

Internet no es como hace 20 años; es un lugar de mayor movimiento, creatividad y velocidad. Hace 2 décadas no teníamos las velocidades de hoy: las descargas de canciones, reproducciones de videos en HD o 4K, videollamadas y compras, todo sucede en cuestión de segundos.
Hoy te voy a contar los secretos del equipo de ingeniería de Platzi sobre cómo usamos el caché para generar la mejor experiencia de aprendizaje en nuestros estudiantes.
Caché: Es un espacio de memoria de acceso rápido que almacena información que es usada con mucha frecuencia o que recientemente ha sido procesada. Esto permite mayor acceso para futuras consultas.
Es más fácil con ejemplos, ¿cierto? Este viene de Ronald Escalona, nuestro VP de Ingeniería. Cuando me uní al equipo, me explicó el concepto de caché de la siguiente manera:
Él preguntó: "¿Qué hora es?"
Yo miré mi reloj y respondí: "Son las 2 y 15."
Pasaron 5 segundos y me preguntó de nuevo: "¿Qué hora es?"
Y yo, con una expresión de 😒, respondí: "2 y 15."
Me dijo: “eso es caché, accediste a la información de forma inmediata, desde tu memoria y no mirando nuevamente el reloj”.
¿Que es el Caché?
Este no es un concepto nuevo, viene desde 1965 cuando Maurice Wilkes introdujo la memoria esclava (Slave Memory). Este concepto presentó la memoria intermedia de rápido acceso que hoy conocemos como Caché.
 Wilkes, “Slave Memories and Dynamic Storage Allocation,” IEEE Transactions on Electronic Computers, Vol. EC-1.4, Issue: 2, (April 1965) 270-271.
Wilkes, “Slave Memories and Dynamic Storage Allocation,” IEEE Transactions on Electronic Computers, Vol. EC-1.4, Issue: 2, (April 1965) 270-271.
Caché es un espacio de memoria que permite optimizar las respuestas a peticiones o consultas. Este suele ser una base de datos o un almacenamiento optimizado para acceso frecuente y está ubicada antes del origen o servidor que responde cada petición. No solo aplica para la información recientemente consultada, también para la información de mayor consumo.
Pero volviendo al hilo, ¿cómo es posible que un concepto de 1965 sea lo que nos ayuda a hacer que platzi.com o la mayoría de sitios hoy en día funcionen tan rápido?
Bueno, el secreto está en usarlo en todo lugar donde sea posible y técnicamente viable 😳 es decir, la respuesta es Depende.

¿Dónde puedo usar caché?
Es el año 2024, post-pandemia, y somos amantes de la nube, las tecnologías Serverless y todo lo que nos ahorre trabajo, entonces usemos caché en todo lado, ¿no?
Lo más importante antes de usar caché es entender por qué y para qué se podría usar. Las formas más convencionales de presentarlo son dividirlo en caché del lado del cliente y caché del lado del servidor, pero me gustaría que entremos más en profundidad y revisemos múltiples casos de uso para entender la diferencia.
A nivel de Procesador:
Este no lo gestionamos nosotros como DevOps, SRE o Developers, suele ser gestionado automáticamente por la CPU y el sistema operativo.
