Aprende a dominar textos en Python con técnicas prácticas: índices base cero, slicing con fin no incluido, búsquedas seguras con normalización, y métodos esenciales como replace y split. Con estas habilidades trabajarás textos largos con precisión, evitando errores típicos al cortar, reemplazar y comparar cadenas.
¿Cómo funcionan los índices en strings de Python?
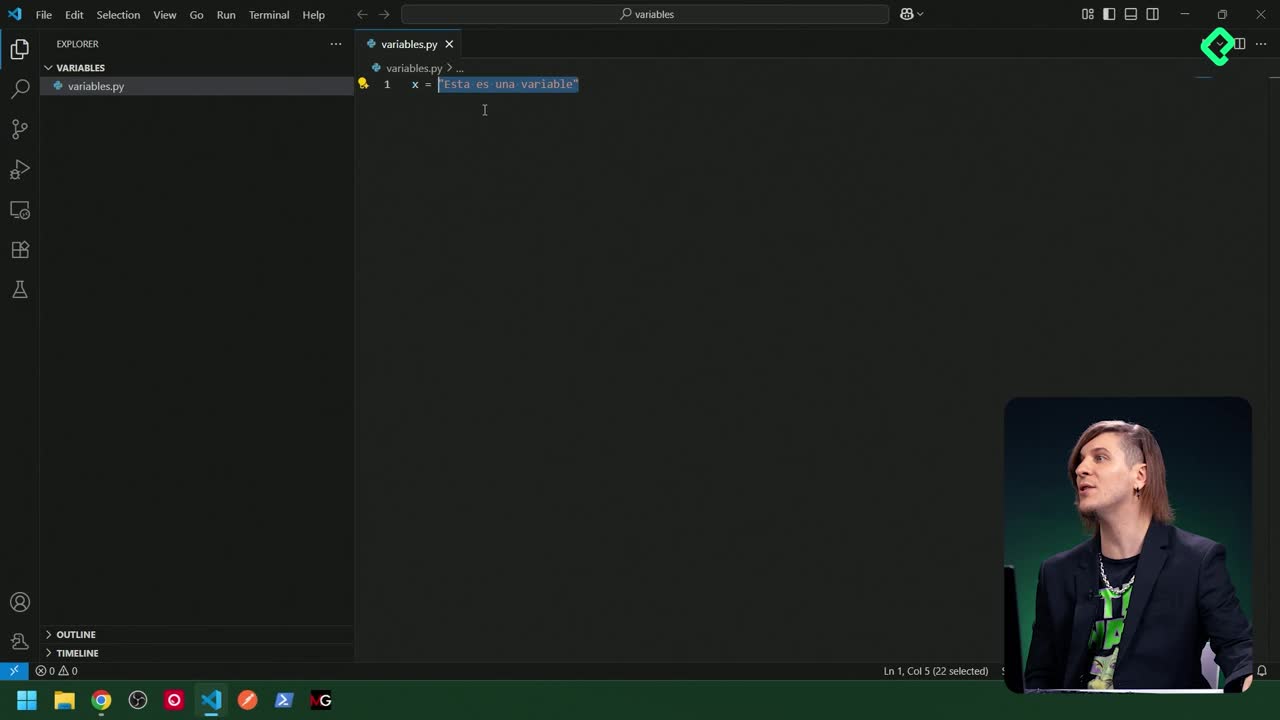
Comprender el índice es clave: en Python las posiciones comienzan en 0 y los espacios cuentan como caracteres. Acceder a un carácter se hace con corchetes.
- El primer carácter tiene índice 0.
- Los espacios y signos también ocupan posición.
- Usar print con acceso por índice muestra el carácter correspondiente.
¿Qué es indexación base cero y por qué los espacios cuentan?
- Base cero: el primer carácter es 0, no 1.
