¿Cómo son las derivadas en las funciones de activación?
Clase 11 de 12 • Curso Básico de Cálculo Diferencial para Data Science e Inteligencia Artificial
Contenido del curso
Límites
Derivada en ciencia de datos
Introducción a máximos y mínimos
Derivadas de funciones de activación
Conclusiones
Resumen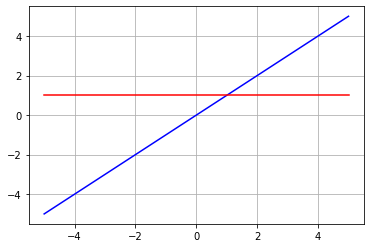
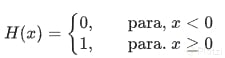
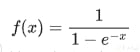 Y su derivada:
Y su derivada:
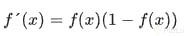
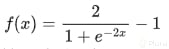
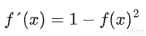
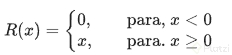 Y su derivada está dada por
Y su derivada está dada por
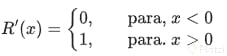 Nota: ReLu no tiene derivada en cero
Nota: ReLu no tiene derivada en cero
En este notebook de Google Colab exploramos las derivadas de distintas funciones de activación.
Derivadas de funciones de activación
Mediante la función derivada discreta que programamos en clases anteriores, podemos obtener una derivada aproximada de las funciones de activación.
def df(f): h=0.000001 return (f(x+h)-f(x))/h
Derivada de una función lineal
Las funciones lineales también pueden servir como funciones de activación de una red neuronal. Por esto es importante entender que la derivada de una función lineal es simplemente su pendiente. Es decir
""""""Sea f(x) = mx+b f'(x) = m """""" def f(x): return x plt.plot(x, f(x), 'b') plt.plot(x,df(f), 'r') plt.grid()
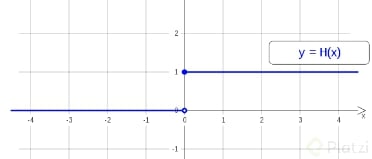
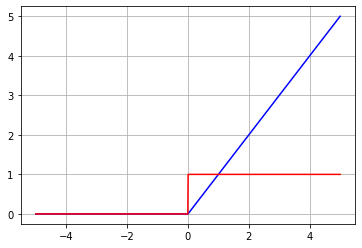
Derivada de la función de Heaviside
Recordemos que la función de Heavyside está dada por partes, de la siguiente forma:
Si vemos la gráfica de la función, nos damos cuenta que para x=0 la función ""crece"" completamente vertical hasta y=1. Es decir, la recta tangente en x=0 tiene pendiente infinita. Se puede demostrar que la derivada de la función de Heavyside corresponde a la ""Delta de Dirac"". Te invito a investigar la Delta de Dirac por tu cuenta, pero en resúmen, esta función tiende a infinito cuando x tiende a cero (en este caso), y vale cero para todos los demás valores.
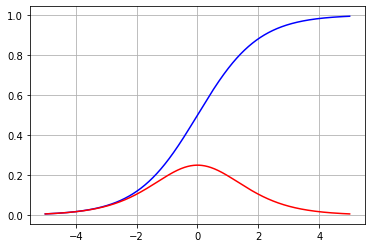
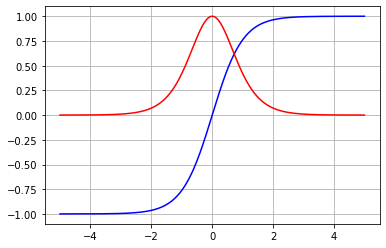
Derivada de la función sigmoide
La función sigmoide es usada tanto en redes neuronales como en regresión logística. Esta función se expresa como:
Optimizar esta función en redes neuronales puede llevar a un problema conocido como ""vanishing gradient"", debido a la complejidad de la función. Te invito a investigarlo. Por ahora, te dejo el código y el gráfico de esta función con su derivada.
def f(x): return 1/(1 + np.exp(-x)) plt.plot(x, f(x), 'b') plt.plot(x,df(f), 'r') plt.grid()
Derivada de la función tangente hiperbólica
Con esta función ocurre algo similar que con la sigmoide. La complejidad de su derivada puede causar problemas durante la optimización. La función tangente hiperbólica está dada por:
Y su derivada
Derivada de la función ReLU
La función ReLU es especialmente útil en las capas intermedias de una red neuronal, gracias a su relativa sencillez. La función ReLu está definida como $R(x)=max(0,x)$, o bien:
Conclusión
Entender estas funciones y sus derivadas nos ayudará a comprender los fundamentos necesarios para desarrollar algoritmos de machine learning y redes neuronales. Esto no se trata de una receta de cocina, y sino de pensar de manera analítica usando dichos fundamentos.
Contribución creada por Ciro Villafraz con los aportes de: Joan Blanco, RubenSH y Faustino Correa Muñoz.