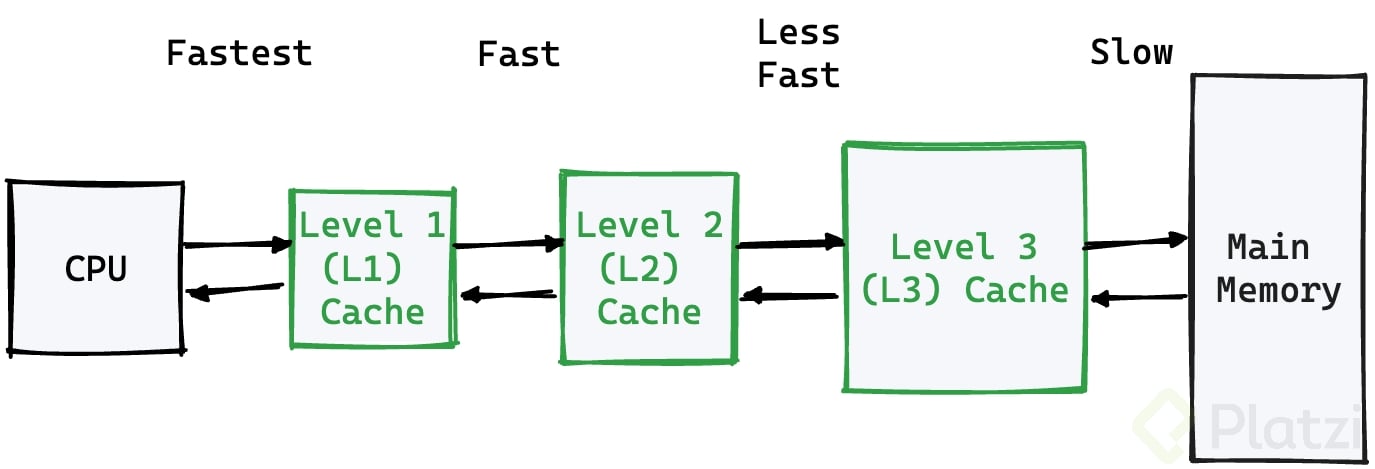
A nivel de build o empaquetamiento:
Usualmente, las aplicaciones se suelen desplegar de forma compilada o “containerizada”. Para esto, se requiere descargar múltiples librerías, lo cual también puede ser optimizado usando caché. Esto garantiza despliegues y rollbacks más rápidos, lo cual es beneficioso desde un punto de vista de negocio, ya que permite entregar valor de forma ágil.
- En tiempo de build o compilación: las dependencias o librerías se pueden cachear, lo cual permite compilaciones optimas ya que las dependencias estén precargadas en memoria y el tiempo de descarga se reduce de minutos a segundos. Algunos de los gestores de caché que usamos para tiempo de compilación son Turbo Repo y Yarn.
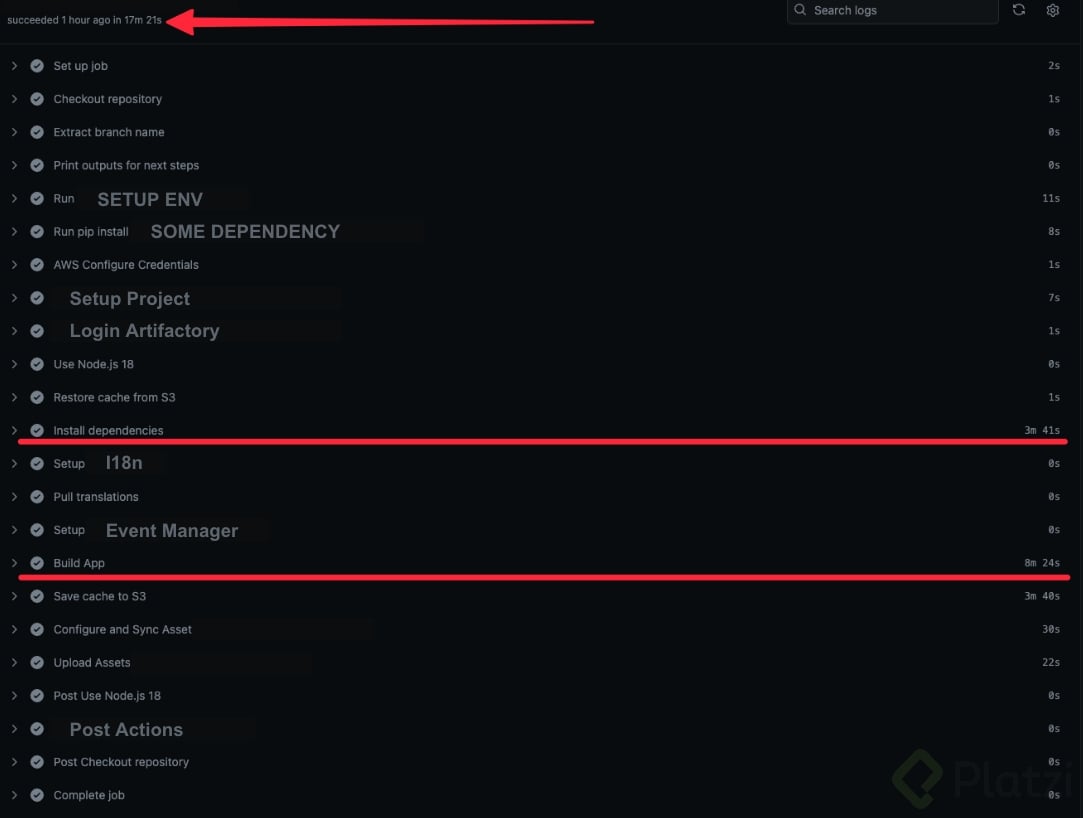
En nuestro caso, los tiempos de compilación se redujeron de 17 a 6 minutos. La mayor reducción se logró en el paso de instalación de dependencias, que pasó de casi 4 minutos a solo un segundo. Es importante mencionar los costos adicionales asociados al uso de caché, como el costo de almacenamiento. Este costo suele ser bajo o incluso despreciable, ya que en los Cloud Providers generalmente es menor que el costo asociado al tiempo de procesamiento o ejecución de un workflow de CI/CD.
