

¿Estás buscando una alternativa para trabajar con IA: gratuita, potente y que cuide tu privacidad? ¡Bienvenido a DeepSeek-R1! En esta guía (inspirada en mi propia experiencia y algunas referencias de la comunidad) aprenderás:
- Qué es DeepSeek-R1 y por qué puede ser una gran opción.
- Cómo instalarlo usando Ollama para correrlo en tu propia computadora.
- Cómo integrarlo con Docker y una interfaz web para mayor comodidad.
- Opciones para integrarlo a proyectos, tanto de manera local como en la nube.
Qué es DeepSeek-R1
DeepSeek-R1 es un modelo de IA open-source, gratis y diseñado para tareas que requieran mucho razonamiento (por ejemplo, resolución de problemas de programación, matemáticas avanzadas o procesos lógicos). La ventaja principal es que todo puede ejecutarse en tu computadora, sin mandar tus datos a servidores externos, lo que brinda privacidad y te ahorra los costos mensuales de otros proveedores populares.
1. ¿Por qué DeepSeek-R1 es especial?
1º. Aprendizaje por Refuerzo (RL) vs. Entrenamiento Supervisado
DeepSeek-R1 se “entrena” resolviendo problemas por prueba y error, sin depender tanto de datos de ejemplo etiquetados de forma tradicional. Este proceso realza la capacidad de auto-verificación y reasoning de largo alcance.
2º. Eficiencia de costos
- Si lo corres localmente, podés usar versiones “distilled” de entre 1.5B y 70B parámetros que funcionan incluso en GPU comunes (o con un poco de truco, en CPU potentes). Esto evita cuotas mensuales altas o costos por token.
- La versión completa alcanza hasta 671B parámetros, ideal para tareas súper complejas (Ahí si tenés que tener hardware de gama alta $$$).
3º. Flexibilidad open-source
Al ser abierto, no hay restricciones para integrarlo en tus proyectos. Se puede tunear, combinar con otras bibliotecas o hasta crear tu propio servicio web basado en DeepSeek-R1.
2. Requisitos previos para instalar y correr DeepSeek-R1
- Conocimientos básicos de la terminal o línea de comandos.
- Tener un sistema Linux/macOS (o en Windows con WSL2).
- Docker instalado si planeás usar la interfaz web.
- Ollama para descargar y correr el modelo localmente (igualmente en este blog te ayudo a instalarlo).
3. Instalando Ollama
Ollama es una herramienta que permite gestionar y correr modelos de lenguaje localmente. Es como un “docker” de modelos de AI
- Instalación:
en Linux
curl -fsSL https://ollama.com/install.sh | sh
ollama -v # Verificá la versión instalada
o en MAC
brew install ollama
brew services start ollama # Inicia el servicio de ollama con brew para no tener que ejecutar ´ollama serve´
ollama -v # Verificá la versión instalada
- Descarga de DeepSeek-R1 con Ollama
Elegí el modelo “distilled” que se ajuste a tu GPU (o CPU).-
1.5B parámetros (aprox. 1.1GB):
ollama run deepseek-r1:1.5b -
7B parámetros (aprox. 4.7GB):
ollama run deepseek-r1 -
70B parámetros (requiere +24GB de VRAM):
ollama run deepseek-r1:70b -
Versión completa 671B (para entusiastas con +300GB de VRAM):
ollama run deepseek-r1:671b
-
Cuando ejecutes deepseek vas a ver que empieza a descargar el modelo, y luego tendrás una terminal como la siguiente:
Tip: Si tu PC no dispone de tanta capacidad, probá primero la versión de 1.5B y luego empezá a probar modelos más grandes. El 1.5B pesa cerca de 1GB, tiene muchas limitaciones, pero es funcional. En la página de ollama podes ver otros modelos compatibles.
4. Montando la interfaz web con Docker
Para quienes prefieran una UI amigable, podés usar Open Web UI y ver tus chats con DeepSeek-R1 dentro de un entorno visual.
a. Instalá Docker siguiendo las instrucciones en docker.com (descargá la versión para tu sistema operativo).
b. Corré el contenedor de Open Web UI:
docker run -d -p --network=host \
-v open-webui:/app/backend/data \
-e OLLAMA_BASE_URL=http://127.0.0.1:11434 \
--name open-webui \
--restart always \
ghcr.io/open-webui/open-webui:main
Cuidado con alguna de estas reglas, son solo en modo desarrollo. Por ejemplo la de
--network=hostte hace compartir la red entre tu pc y el contenedor de docker.
c. Accedé a la interfaz en http://localhost:8080.
Una vez instalado vas a poder crearte tu cuenta de admin con la cuál podrás gestionar esta plataforma.
d. Seleccioná deepseek-r1:1.5b y listo: vas a poder conversar con DeepSeek-R1 sin mandar nada a servidores remotos.
