Evaluación de trayectoria en agentes de IA
Contenido del curso
Trazabilidad
Evaluación y Monitoreo
- 6

Qué hace LangSmith más allá del tracing
03:51 min - 7

Crea tu primer dataset de evaluación en LangSmith
08:02 min - 8

Evaluación automática vs LLM as a Judge
04:40 min - 9

Evaluación de Agentes con Python en PlatziStore Agent
12:26 min - 10

Evaluación y Mejora de Agentes Virtuales en Langsmith
12:00 min - 11
Evaluación de trayectoria en agentes de IA
Viendo ahora - 12

Evaluación de Feedback en Agentes Conversacionales
07:09 min - 13

Técnicas de Observabilidad para Optimizar Inventarios en eCommerce
08:28 min
Optimización
Evaluación de trayectoria en agentes de IA
Resumen
Cuando un agente de IA crece en complejidad, su comportamiento se vuelve impredecible y deja de bastar con revisar la respuesta final. La evaluación de trayectoria de un agente mide qué pasos siguió para llegar a esa respuesta, no solo cómo luce el resultado. Es la pieza clave para validar agentes que usan herramientas y deben seguir un flujo específico.
¿Por qué evaluar la trayectoria y no solo la respuesta del agente?
Imagina dos usuarios que le preguntan lo mismo a tu agente y reciben precios distintos: 100 dólares para uno y 200 dólares para el otro. Ambas respuestas pasan los filtros estéticos, llevan emojis y suenan amables, pero una de las dos está mal. La diferencia no se ve en el output, se ve en lo que ocurrió antes de responder.
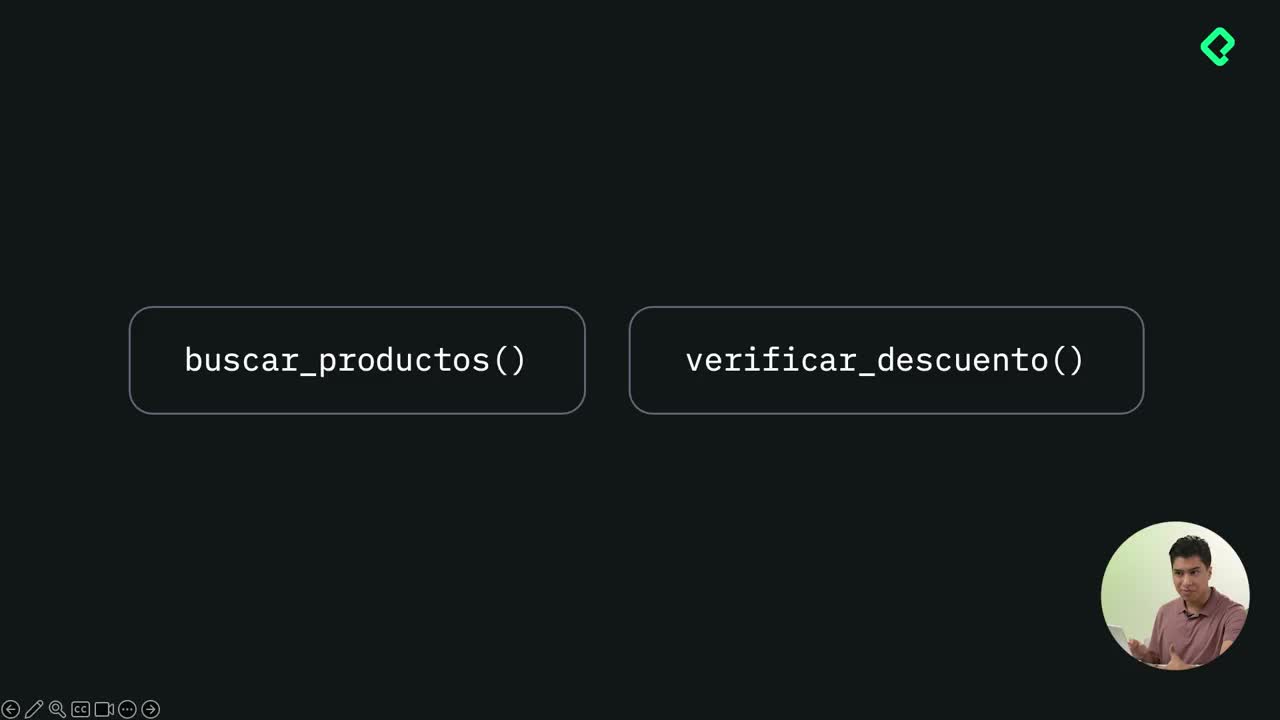
Los agentes modernos usan tools para ampliar su scope y acceder a información del mundo real. En el caso de un agente de atención al cliente de Platzi Store, hay dos funciones críticas: buscar productos y verificar descuento. El problema aparece cuando el agente, sin un refuerzo claro en el system prompt, a veces solo busca el producto y se salta la verificación del descuento [01:00].
¿Qué es la trayectoria de un agente? Es la secuencia de herramientas y pasos que ejecuta el agente para construir su respuesta. Por ejemplo: buscar productos → verificar descuento.
Ese comportamiento variable es justo lo que hay que medir. Si el usuario pregunta por dos productos, la trayectoria esperada se duplica: buscar, verificar, buscar, verificar.
¿Cómo crear un dataset de trayectoria en LangSmith?
Para evaluar trayectorias necesitas un dataset distinto al de respuestas. Cada ejemplo guarda una pregunta y una expected trajectory, no una respuesta textual.
En el archivo trajectory.py se arma así:
- Pregunta simple: "¿tienen iPhone 14?" con trayectoria esperada
[buscar_productos, verificar_descuento][02:30]. - Pregunta múltiple: "¿qué tienen de Apple, iPhone y MacBook?" con trayectoria esperada