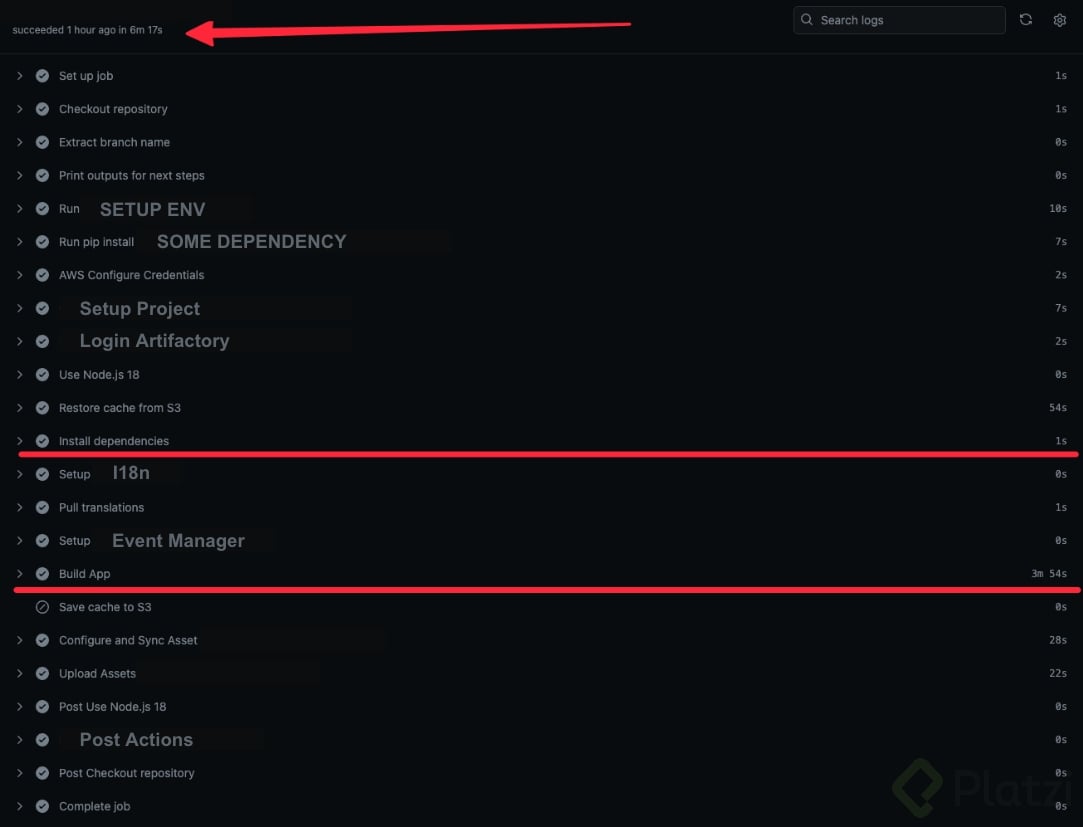
- En contenedores: El caché puede aplicarse al momento de la creación de las imagenes de Docker o LXC, usando las layers de los contenedores. Esto también suele usarse para dependencias, pero es más susceptible a ser invalidado cuando alguna versión minor o patch cambie. Además de usarse para dependencias, también es útil para instalación de utilidades del contenedor o instrucciones del sistema operativo que puedan vivir en layers.