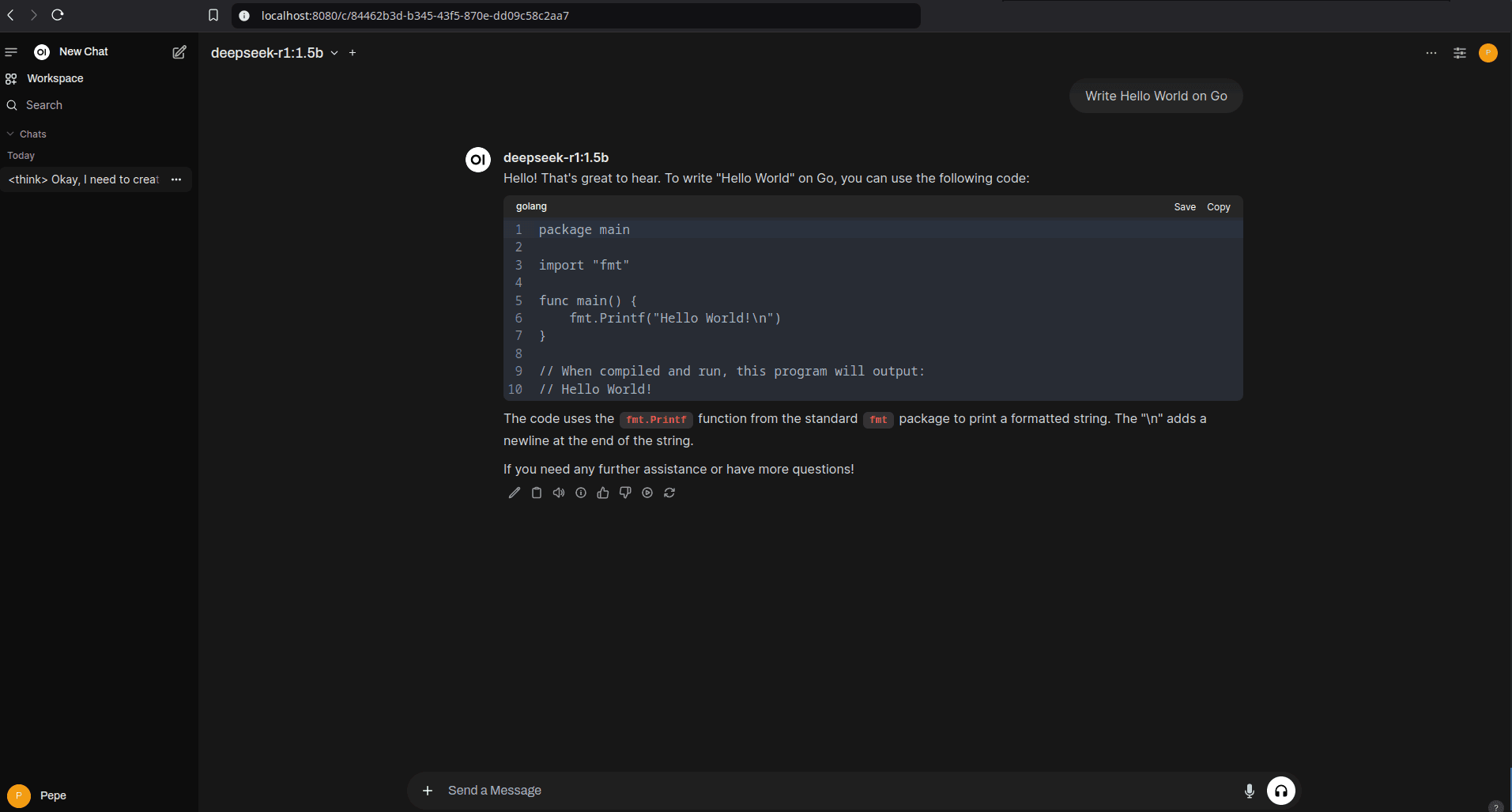
5. Probando DeepSeek-R1 en tu máquina
Una vez que Ollama descargó el modelo y tenés la interfaz corriendo (opcional), ya podés empezar a hacerle preguntas desde la terminal o desde la UI. Para la terminal:
ollama run deepseek-r1:1.5b
6. Integrándolo en tus proyectos
DeepSeek-R1 tiene dos modos de integración básicos: local (con Ollama) y en la nube (con el API oficial).
Te voy a mostrar ejemplos de como conectarte a esas API’s desde tu código en python:
6.1 Uso local (privacidad total)
Podés hacer que Ollama actúe como un endpoint compatible con OpenAI, apuntando tus scripts de Python a tu instancia local:
import openai
# Conectarse a Ollama
client = openai.Client(
base_url="http://localhost:11434/v1",
api_key="ollama"
)
response = client.chat.completions.create(
model="deepseek-r1:1.5b", # Reemplazá 1.5b con la versión elegida
messages=[{"role": "user", "content": "Make a \"Hello World\" with go"}],
temperature=0.7
)
6.2 Uso en la nube (API oficial de DeepSeek-R1)
Si necesitás escalar para aplicaciones grandes, DeepSeek ofrece su propia API, parecida al estilo de OpenAI:
import openai
client = openai.OpenAI(
base_url="https://api.deepseek.com/v1",
api_key="TU_API_KEY"
)
response = client.chat.completions.create(
model="deepseek-reasoner",
messages=[{"role": "user", "content": "Crea un script de web scraping con manejo de errores"}],
max_tokens=1000
)
Con esto, tu aplicación se conecta a los servidores de DeepSeek, al estilo “Software as a Service”.
7. Conclusiones sobre el uso de DeepSeek-R1
DeepSeek-R1 es una opción perfecta si querés:
- Evitar costos mensuales exorbitantes
- Mantener tus datos dentro de tu propia infraestructura
- Tener la libertad de ajustar y mejorar el modelo para tus proyectos
Además, su enfoque en razonamiento profundo lo hace ideal para tareas complejas. Probalo con problemas de código, preguntas matemáticas difíciles o en cualquier proyecto que requiera un plus de capacidad lógica. ¡Vas a ver cómo le saca ventaja a muchas opciones comerciales y te deja un poco más tranquilo con la privacidad de tus datos!
Continúa aprendiendo sobre inteligencia artificial
También puedes explorar la Escuela de Data Science e Inteligencia Artificial en donde encontrarás rutas de aprendizaje sobre:
- Modelos de Difusión: Generación de Imágenes con AI
- Herramientas de AI para Programadores
- AI: Desarrollo de Apps con LLMs
Referencias y lecturas recomendadas sobre DeepSeek-R1 y su instalación
Curso de Herramientas de AI para Devs
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE






