Preprocesamiento y limpieza de datos
Clase 6 de 28 • Curso Profesional de Redes Neuronales con TensorFlow
Contenido del curso
Manejo y preprocesamiento de datos para redes neuronales
- 3

Carga y Procesamiento de Bases de Datos en Inteligencia Artificial
02:48 min - 4

Carga de Bases de Datos JSON desde GCP en Google Colab
10:25 min - 5

Codificación Base64 y Gestión de Imágenes en Google Colab
12:50 min - 6

Preprocesamiento y limpieza de datos
Viendo ahora - 7

Keras datasets
10:14 min - 8

Datasets generators
18:36 min - 9

Aprende a buscar bases de datos para deep learning
04:14 min - 10

Cómo distribuir los datos
06:50 min - 11

Crear la red neural, definir capas, compilar, entrenar, evaluar y predicciones
14:35 min
Optimización de precisión de modelos
- 12

Métodos de regularización: overfitting y underfitting
11:16 min - 13

Recomendaciones prácticas para ajustar un modelo
12:00 min - 14

Métricas para medir la eficiencia de un modelo: callback
08:18 min - 15

Monitoreo del entrenamiento en tiempo real: early stopping y patience
07:04 min - 16

KerasTuner: construyendo el modelo
13:54 min - 17

KerasTuner: buscando la mejor configuración para tu modelo
08:45 min
Almacenamiento y carga de modelos
Fundamentos de aprendizaje por transferencia
Resultados de entrenamiento
Resumen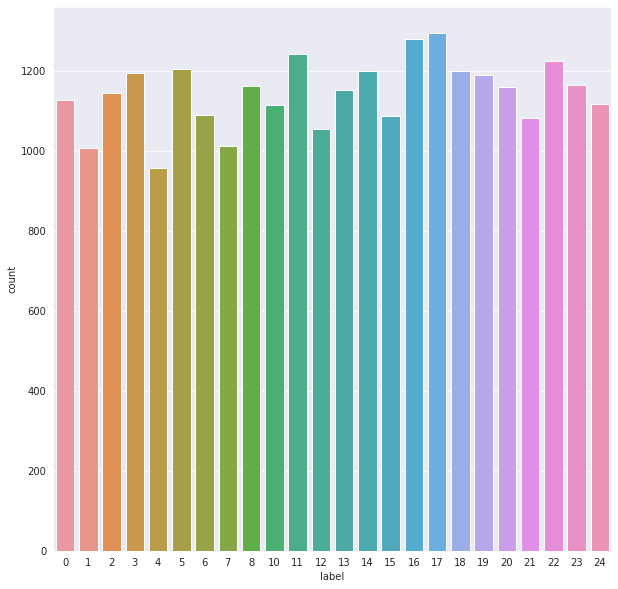
El preprocesamiento de los datos es de las etapas más importantes en cualquier proyecto de data science, principalmente porque es un proceso altamente difícil de automatizar y requiere de creatividad e intelecto humano para hacerse correctamente.
Esta etapa determinará la calidad final de tu modelo, por lo que no deberías temer en invertir el tiempo necesario.
Carga y análisis exploratorio de datos
Para esta ocasión usaremos una versión del dataset mnist en CSV que no está limpio, es decir, tiene datos faltantes e incongruencias que solucionaremos a continuación.
train = pd.read_csv('/tmp/databasesLoadData/sign_mnist_train/sign_mnist_train_clean.csv')
Empezaremos con un poco de análisis exploratorio, vamos a entender la densidad de los datos, donde gracias a matplotlib y seaborn podemos obtener una gráfica de la distribución de las etiquetas.
plt.figure(figsize=(10,10)) sns.set_style("darkgrid") sns.countplot(train['label'])
En general el dataset se encuentra balanceado, donde cada etiqueta tiene de 900 a 1200 ejemplos en promedio.
Limpieza de los datos
Lo primero a realizar será separar las etiquetas de las imágenes, donde bastará con aislar esta columna en concreto en nuevas variables.
y_train = train['label'] y_test = test['label'] del train['label'] del test['label']
Para obtener información general del dataset podemos usar el método info que nos dará detalles de la estructura, su contenido y los tipos de datos que almacena.
train.info() <class 'pandas.core.frame.DataFrame'> RangeIndex: 27455 entries, 0 to 27454 Columns: 784 entries, pixel1 to pixel784 dtypes: object(784) memory usage: 164.2+ MB
De la misma manera, podemos analizar específicamente cada columna con el atributo dtypes.
train.dtypes pixel1 object pixel2 object pixel3 object pixel4 object pixel5 object ... pixel780 object pixel781 object pixel782 object pixel783 object pixel784 object Length: 784, dtype: object
Si queremos conocer qué etiquetas hay, podemos hacer uso de la función unique de numpy.
unique_val = np.array(labels) np.unique(unique_val) array([ 0, 1, 2, 3, 4, 5, 6, 7, 8, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22, 23, 24])
Podemos verificar si tenemos valores nulos en nuestra base de datos, esto nos dará información relacionada a negocio que puede ser valiosa, por lo que esta acción no solo ayuda a limpiar el dataset sino a comprender el posible origen del problema.
train.isnull().values.any() False
Podemos buscar datos duplicados con el método duplicated del dataframe, esto nos retornará una fila por cada elemento.
train[train.duplicated()]
Para borrar registros haremos uso del método drop que recibe como argumentos los index de los elementos a borrar.
train = train.drop([317, 487, 595, 689, 802, 861], axis = 0)
Entre los datos duplicados encontramos uno que traía letras (algo ilógico para imágenes entre 0 y 255), por lo que lo buscaremos y eliminaremos.
train[train['pixel1'] == "fwefew"] 727 train = train.drop([727], axis = 0)
Preprocesamiento y optimización
El paso final será normalizar los datos para sintetizarlos desde el rango inicial al rango 0-1, para esto debemos convertir todos los datos en valores numéricos y luego aplicar la operación.
train = train.astype(str).astype(int) train = train / 255 test = test / 255
Si verificamos el dataset limpio obtendremos 784 columnas con valores entre 0 y 1.
train.head() 5 rows × 784 columns
Estos datos finales son mucho más procesables que los iniciales, por lo que tu rendimiento final se verá afectando positivamente.
Recuerda siempre dedicar una parte importante del tiempo de desarrollo en revisión y limpieza de datos para obtener resultados exponencialmente mejores.
Contribución creada por Sebastián Franco Gómez.