Con article.get('source') y luego .get('name') se valida la existencia de claves.
La inserción es directa: usar add con el nombre de la fuente.
# versión tradicionaldefget_sources_traditional(articles): sources =set()for article in articles: source = article.get('source')if source and source.get('name'): sources.add(source['name'])return sources
¿Cómo se ve el refactor con comprensión?
La expresión define qué guardar: el nombre de la fuente.
El for recorre cada artículo.
El if filtra solo los artículos con fuente y nombre válidos.
# versión con set comprehensiondefget_sources(articles):return{ a['source']['name']for a in articles
if a.get('source')and a['source'].get('name')}
Validar resultados con print ayuda a comprobar que ambos devuelven lo mismo.
Si el set de pruebas contiene fuentes repetidas, el set mostrará cada una una sola vez.
¿Cómo categorizar artículos por fuente con comprensiones anidadas?
Muchas veces se requieren iteraciones anidadas: recorrer fuentes y, por cada una, recorrer artículos para agruparlos. Se muestra primero el patrón tradicional y luego la versión con dict y list comprehension anidadas.
¿Cuál es la versión con bucles tradicionales?
Se prepara un diccionario results con cada fuente como llave.
Se inicializa cada llave solo si no existe.
Se agrega el artículo a la lista correcta con append cuando coincide la fuente.
# versión tradicionaldefcategorize_traditional(articles): sources = get_sources(articles) results ={}for source in sources:if source notin results: results[source]=[]for article in articles: art_source = article.get('source') name = art_source.get('name')if art_source elseNoneif name == source: results[source].append(article)return results
¿Cómo queda la versión con dict y list comprehension?
La llave del diccionario es cada fuente.
El valor es una lista de artículos filtrados por esa fuente.
Se reduce código sin perder claridad.
# versión con comprensiones anidadasdefcategorize(articles):return{ source:[ article
for article in articles
if article.get('source')and article['source'].get('name')== source
]for source in get_sources(articles)}
Al imprimir ambas versiones, los resultados deben ser equivalentes.
La comprensión evita inicializaciones manuales en cada iteración.
¿Qué buenas prácticas mejoran legibilidad y rendimiento?
Refactorizar a comprensiones funciona mejor cuando mantiene la intención del código clara y reduce ruido. Estas pautas se destacan en el flujo mostrado.
Usa comprensiones cuando el patrón sea “mapear y filtrar” en una sola línea.
Emplea .get para evitar errores si faltan claves en diccionarios.
Elige set cuando necesites eliminar duplicados de forma natural.
Prefiere comprensiones anidadas para agrupaciones claras, en lugar de múltiples bucles.
Verifica equivalencia con print y separadores antes y después del refactor.
Si aparece una variable no definida, atiende el aviso del linter (por ejemplo, ruff) y corrige la referencia.
Asegura que las funciones importen y exporten datos correctamente tras cada refactor.
¿Tienes un ejemplo propio de agrupación o deduplicación que quieras optimizar con comprensiones? Compártelo en los comentarios y lo revisamos juntos.