A nivel de bases de datos:
Servicios como Aurora PostgreSQL de AWS tienen buffers de caché que permiten reducir I/O para cachear la data de uso más frecuente, lo cual permite incrementar la escalabilidad y mejorar el performance de las consultas. Esto lo podemos gestionar configurando el Cluster Cache Management. Eso es solo un ejemplo a nivel de DB relacionales. Por ejemplo, para NoSQL, con DynamoDB el caché puede ser gestionado con DAX para mejorar el desempeño hasta en 10x.
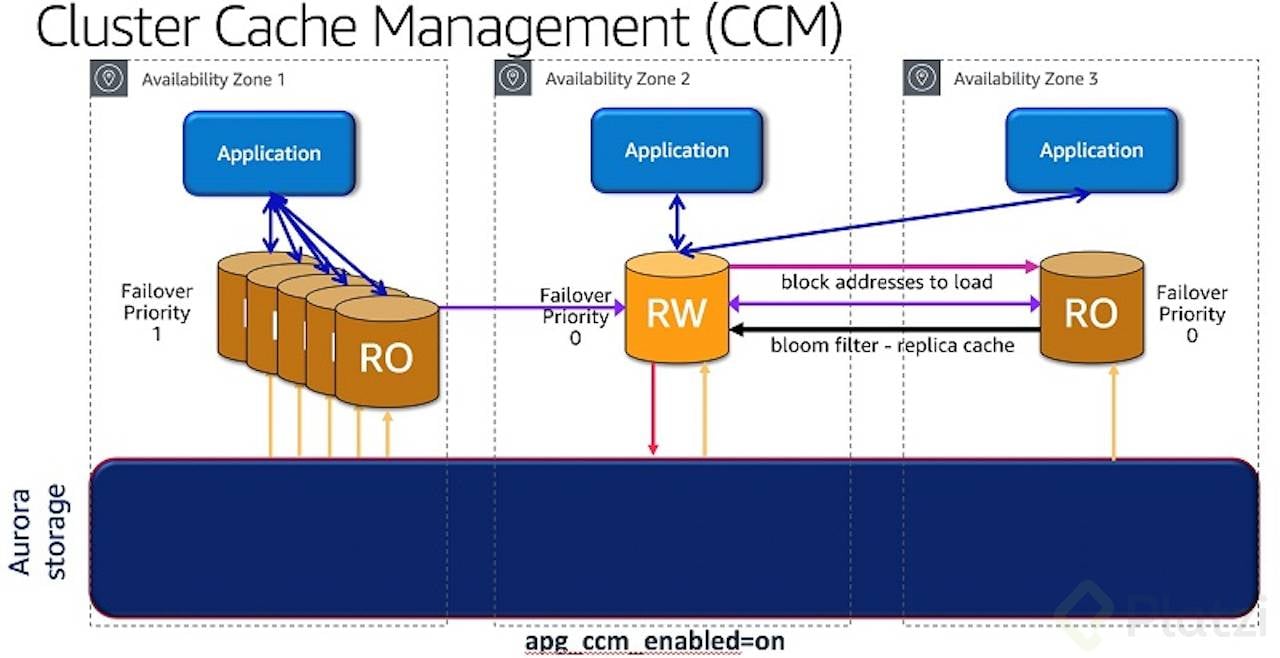
Grafico de: Introduction to Aurora PostgreSQL cluster cache management
A nivel de Backend:
Tenemos múltiples opciones, la solución más común es usar almacenamientos de datos en memoria (In memory data store), usualmente suelen ser Redis o MemCached. Los cuales permiten almacenar y consultar resultados de queries a bases de datos, data procesada, o data de alta transaccionalidad, para así reducir los tiempos de respuesta del backend evitando tener que re-procesar, o impactar la base de datos con consultas computacionalmente complejas.
