

Claude Opus 4.7 tiene mejoras concretas en programación y comprensión visual vs. 4.6, pero también retrocesos que generan preguntas incómodas sobre costos y memoria.
Si usas modelos de IA para desarrollo, esto te afecta directamente.
Diferencias clave entre Claude Opus 4.6 y 4.7
- Rendimiento en código: mejor en 4.7
- Contexto largo: mejor en 4.6
- Costo real: mayor en 4.7
- Estabilidad: mejor en 4.6
Pasar a 4.7 no es un upgrade obligatorio: mejora en código, pero empeora en contexto y costo.
¿Cómo acceder a Opus 4.7? Si usas Claude, puedes probar 4.7 vía API con el id
claude-opus-4-7. Y en Claude Code se accede con /model.
Rendimiento de Claude Opus 4.7 vs. 4.6 en programación
El benchmark más relevante acá es SWE-Bench Pro, una versión de un test de ingeniería de software. En ese test, Opus 4.7 logra 64.3%, superando a GPT-5.4 (57.7%), según benchmarks internos de Anthropic, y posicionándose como uno de los modelos más capaces para desarrollo.
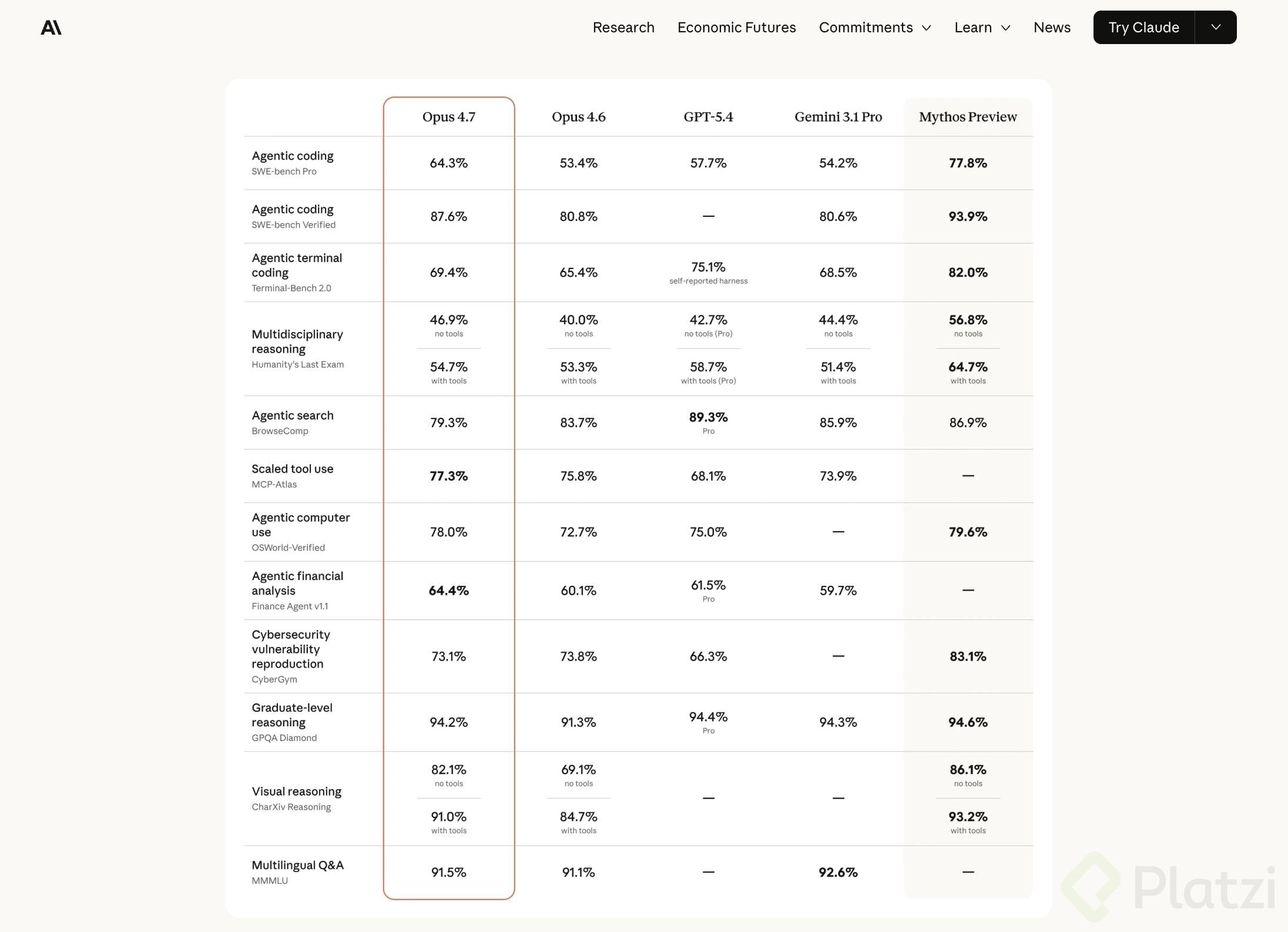
¿Qué es SWE-Bench Pro? Es un test de ingeniería de software que evalúa la capacidad de los modelos para resolver problemas reales de código. Sus preguntas se mantienen en secreto para reducir la contaminación y evitar que los modelos “hagan trampa” durante el entrenamiento, lo que lo hace más confiable que versiones anteriores.