- Ejemplo práctico: la E de "Este" está en 0; el espacio tras "Este" ocupa una posición.
texto = "Este es un texto" print(texto[0]) # E print(texto[4]) # espacio
¿Cómo acceder a un carácter por índice?
- Sintaxis: cadena[indice].
- Si el índice apunta a un espacio, se imprime un espacio.
print(texto[0]) # E print(texto[4]) # ' '
¿Cómo hacer slicing para extraer partes del texto?
El slicing usa rangos [inicio:fin] donde fin no está incluido. Puedes omitir inicio o fin para tomar desde el principio o hasta el final. También puedes contar desde atrás con índices negativos.
- Fin no incluido: cuenta "uno de más" para abarcar el último carácter deseado.
- Inicio omitido: toma desde el principio.
- Fin omitido: llega hasta el final.
- Negativos: -1 es el último carácter.
¿Cómo usar rangos [inicio:fin] con fin no incluido?
- Extraer "Este": de 0 a 4 excluido.
- Si cuentas hasta el último índice visible y lo colocas en fin, ese carácter no se incluye.
print(texto[0:4]) # Este # Hasta el final contando manualmente: cuidado con la última letra print(texto[0:15]) # falta la 'o' final si 15 apunta a esa posición
¿Cómo omitir inicio o fin y usar índices negativos?
- Desde el principio hasta una posición.
- Desde una posición hasta el final.
- Usar negativos para cortar desde atrás y recordar que fin excluye.
print(texto[:7]) # "Este es" print(texto[5:]) # desde la "e" de "es" hasta el final # De la "e" de "es" hasta incluir la "x": fin como -2 para abarcar la X print(texto[5:-2])
¿Cómo reemplazar, dividir y normalizar texto en Python?
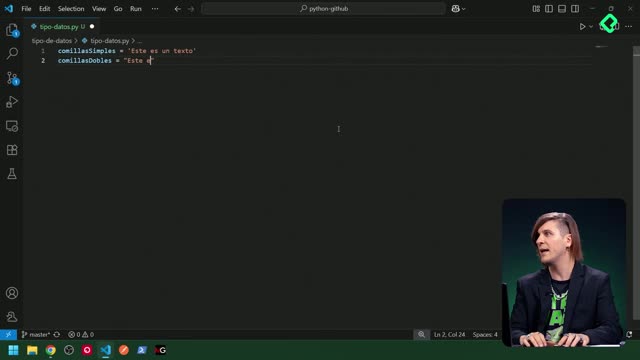
Para actualizar contenidos, separar palabras y comparar sin errores por mayúsculas/minúsculas, usa replace, split y lower. Python es case sensitive, por eso la normalización evita falsos negativos en búsquedas.
¿Cómo reemplazar con replace y cuántas veces ocurre?
- replace cambia todas las apariciones del texto objetivo.
- Útil para corregir etiquetas o tecnologías mencionadas.
curso = "Este curso es de JavaScript" print(curso.replace("JavaScript", "Python")) # "Este curso es de Python" # Si hubiera múltiples "JavaScript", las reemplaza todas
¿Cómo dividir con split para obtener una lista de palabras?
- split convierte un string en lista usando un separador.
- El espacio es un separador común, colócalo entre comillas.
texto_dividido = texto.split(" ") print(texto_dividido) # ['Este', 'es', 'un', 'texto']
¿Cómo comparar sin errores por mayúsculas y minúsculas?
- Python es case sensitive: distingue mayúsculas y minúsculas.
- Normaliza con lower (a lowercase) tanto el texto como lo buscado.
- Usa el operador in para verificar inclusión fiable.
texto2 = "Este Texto tiene MAYÚSCULAS y minúsculas" buscado = "mayúsculas" print(buscado in texto2) # False print(buscado.lower() in texto2.lower()) # True
¿Te gustaría practicar más? Comparte en comentarios tus propios ejemplos de slicing, replace, split y comparaciones con lower para que podamos revisarlos juntos.