A nivel de Servidores y CDN:
AWS, GCP y Azure son los 3 Cloud Providers más usados según la encuesta de Stack Overflow en 2024, cada uno de estos tiene una amplia red de servidores distribuidos a nivel mundial que permiten contar con CDNs robustas para servir contenido con baja latencia entre clientes y servidores. Entre las características comunes tenemos:
- Garantía de conexiones seguras con SSL/TLS
- Compresión de contenido
- Purga de caché en tiempo real
Sin embargo, para nuestros casos de uso, su capa de red y su CDN no son tan robustas como las de Cloudflare 😮, que es el cuarto proveedor de nube más usado según la encuesta de Stack Overflow para 2024. Cloudflare permite desplegar código complejo y de alta transaccionalidad en sus edge locations, lo que facilita la incorporación de lógica de negocio para definir optimizaciones en patrones de caché, distribución y acceso a la información de forma eficiente.

Esto permite que los archivos estáticos o resultados de APIs no tengan que ser re-procesados o entregados por los servidores principales. Aquí es donde entran los Edge Locations, los cuales responden estas peticiones desde ubicaciones geográficas más cercanas al usuario final, generando bajas latencias y reduciendo la cantidad de peticiones que impactan el origen.
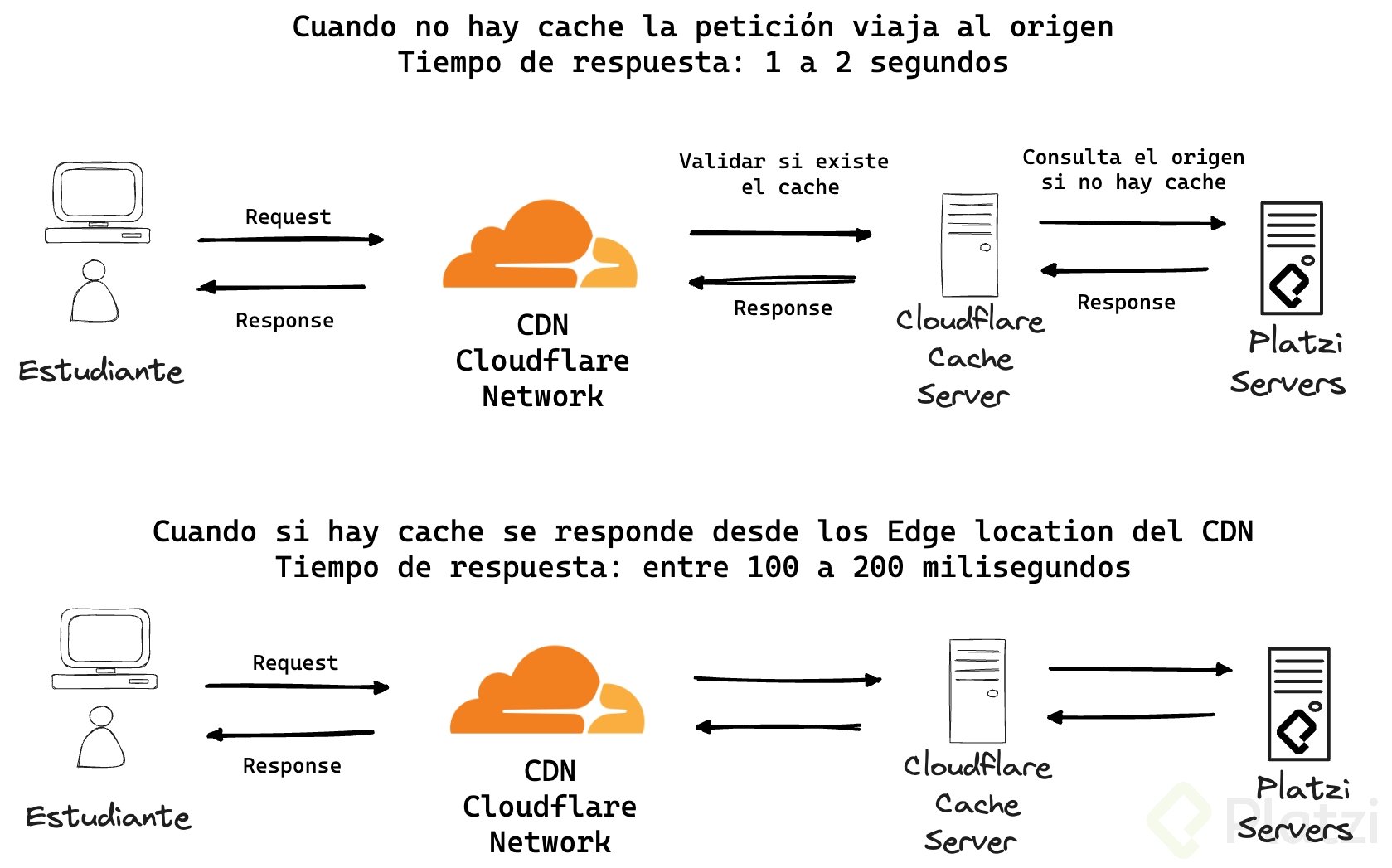
En este momento podrías pensar que todas las CDNs hacen lo mismo, y sí, todos los proveedores de nube permiten ejecutar lógica en el edge, unos con más limitantes que otros. Pero recuerda que este blog es con respecto al caché. Las funcionalidades, ventajas y protecciones que tiene Cloudflare con respecto a la implementación y optimización de caché resaltan en cada comparación entre proveedores.
A nivel de Frontend:
Las estrategias de caché más habituales son el caché del Browser, almacenamiento Local y de Sesión, así como los Service Workers, cada uno de estos permite almacenar información en el navegador o en la memoria del mismo cliente, evitando incluso que este tenga que hacer peticiones a un API externa, y que en lugar de eso responda con información guardada en almacenamiento local.

Utilizar caché en todos estos lugares nos ha ayudado a hacer que nuestra entrega de contenido estático, de video, de APIs, entre otros, tenga tiempos de respuesta muy bajos!
El temor de invalidar caché:
Pero implementar caché puede parecer un sueño en algunos casos, sueño que se vuelve pesadilla cuando hablamos de invalidación de caché. Ya lo dijo Phil Karlton, un famoso developer en Netscape:
There are only two hard things in Computer Science: cache invalidation and naming things.
Invalidar caché es un proceso simple que elimina la información cacheada según un criterio que puede ser tiempo, tamaño, versión o modificación. Esto va a variar según la función o criticidad de la información.
Realmente el problema de invalidar el caché es definir correctamente el criterio con el cual se debe generar y eliminar ese caché. Escoger un patrón de acceso incorrecto podría llevar a generar puntos de caché que hagan overlapping entre ellos generando problemas de consistencia de la información, así también si no escogemos correctamente la forma de invalidar caché se podrían generar graves problemas tales como:
- Respuestas con información desactualizada o incorrecta
- Problemas de bajo rendimiento debido a alta tasa de Miss Caché
- Estampidas de caché

Comic: Mr. Invincible, by Pascal Jousselin
Finalmente ¿Cómo vas a usar el caché?
Caché no es un tema trivial, requiere mucha experticia del negocio, algunos asocian la complejidad de definir el caché con predecir el futuro. Al implementar caché, siempre surgen muchas dudas como: ¿Cuánto tiempo debe vivir la información en el edge o en el memcached? Que criterio usar para invalidarlo? ¿Cómo debuggear correctamente? ¿Cómo medir el impacto en cada componente de la plataforma?
Aunque no todo Platzi tiene estas estrategias de caché implementadas. La mayor parte de la plataforma está en constante observación e iteración para reducir tiempos y lograr la mejor experiencia para nuestros estudiantes.El último avance que tuvimos con respecto al caché y a nuestros tiempos de respuesta no se mide en días, horas, minutos ni segundos; en esa ocasión, llegamos a optimización en el orden de milisegundos.
¿Y tú, ya estás implementando estrategias de caché? Cuéntame tus dudas en los comentarios
Curso de Introducción a Cómputo e Infraestructura de AWS
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE

