

Cuando los LLM (Large Language Models), como ChatGPT salieron al mundo, como interfaces capaces de responder preguntas con resultados convincentes, el mundo se revolucionó de ver tanto poder. Cambio la forma en la que estudiamos, aprendemos e incluso interactuamos con nuestro trabajo. A hoy 2025, muchos profesionales no conciben su flujo de trabajo sin un LLM como los desarrollados por OpenAI o Anthropic.

Recientemente, Deepseek ha lanzado varios modelos innovadores, entre ellos R1, v2.5 y V3. Estos últimos sobresalen especialmente en la generación de código, la ejecución de operaciones matemáticas complejas y el dominio del idioma chino.
Una de las innovaciones más destacables de Deepseek es la posibilidad de ejecutar este modelo de código abierto localmente en cualquier computador compatible. Esta característica contribuye significativamente a la democratización del acceso a modelos avanzados, impulsando el desarrollo e investigación en el campo de los LLM.
Al ser de código abierto, podemos comprender con mayor profundidad su funcionamiento, metodología de entrenamiento y, además, modificarlo para crear un LLM personalizado que ofrezca soluciones a problemas específicos.
Imagina un mundo donde cada persona tenga su propio LLM, entrenado con información personal: notas escolares, recuerdos de infancia, estados financieros, preferencias, historias personales y otros datos que normalmente no compartiríamos con empresas externas, pero que podríamos mantener bajo nuestro control.
Estos LLMs personales funcionarían como extensiones de nuestro cerebro, repositorios donde almacenar recuerdos, hechos, momentos y acceder a ellos de manera intuitiva, rápida y mediante lenguaje natural.

Seguramente falta mucho para que lleguemos a ese momento, pero al menos ya es posible ejecutar estos modelos de forma local y así mismo de forma controlada. Cualquier persona con un suficiente capacidad de cómputo puede lograrlo. Y en este blog te enseñaré como desplegar DeepSeek en tu cluster de Kubernetes.
¿Qué es DeepSeek y por qué usar Kubernetes?
Imagina que tienes una tarea de desplegar un LLM personalizado en la nube de tu empresa. ¿Cómo lo harías?
Seguro la primera opción puede ser usar un servidor EC2 con GPU. Pero este enfoque presenta limitaciones de recursos y escasa flexibilidad ante picos de tráfico inesperados. Puedes agregar manualmente la cantidad de servidores que consideres pero eventualmente esta estrategia de escalabilidad manual resultará costosa e ineficiente. Aquí es donde Kubernetes demuestra su valor.
Kubernetes es uno de los orquestadores de contenedores y de cargas operativas de aplicaciones conocidos de la industria. Destaca por su capacidad para adaptarse rápidamente a elevados volúmenes de tráfico, proporcionando escalabilidad, resiliencia y tolerancia a fallos en múltiples entornos.
Al ejecutar DeepSeek en Kubernetes en forma de contenedor no solo estás disponibilizando tu propio LLM, sino también tienes la capacidad de exponerlo al mundo de forma controlada y escalable, es decir, puedes agregar tantos recursos como sean necesarios para atender la necesidad de tus usuarios o clientes.
Deepseek en Kubernetes:

Para trabajar con DeepSeek ejecutándose en Kubernetes sobre AWS, te recomiendo tres aspectos fundamentales a considerar cuando utilizas recursos en la nube:
-
Lo que no se mide no se puede mejorar: Implementa herramientas de monitoreo y observabilidad para realizar un seguimiento detallado de todas las operaciones en tu clúster. Puedes integrar soluciones como el stack ELK (Elasticsearch, Logstash, Kibana), EFK (Elasticsearch, Fluentd, Kibana) o la combinación de Prometheus y Grafana para obtener métricas precisas y visualizaciones efectivas.
-
No todo se soluciona añadiendo más servidores: Aunque la solución aparentemente sencilla sea incrementar el número de servidores, cuando trabajas con modelos que demandan alto procesamiento con GPU, esta estrategia resulta insuficiente. Según tu caso de uso, puedes agregar capas extras de seguridad y control como rate limits a tus aplicaciones, establecer restricciones en la cantidad máxima de tokens que el modelo LLM procesa y genera. Estas medidas podrían reducir significativamente el impacto en el procesamiento.