El modelo también mejoró en comprensión visual. Opus 4.7 acepta imágenes de hasta 2,576 píxeles en el lado largo (~3.75 megapíxeles). Eso es más de 3 veces la resolución de modelos anteriores.
Anthropic no genera imágenes ni video, pero sus modelos reciben imágenes como input, y Opus 4.7 es especialmente bueno interpretando gráficos estadísticos, lo que lo hace útil para análisis de datos.
¿Dónde retrocedió Opus 4.7?
Aquí es donde el salto deja de ser claro y empiezan las dudas.
El test MRCR v2, también conocido como needle in a haystack (encontrar una aguja en un pajar), mide qué tanto un modelo mantiene la coherencia en ventanas de contexto muy largas. El método: meter pequeñas diferencias en un texto gigantesco y ver si el modelo las detecta.
Opus 4.6 sacaba 78.3%. Opus 4.7, con el máximo nivel de razonamiento activado, saca 32.2%. Menos de la mitad.
Anthropic respondió que ese test ya no es el estándar correcto y que ahora usan Graph WS. El problema: no pueden mostrar resultados de Graph WS porque Opus 4.7 está limitado a un millón de tokens y la mayoría de esas pruebas lo superan.
Eso, combinado con las caídas de servicio (92 horas en los últimos 90 días, cuando el estándar de la industria es menos de 45 minutos), sugiere un problema serio de escalabilidad de infraestructura.
¿Por qué importa la fecha de entrenamiento del modelo?
Opus 4.6 tiene datos hasta agosto de 2025. Opus 4.7 parece tener datos hasta inicios de 2026. Eso no es un detalle cosmético: cuando un modelo conoce algo internamente, no necesita ir a buscarlo con tokens; eso ahorra contexto, reduce el riesgo de context rot y mejora el output final.
Es la diferencia entre un desarrollador que ya conoce el framework que está usando versus uno que tiene que consultar la documentación en cada paso.
¿Qué es el context rot? Es cuando la ventana de contexto se satura de tokens externos (búsquedas web, MCP, herramientas), lo que degrada la calidad del razonamiento. Entre más información viva dentro del modelo y menos venga de afuera, menos probable es que el contexto se “pudra” y mejor es la calidad del código generado.
¿Cuánto más caro puede salirte usar Opus 4.7?
El costo por token entre 4.6 y 4.7 es idéntico. Pero el tokenizer nuevo procesa el mismo input en 1.0-1.35x más tokens, es decir, Opus 4.7 puede usar hasta 35% más tokens en su cadena de razonamiento (thinking). En términos simples: el mismo código ahora cuesta más tokens y ocupa más espacio en el contexto.
También hay un nuevo nivel de esfuerzo llamado xhigh entre “high” y “max”, y en Claude Code el nivel por defecto subió a xhigh. Eso afecta directamente el costo real de uso.
En la práctica, el análisis de la comunidad estima que el costo por tarea real puede subir entre 30% y 150%, dependiendo de la complejidad del trabajo.
Por eso, muchos lo describen como un “4.6.1”: mejoras reales en áreas específicas, sin el salto cualitativo que justifique ese aumento. Y hay más contexto que lo complica: dos laboratorios independientes detectaron que Opus 4.6 había bajado de calidad en las semanas previas al lanzamiento.
Margin LA midió una caída del 41% en SWE-Bench Pro y un investigador de AMD reportó una reducción del 67% en eficiencia en su flujo de trabajo. No hay explicación oficial definitiva para ninguno de los dos casos.
Todo esto convierte a Opus 4.7 en un modelo potencialmente más caro incluso sin cambiar el precio por token.
¿Vale la pena el salto entre Opus 4.6 y 4.7?
Depende del tipo de trabajo: si trabajas con tareas complejas de código o análisis visual, prueba el 4.7. Si dependes de contexto largo, estabilidad o control de costos, quédate con el 4.6 o espera la siguiente versión.
De 4.5 a 4.6 pasaron 73 días. De 4.6 a 4.7, 70, así que probablemente 4.8 o la que sigue la veamos pronto. El ritmo de lanzamientos es agresivo, pero la magnitud de cada salto parece estar reduciéndose.
👀 La diferencia entre modelos ya no está solo en benchmarks, sino en cómo se comportan en tareas reales. Cuéntanos: ¿usas Claude Code en tus proyectos? Deja en los comentarios si el salto de 4.6 a 4.7 lo has sentido en tu flujo de trabajo real.
Curso de Claude Code
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE







