Crear la red neural, definir capas, compilar, entrenar, evaluar y predicciones
Clase 11 de 28 • Curso Profesional de Redes Neuronales con TensorFlow
Contenido del curso
Manejo y preprocesamiento de datos para redes neuronales
- 3

Carga y Procesamiento de Bases de Datos en Inteligencia Artificial
02:48 min - 4

Carga de Bases de Datos JSON desde GCP en Google Colab
10:25 min - 5

Codificación Base64 y Gestión de Imágenes en Google Colab
12:50 min - 6

Preprocesamiento y limpieza de datos
12:15 min - 7

Keras datasets
10:14 min - 8

Datasets generators
18:36 min - 9

Aprende a buscar bases de datos para deep learning
04:14 min - 10

Cómo distribuir los datos
06:50 min - 11

Crear la red neural, definir capas, compilar, entrenar, evaluar y predicciones
Viendo ahora
Optimización de precisión de modelos
- 12

Métodos de regularización: overfitting y underfitting
11:16 min - 13

Recomendaciones prácticas para ajustar un modelo
12:00 min - 14

Métricas para medir la eficiencia de un modelo: callback
08:18 min - 15

Monitoreo del entrenamiento en tiempo real: early stopping y patience
07:04 min - 16

KerasTuner: construyendo el modelo
13:54 min - 17

KerasTuner: buscando la mejor configuración para tu modelo
08:45 min
Almacenamiento y carga de modelos
Fundamentos de aprendizaje por transferencia
Resultados de entrenamiento
Resumen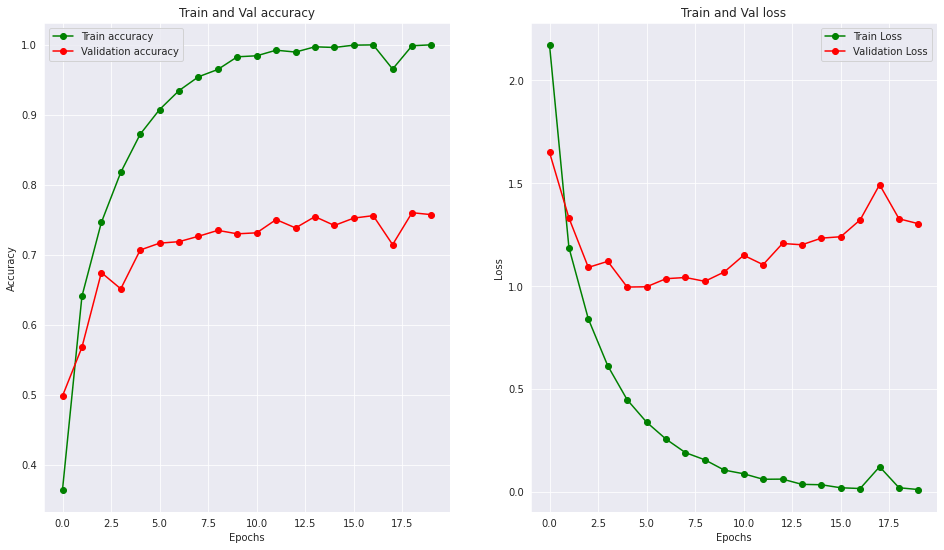
Ya tenemos todas las configuraciones previas para programar nuestra red, lo siguiente será definir una arquitectura, compilar el modelo y revisar el rendimiento de la red.
Creando el modelo de red neuronal
Definiremos un modelo con la clase Sequential de Keras, esta nos permitirá apilar varias capas una encima de otra para lograr el efecto de aprendizaje profundo.
La primer capa será de entrada, donde recibiremos una imagen de 28x28 pixeles en un solo canal, una vez recibida será aplanada para ser procesada como un array unidimensional.
Las siguientes 2 capas serán capas profundas con 256 y 128 neuronas respectivamente, y tendrán como función de activación la ReLU.
La capa de salida será una capa de 24 neuronas (una por cada posible clase) de activación Softmax que nos retornará un array con las probabilidades de cada letra.
model_base = tf.keras.models.Sequential( [tf.keras.layers.Flatten(input_shape = (28, 28, 1)), tf.keras.layers.Dense(256, activation = "relu"), tf.keras.layers.Dense(128, activation = "relu"), tf.keras.layers.Dense(len(classes), activation = "softmax")] )
Si llamamos el método summary obtendremos un resumen de la arquitectura de la red.
model_base.summary() Model: "sequential" _________________________________________________________________ Layer (type) Output Shape Param ================================================================= flatten_2 (Flatten) (None, 784) 0 dense_5 (Dense) (None, 256) 200960 dense_6 (Dense) (None, 128) 32896 dense_7 (Dense) (None, 24) 3096 ================================================================= Total params: 236,952 Trainable params: 236,952 Non-trainable params: 0 _________________________________________________________________
Compilación y entrenamiento del modelo
Compilaremos el modelo definiendo un optimizador, para este caso determinamos adam, un algoritmo que permite actualizar automáticamente el learning rate según el desempeño de la red. Como función de pérdida aplicaremos categorical cross entropy y la métrica de éxito será la precisión.
Entrenaremos el modelo con el image generator de entrenamiento, durante 20 épocas y con los datos de validación.
model_base.compile(optimizer = "adam", loss = "categorical_crossentropy", metrics = ["accuracy"]) history = model_base.fit( train_generator, epochs = 20, validation_data = validation_generator )
En la época final tendremos una precisión casi total durante el entrenamiento pero un rendimiento diferente sobre los datos de validación.
Epoch 20/20 215/215 [==============================] - 6s 27ms/step - loss: 0.0101 - accuracy: 0.9999 - val_loss: 1.3020 - val_accuracy: 0.7572
Si evaluamos el modelo, nos encontraremos con una precisión del 76%, donde entrenamiento era casi absoluta.
results = model_base.evaluate(test_generator) 57/57 [==============================] - 2s 36ms/step - loss: 1.2101 - accuracy: 0.7616
Análisis del desempeño de la red
Para entender más gráficamente lo que sucedió, crearemos la función de visualización de resultados, que comparará el rendimiento del entrenamiento sobre el rendimiento de validación tanto términos de accuracy como de loss.
def visualizacion_resultados(history): epochs = [i for i in range(20)] fig, ax = plt.subplots(1, 2) train_acc = history.history["accuracy"] train_loss = history.history["loss"] val_acc = history.history["val_accuracy"] val_loss = history.history["val_loss"] fig.set_size_inches(16, 9) ax[0].plot(epochs, train_acc, "go-", label = "Train accuracy") ax[0].plot(epochs, val_acc, "ro-", label = "Validation accuracy") ax[0].set_title("Train and Val accuracy") ax[0].legend() ax[0].set_xlabel("Epochs") ax[0].set_ylabel("Accuracy") ax[1].plot(epochs, train_loss, "go-", label = "Train Loss") ax[1].plot(epochs, val_loss, "ro-", label = "Validation Loss") ax[1].set_title("Train and Val loss") ax[1].legend() ax[1].set_xlabel("Epochs") ax[1].set_ylabel("Loss") plt.show()
Si corremos la función obtendremos información valiosísima con respecto al comportamiento del modelo.
visualizacion_resultados(history)
Puedes notar una diferencia abrupta tanto en el accuracy como en el loss, en la etapa de entrenamiento la red aprendió óptimamente y redujo la pérdida de manera constante, mientras que en validación sufrió de un rápido estancamiento, esto puede ser señal de overfitting, donde la red calcó los ejemplos y no los patrones.
Contribución creada por Sebastián Franco Gómez.