-
Elasticidad y Escalabilidad el balance clave para responder a demandas poco predecibles: Aquí entra una mezcla entre estos dos conceptos. En ocasiones si serán necesarios más pods, en otras ocasiones no será suficiente solo con más pods, también serán necesario más servidores, esto te dará una mayor capacidad de respuesta ante picos ubicando pods o ejecuciones de tus modelos en instancias efímeras y con más capacidad que pueden ser eliminadas después del alto pico de tráfico que genere el evento de escalabilidad.
Los modelos LLM llegaron para quedarse, y quizás en un futuro ejecutar tus propios LLMs podría ser un diferencial o valor agregado clave para la empresa en la que trabajas o incluso para tu vida personal. DeepSeek es uno de los primeros modelos que podemos ejecutar y es emocionante ver como se transforma el ecosistema de la nube, contenedores y kubernetes, mediante estos nuevos avances.
Tutorial: Deepseek en Kubernetes
Pre-requisitos:
- Minikube
- Conocimientos de Kubernetes
- Manejo de la terminal de comandos
Proceso de despliegue:
- Clonar el repositorio donde se encuentran los archivos relacionados al servicio y a la interfaz gráfica. Estos archivos definen:
git clone https://github.com/platzi/kubernetes/
# Change directory to the k8s files
cd kubernetes/deepseek-local-k8s
- Aplicar los Yaml Files y Validar.
kubectl apply -f server-deployment.yaml
# Output
persistentvolumeclaim/ollama-model-pvc created
deployment.apps/deepseek-server created
service/deepseek-server created
kubectl apply -f ui-deployment.yaml
# Output
persistentvolumeclaim/deepseek-ui-pvc created
deployment.apps/deepseek-ui created
service/deepseek-ui created
ingress.networking.k8s.io/deepseek-ingress created
Validar el correcto despliegue de los objetos creados y probar el primer curl.
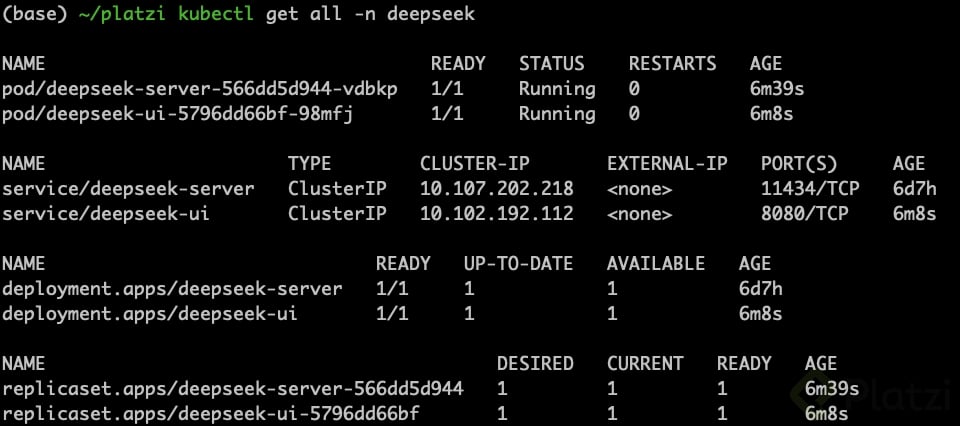
Para exponer el servicio en un puerto de tu máquina local puedes hacer un port-forwarding al SVC de deepseek-server mediante al siguiente comando:
kubectl port-forward svc/deepseek-server -n deepseek 35000:11434
De esta forma ya puede ejecutar un CURL con una petición al pod con el servidor de Deepseek:

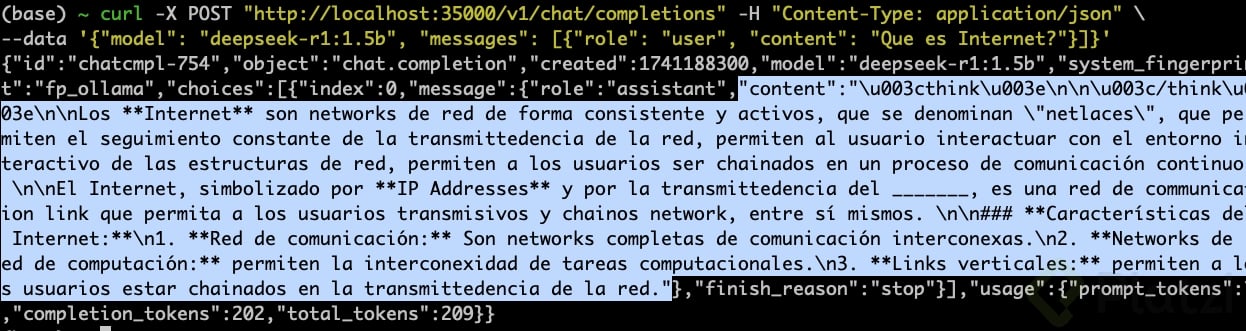
- Encender tunnel entre minikube y tu máquina local.
Para poder acceder a la URL definida en el ingress declarado en el archivo ui-deployment.yaml, debemos ajustar nuestro DNS local agregando un map entre 127.0.0.1 y la URL en el ingress.
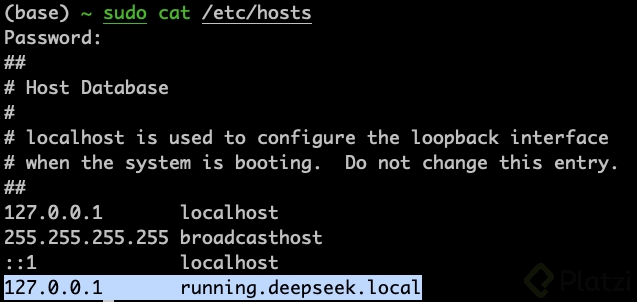
- Después de tener la DNS local configurado, debemos ejecutar el comando
minikube tunnelel cual nos redirecciona las peticiones de nuestra máquina al ingress en el cluster. En este punto ya podemos entrar arunning.deepseek.localdesde nuestro navegador.
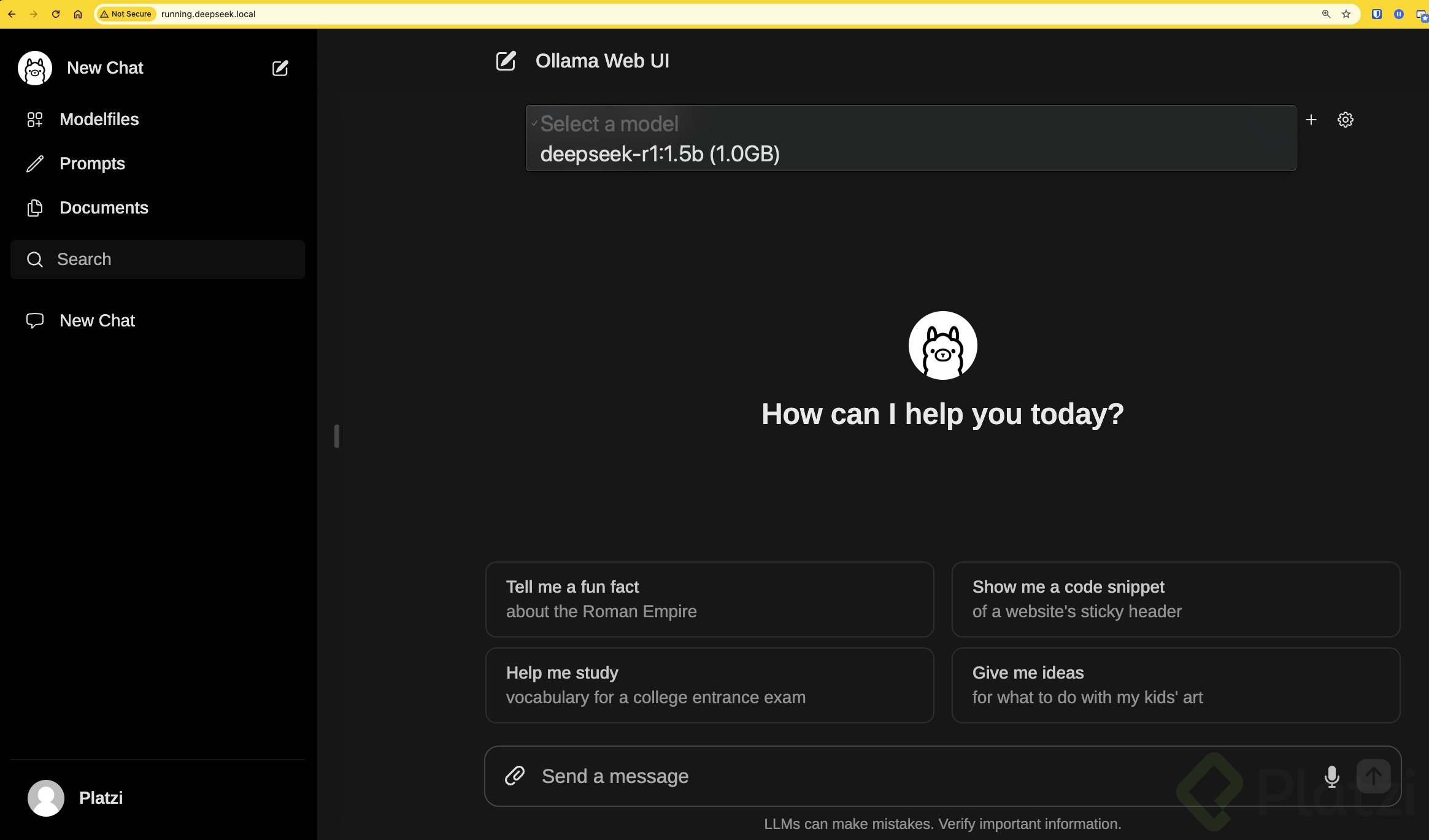
Desde esta interfaz puedes crear una cuenta e ingresar mediante la interfaz gráfica de Ollama para consumir el modelo de DeepSeek.
