Cuándo utilizar aprendizaje por transferencia
Clase 21 de 28 • Curso Profesional de Redes Neuronales con TensorFlow
Contenido del curso
Manejo y preprocesamiento de datos para redes neuronales
- 3

Carga y Procesamiento de Bases de Datos en Inteligencia Artificial
02:48 min - 4

Carga de Bases de Datos JSON desde GCP en Google Colab
10:25 min - 5

Codificación Base64 y Gestión de Imágenes en Google Colab
12:50 min - 6

Preprocesamiento y limpieza de datos
12:15 min - 7

Keras datasets
10:14 min - 8

Datasets generators
18:36 min - 9

Aprende a buscar bases de datos para deep learning
04:14 min - 10

Cómo distribuir los datos
06:50 min - 11

Crear la red neural, definir capas, compilar, entrenar, evaluar y predicciones
14:35 min
Optimización de precisión de modelos
- 12

Métodos de regularización: overfitting y underfitting
11:16 min - 13

Recomendaciones prácticas para ajustar un modelo
12:00 min - 14

Métricas para medir la eficiencia de un modelo: callback
08:18 min - 15

Monitoreo del entrenamiento en tiempo real: early stopping y patience
07:04 min - 16

KerasTuner: construyendo el modelo
13:54 min - 17

KerasTuner: buscando la mejor configuración para tu modelo
08:45 min
Almacenamiento y carga de modelos
Fundamentos de aprendizaje por transferencia
Resultados de entrenamiento
Resumen

Utilizar configuraciones creadas por otros devs será de mucha utilidad y te ahorrará tiempo, pero su uso no siempre será mandatorio, exploraremos algunas razones de cuándo y por qué utilizarlas.
¿Cuándo utilizar modelo pre-entrenados?
Podemos usar modelos pre-entrenados cuando tratemos problemas de procesamiento de lenguaje natural y visión computarizada, pasa ambos casos se suelen implementar arquitecturas robustas con altísimas cantidades de iteraciones, por lo que siempre será ideal dedicar tiempo a investigar qué configuraciones se han implementado similares a tu caso de uso.
¿Por qué usar aprendizaje por transferencia?
El aprendizaje por transferencia será especialmente útil cuando tengas muy pocos datos, dado que no tendrás que enseñar al modelo desde 0 las abstracciones, también te permitirá generar iteraciones muy rápidas (en caso de que debas generar un prototipo en poco tiempo o quieras tantear la calidad de tus datos).
Estos modelos ya han generalizado las features, por lo que se podrán adaptar a tus necesidades en pocas iteraciones.
Si deseas enriquecerte con la documentación de algunas implementaciones, puedes leer los paper de YOLO V3 y AlexNet, algunas de las configuraciones más usadas en redes convolucionales.
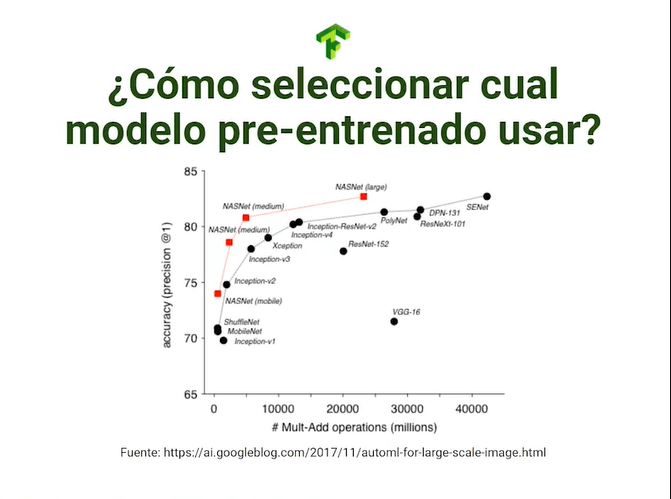
¿Cómo saber cuál modelo seleccionar?
Las 2 métricas a seguir a la hora de seleccionar un modelo serán las de precisión y complejidad, donde según tu contexto deberás elegir cuál es más relevante.
Si tu modelo requiere de reacción rápida entonces podrás sacrificar un poco de precisión por velocidad (este es el ejemplo de detección de objetos en vivo, como cámaras de seguridad o vehículos autónomos).
Si la precisión lo es todo (como en la clasificación de células cancerígenas) puedes darte el lujo de correr un modelo por bastante tiempo con el fin de obtener resultados precisos.
Puedes guiarte en la noción de precisión vs cantidad de operaciones para elegir tu modelo, como siempre, tu determinarás las prioridades de tu modelo.
Reto de selección de modelos
Para esta ocasión te enfrentarás a 2 situaciones de clasificación de imágenes y tu tarea será elegir cuál modelo pre-entrenado usarás. La primer situación será la de detectar pájaros en vuelo mediante la cámara de un dron y la segunda será la detección del cáncer en diferentes órganos del cuerpo.
Contribución creada por Sebastián Franco Gómez.