[buscar_productos, verificar_descuento, buscar_productos, verificar_descuento]. - Mezcla de escenarios de una sola consulta y consultas múltiples para cubrir variabilidad real.
El nombre del dataset debe ser único, por ejemplo evaluación de trayectoria. Como el script se corre varias veces, conviene intentar crear el dataset primero y, si ya existe, listar los ejemplos previos por dataset_id, borrarlos y volver a crearlos con los nuevos inputs y outputs. En este caso, los inputs son la pregunta del usuario y los outputs incluyen tanto la respuesta del agente como la trayectoria de referencia.
Un detalle importante: se usa client.create_dataset(...), no client.create(...). Es uno de los errores típicos que aparecen al ejecutar el archivo por primera vez [07:30].
¿Cómo escribir una función evaluadora de trayectoria?
La función evaluadora se llama trajectory_subsequence y recibe dos parámetros: el output real del agente y el output esperado a través de reference_outputs. Aquí no importa la respuesta final, importa cuántas veces se llamó cada herramienta.
La lógica cuenta pares completos entre buscar productos y verificar descuento. Si el agente buscó una vez pero verificó cero veces, no completó el par y el score baja.
¿Qué devuelve la función evaluadora? Un float entre 0 y 1, calculado como pares completos sobre pares esperados. No es true/false, es una métrica continua que refleja qué tan cerca estuvo el agente del flujo correcto.
Esa flexibilidad permite distinguir entre un agente que falló por completo y uno que cumplió la mitad del flujo.
¿Cómo correr la evaluación y leer los resultados?
Con el dataset y la función evaluadora listos, se llama a client.evaluate pasando:
- El target:
run_agent_with_tracking. - El nombre del dataset.
- El evaluador
trajectory_subsequence. - Un prefijo identificable como
Platzi Store trajectory. - Número de repeticiones por ejemplo.
- Concurrencia hasta 4 para acelerar la corrida [06:30].
Al ejecutar trajectory.py y abrir LangSmith, aparece el experimento Platzi Store trajectory evaluation procesándose en tiempo real. Cuando termina, el panorama es claro: la mayoría de conversaciones tienen score bajo, solo dos casos cumplieron la trayectoria completa de buscar productos seguida de verificar descuento.
El score general del experimento queda alrededor de 0.20, una cifra mejorable por mucho [09:00]. Ese número es la línea base sobre la que vas a iterar el system prompt, reforzando la instrucción de que el agente siempre verifique el descuento después de buscar un producto.
Ahora te toca a ti: ajusta el agente, corre la evaluación de nuevo y mira hasta dónde sube el score. ¿Lograste pasar de 0.20 a 0.80? Cuéntame en los comentarios qué cambios hiciste en el prompt y qué tanto mejoró la trayectoria.