Asegúrate de seleccionar el respectivo modelo, en este caso solo tenemos disponible el modelo básico, pero aquí deberían listarse los otros modelos que descargues. Recuerda que esto dependerá de tu capacidad de cómputo.
- ¡Disfruta!
Optimizaciones para ejecutar LLMs en Kubernetes
El clásico meme de en mi máquina funciona podría suceder aquí, si sigues esta guía al pie de la letra y cuentas con los suficientes recursos de Memoria y CPU es probable que esta guía funcione tanto para local como para la nube.
Sin embargo la nube es otro escenario y nuestro cluster y despliegue deberían adaptarse a eso. Te dejo algunas recomendaciones a la hora de replicar este escenario en la nube:
- Etiquetas los Nodos: Te permitirá etiquetar a los nodos en tu cluster según ciertas propiedades, garantizando el correcto despliegue de pods en nodos con recursos.
kubectl label nodes <nombre-del-nodo> hardware-type=GPU
kubectl label nodes <nombre-del-nodo> gpu-type=nvidia-a100
kubectl label nodes <nombre-del-nodo> gpu-count=4
- Taints a nodos con GPU: Te ayudarán a reservar estos nodos exclusivamente para cargas de trabajo especificas, en el ejemplo seria para tareas que requieran GPU
kubectl taint nodes <nombre-del-nodo> hardware=gpu:NoSchedule
- Configurar Pods con affinities y tolerations:
Las affinities permiten atraer pods hacia ciertos nodos basándose en etiquetas, mientras que las tolerations permiten que los pods se programen en nodos con taints específicos, que normalmente repelerían a la mayoría de los pods.
Recuerda que para definir recursos de tipo GPU se utiliza el plugin k8s-device-plugin de Nvidia, AMD o Intel, los cuales permiten monitorear, agendar y definir cargas de trabajo con GPU como recurso dentro del cluster.
Puedes encontrar el archivo de deployment ajustado con affinities y tolerations en el link del repo.
Casos de Uso de LLMs en Kubernetes

Te dejo algunas ideas de negocios que podrías considerar para sacar mayor provecho a tener tu propio servicio de LLM en un cluster de kubernetes totalmente bajo tu control.
-
LLM as a Service: Algunas empresas como Abacus.ai y Braintu, crearon servicios alrededor de los LLMs más conocidos, en este caso podrías agregar nuevas funcionalidades y generar una oferta de valor de mayor impacto frente a tus competidores para crear una solución totalmente personalizada.
-
LLM Wrapper: Podrías disponer de un modelo sencillo, darle un rol específico, un formato estándar de respuesta y garantizar que tu LLM responda según tu producto. Esto podría ir desde un Bot de servicio al cliente, un bot de búsqueda rápida en documentación, una interfaz en lenguaje natural para interactuar con sistemas complejos como portales de compras entre otros.
-
LLM para Análisis de Datos Confidenciales: Implementa un LLM especializado en analizar grandes volúmenes de datos sensibles o confidenciales de empresas sin que estos salgan de su infraestructura. Esto es especialmente valioso para sectores como salud, finanzas o legal, donde la privacidad de los datos es crítica y no pueden utilizar servicios en la nube pública. Tu solución en Kubernetes permitiría análisis avanzados, generación de informes y extracción de insights manteniendo total cumplimiento regulatorio.
Te dejo algunos recursos y documentación oficial que puedes usar para complementar tu experiencia de aprendizaje:
Curso de Kubernetes
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE







