Carga de Bases de Datos JSON desde GCP en Google Colab
Clase 4 de 28 • Curso Profesional de Redes Neuronales con TensorFlow
Contenido del curso
Manejo y preprocesamiento de datos para redes neuronales
- 3

Carga y Procesamiento de Bases de Datos en Inteligencia Artificial
02:48 min - 4

Carga de Bases de Datos JSON desde GCP en Google Colab
Viendo ahora - 5

Codificación Base64 y Gestión de Imágenes en Google Colab
12:50 min - 6

Preprocesamiento y limpieza de datos
12:15 min - 7

Keras datasets
10:14 min - 8

Datasets generators
18:36 min - 9

Aprende a buscar bases de datos para deep learning
04:14 min - 10

Cómo distribuir los datos
06:50 min - 11

Crear la red neural, definir capas, compilar, entrenar, evaluar y predicciones
14:35 min
Optimización de precisión de modelos
- 12

Métodos de regularización: overfitting y underfitting
11:16 min - 13

Recomendaciones prácticas para ajustar un modelo
12:00 min - 14

Métricas para medir la eficiencia de un modelo: callback
08:18 min - 15

Monitoreo del entrenamiento en tiempo real: early stopping y patience
07:04 min - 16

KerasTuner: construyendo el modelo
13:54 min - 17

KerasTuner: buscando la mejor configuración para tu modelo
08:45 min
Almacenamiento y carga de modelos
Fundamentos de aprendizaje por transferencia
Resultados de entrenamiento
Resumen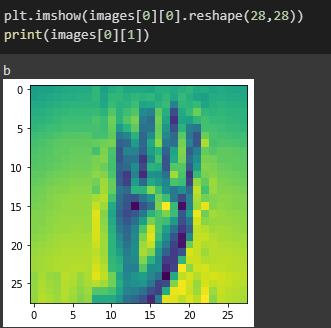
A continuación vamos a cargar una base de datos en formato JSON que estará almacenada en GCP (Google Cloud Platform). Trabajaremos sobre Google Colab. Crea un Notebook, configúralo y prepárate.
Cómo descargar bases de datos desde la web
Para esta ocasión usaremos la librería os y zipfile para la manipulación y procesamiento del dataset.
import os import zipfile
Descargaremos el repositorio desde la locación en GCP, usaremos el comando wget para extraer el archivo, agregaremos la opción —no-check-certificate para omitir certificaciones y guardaremos la salida en la carpeta tmp con el nombre databasesLoadData.zip.
!wget --no-check-certificate https://storage.googleapis.com/platzi-tf2/databasesLoadData.zip \ -O /tmp/databasesLoadData.zip
Obtendremos la locación del archivo comprimido y crearemos una referencia en memoria con una instancia zipfile en modo lectura, posteriormente extraeremos el contenido y lo nombraremos de la misma manera sin extensión dado que será un directorio. Finalmente cerramos la instancia y tendremos nuestro dataset inicial listo para manipular.
local_zip = "/tmp/databasesLoadData.zip" zip_ref = zipfile.ZipFile(local_zip, "r") zip_ref.extractall("/tmp/databasesLoadData") zip_ref.close()
Si navegamos en el directorio de archivos, podremos explorar el contenido de nuestra descarga, tendrá 4 carpetas, donde las 2 más importantes serán las de base64 (a trabajar próximamente) y la de formato JSON.
Si nos adentramos al contenido del dataset en formato JSON, encontraremos con objetos con 2 claves diferentes: Content (que contiene el link de la imagen) y label (que expresa la letra a la que se refiere).
{"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/29_B.jpg","label":"b"} {"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/30_B.jpg","label":"b"} {"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/95_B.jpg","label":"b"} {"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/58_A.jpg","label":"a"} {"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/50_A.jpg","label":"a"} {"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/46_A.jpg","label":"a"} {"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/3_C.jpg","label":"c"} {"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/32_C.jpg","label":"c"} {"content": "https://storage.googleapis.com/platzi-tf2/img_mnist/2_C.jpg","label":"c"}
Cómo hacer la deserialización de los datos
Para el procesamiento del dataset haremos uso de varios módulos de Python, donde JSON, codecs, requests y bytesIO nos ayudarán al proceso de peticiones mientras que el resto nos serán útiles a nivel de manipulación y representación.
import json import codecs import requests import numpy as np from PIL import Image from io import BytesIO %matplotlib inline import matplotlib.pyplot as plt
Determinamos la ubicación del dataset a cargar.
url = "/tmp/databasesLoadData/sign_mnist_json/data.json"
Creamos un array donde guardaremos los JSON, posteriormente abriremos el archivo, lo recorreremos línea a línea y lo guardaremos en formato de diccionario, finalmente, verificamos la cantidad de imágenes encontradas correlacionando el tamaño del array.
data_json = [] with codecs.open(url, "rU", "utf-8") as js: for line in js: data_json.append(json.loads(line)) print(f'{len(data_json)} imagenes encontradas')
Si verificamos el contenido nos encontraremos con un diccionario con las claves content y label y su respectivos valores.
data_json[0] {'content': 'https://storage.googleapis.com/platzi-tf2/img_mnist/29_B.jpg', 'label': 'b'}
Con los datos aislados, podemos descargar cada imagen, por lo que haremos una petición HTTP, la encapsularemos en un objeto BytesIO, será interpretado como una imagen y finalmente se transformará en un array de Numpy.
Guardaremos en la lista de imágenes un array de 2 elementos donde el primero será la representación matricial de la imagen y el segundo la etiqueta.
images = [] for data in data_json: response = requests.get(data["content"]) img = np.asarray(Image.open(BytesIO(response.content))) images.append([img, data["label"]])
Para verificar la integridad del contenido lo mostraremos en pantalla con matplotlib, donde tomaremos la imagen y la redimensionaremos al tamaño esperado (de ser requerido), paralelamente tomaremos la etiqueta y las obtendremos ambas en pantalla.
plt.imshow(images[0][0].reshape(28,28)) print(images[0][1])
Con esto hemos completado el proceso, desde la mera descarga del archivo a su deserialización y manipulación interna en el scope de Python.
Contribución creada por Sebastián Franco Gómez.