Código para cargar la tabla desde R :)
urlca<-"https://countrymeters.info/es/Colombia"
paginawebca<-read_html(urlca)
selectorca<-"#population_clock > table"
nodo_tablarca<-html_node(paginawebca,selectorca)
nodo_tablarta<-html_table(nodo_tablarca)
nodo_tablarta
colnames(nodo_tablarta)<-c("Número población","Clasificación población")
View(nodo_tablarta)
Excelente aporte! con el colnames y view me quedó excelente la tabla!
Si tienen proglemas
Tuve problemas para instalar la libreria de 'rvest' en el mac porque había descargado la versión 3.3.3. Para solucionarlo tuve que cambiarme a la versión 3.6.0 para lo que hice lo siguiente:
De donde descargue el paquete
R-3.6.0.pkg para actualizar la versión.
¡Hola Jahir!, ¿pudiste "scrapear" desde Safari?, si es así, ¿cómo inspeccionaste para obtener el selector?
Hola Sebastian, desde Safari no realizó la inspección del HTML de las paginas, ese tipo de actividades las realizo desde Chrome. Pero revisando veo que lo puedes hacer con "Safari DevTools" en el siguiente enlace https://support.apple.com/es-co/guide/safari/sfri20948/mac puedes encontrar información de como usar las herramientas de desarrollo de Safari en Mac.
Saludos.
Estoy probando con una página diseñada en WordPress, pero para llegar a la url debo hacer un login antes.
Buscando documentación existe la forma de hacer login, pero al parecer Wordpress funciona de otro modo... ¿Alguna idea o ayuda?
Busca el curso de selenium, ahí dicen como se podria hacer eso.
Codigo para obtener la tabla de todas las cryptos y sus datos financieros de yahoo
Importante instalar xml2 junto con Rvest, para poder usar las funciones, como read_html
Hola,
Hice un script que extrae la información de una tabla en wikipedia con la información de los 10 terremotos de mayor magnitud en la historia reciente. El artículo del que extraje la info lo encuentran aquí
igual a mí, me aparece el mismo error en nodo para extraer los valores de la tabla
Histórico acción del petroleo en Colombia
url <-"https://cincodias.elpais.com/mercados/empresas/ecopetrol/56685/historico/"pagina_web <-read_html(url)selector <-"#carcasa-contenido > section > div > div > table > tbody > tr:nth-child(1) > td:nth-child(2)"nodo <-html_node(pagina_web, selector)nodo_texto <-html_text(nodo)nodo_texto
selector_tabla <-"#carcasa-contenido > section > div > div > table"nodo_tabla <-html_node(pagina_web, selector_tabla)nodo_tabla_texto <-html_table(nodo_tabla)nodo_tabla_texto
Extrayendo información de Amazon
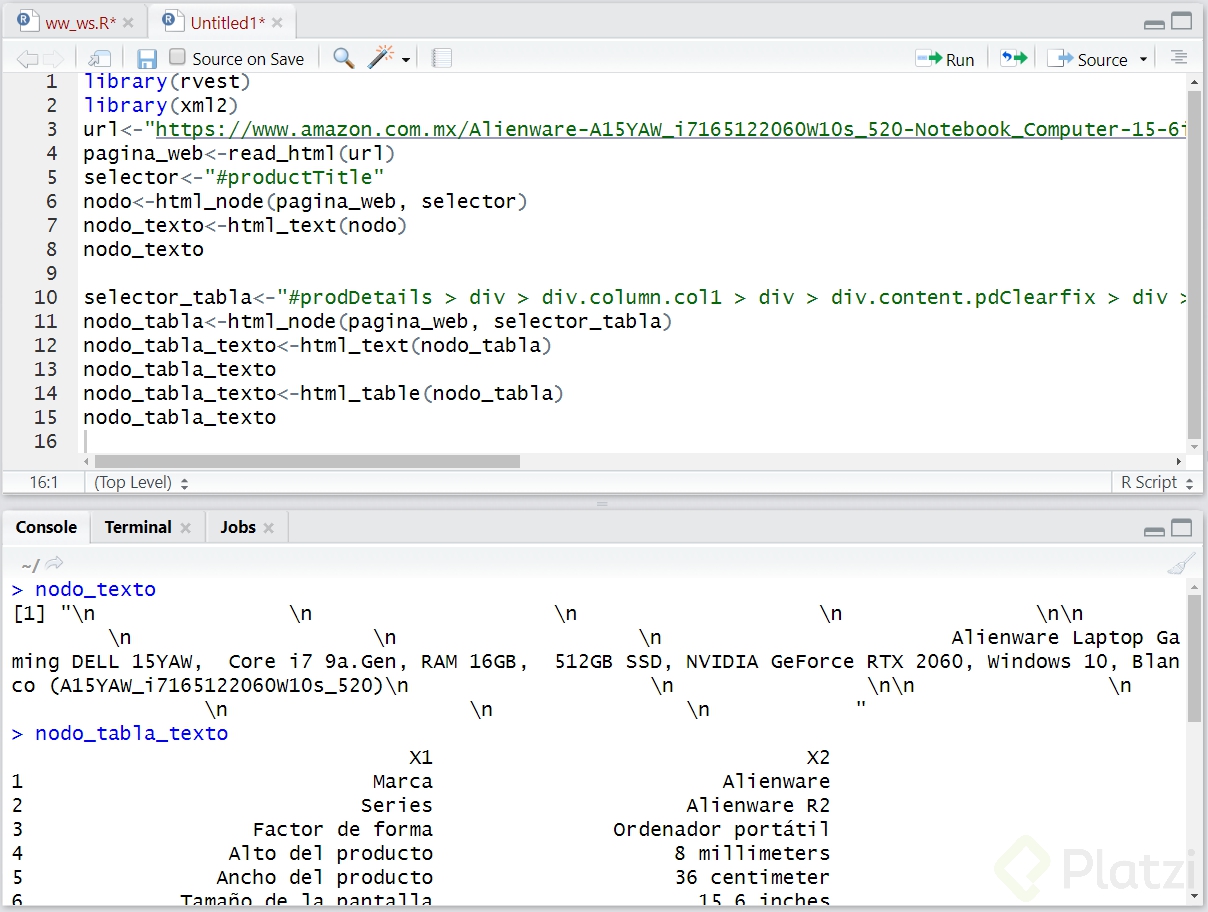
library(rvest)library(xml2)url<-"https://www.amazon.com.mx/Alienware-A15YAW_i7165122060W10s_520-Notebook_Computer-15-6inches-Core_i7/dp/B07WG3CC2J/ref=sr_1_2?__mk_es_MX=%C3%85M%C3%85%C5%BD%C3%95%C3%91&keywords=alienware&qid=1590170350&s=amazon-devices&sr=8-2"pagina_web<-read_html(url)selector<-"#productTitle"nodo<-html_node(pagina_web, selector)nodo_texto<-html_text(nodo)nodo_texto
selector_tabla<-"#prodDetails > div > div.column.col1 > div > div.content.pdClearfix > div > div > table"nodo_tabla<-html_node(pagina_web, selector_tabla)nodo_tabla_texto<-html_text(nodo_tabla)nodo_tabla_texto
nodo_tabla_texto<-html_table(nodo_tabla)nodo_tabla_texto```
Mi código para obtener la tabla de los personajes de Avengers: Edgame
#Webscraping con R- tables
url<-"https://www.imdb.com/title/tt4154796/?ref_=nv_sr_srsg_0"pagina_web<-read_html(url)selector_tabla<-"#titleCast > table"nodo_tabla<-html_node(pagina_web,selector_tabla)nodo_tabla_texto<-html_table(nodo_tabla)nodo_tabla_texto```
Que hay que hacer para hacer scraping en páginas seguras, es decir que necesitan autenticarse antes?
Me sale este error al usar la función html_node :
Error in UseMethod("xml_find_first") :
no applicable method for 'xml_find_first' applied to an object of class "character"
library(rvest)url <-"https://es.finance.yahoo.com/quote/%5EIBEX?p=^IBEX"web_site <-read_html(url)# Nombre de la accion
s_nombre <-"#quote-header-info > div.Mt\(15px\) > div.D\(ib\).Mt\(-5px\).Mend\(20px\).Maw\(56\%\)--tab768.Maw\(52\%\).Ov\(h\).smartphone_Maw\(85\%\).smartphone_Mend\(0px\) > div.D\(ib\) > h1"n_nombre <-html_node(web_site, s_nombre)nombre <-html_text(n_nombre)
Pero me sale este error:
Error:'\(' is an unrecognized escape in character string starting ""#quote-header-info > div.Mt\("
¿Me pueden ayudar por favor?
1PresidenteAño Cotización al cierre del año Promedio anual
2AndrésManuelLópez Obrador201918.864219.25743EnriquePeñaNieto201819.651219.23734EnriquePeñaNieto201719.662918.90665EnriquePeñaNieto201620.619418.68866EnriquePeñaNieto201517.248715.88107EnriquePeñaNieto201414.741413.30328EnriquePeñaNieto201313.084312.76969FelipeCalderónHinojosa201212.965813.168910FelipeCalderónHinojosa201113.947612.4301







