
Las bases de datos en memoria (IMDB - Por sus siglas en inglés) se han convertido recientemente en soluciones disponibles para grandes empresas que requieren un alto nivel de rendimiento y procesamiento de gran cantidad de datos, además de evitar la latencia de I/O del disco duro tradicional. La latencia se ha vuelto inaceptable para las empresas que requieren respuesta en tiempo real y solicitudes de servicio en cuestión de segundos.
Estudios recientes han mencionado que creamos 2,5 trillones de bytes de datos cada día, y aproximadamente el 90% de todos los datos en el mundo de hoy se crearon en los últimos años. Los datos son generados por teléfonos inteligentes, publicaciones en las redes sociales, mapas, sensores, blogs, máquinas, etc.
Hoy en día, la competencia entre compañías es por recuperar datos rápidamente y procesar gran cantidad de datos, ya que los datos ahora están abiertos y disponibles en casi todas partes, y la carrera es por utilizar estos recursos para ofrecer ventajas competitivas a las empresas. Las aplicaciones del mundo real que procesan esta cantidad de datos, considerando la variedad de datos estructurados y no estructurados, se han convertido en una necesidad persistente y las IMDB ofrecen una solución adecuada, ya que ayudan en la toma de decisiones y planificación estratégica durante el análisis de Big Data y producción de informes adecuados en marcha.
La tarea de procesar Big Data rápidamente y obtener informes y respuestas en tiempo real es muy vital para las empresas cuando la latencia cuesta millones de dólares. Estudios recientes han demostrado que un segundo de retraso le cuesta a Amazon 1.6 billones de dólares anuales; Google pierde 8 millones de búsquedas por día por un segundo de retraso. Es obvio que este retraso en la aplicación y el procesamiento de datos ya no es aceptable.
La investigación en IMDB comenzó a principios de los años 80 como resultado de las mejoras y el bajo costo de la memoria principal de la computadora. El objetivo principal detrás de estos estudios de investigación fue alojar toda la base de datos en la memoria principal de la computadora para un acceso rápido y análisis en tiempo real.
Memoria Volátil y No Volátil
Memoria Volátil Es una memoria de computadora que requiere encendido para mantener sus contenidos; si la fuente de poder está apagada, los contenidos se pierden.
RAM (Random Access Memory) es el tipo principal de memoria de la computadora personal, hay 2 tipos: SRAM y DRAM. El costo promedio de una memoria de un gigabyte en 1980 fue de $ 6,328,125 y bajó a $ 4,37 por gigabyte en 2015, la capacidad de memoria y el ancho de banda se han duplicado cada tres años. Este desarrollo llevó a las compañías de TI a diseñar un nuevo sistema de administración de bases de datos en memoria para manejar Big Data.
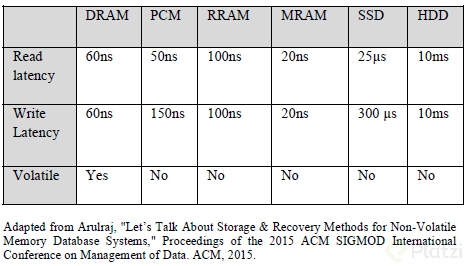
Memoria No Volátil NVRAM y ROM son ejemplos de memoria no volátil utilizada por las empresas de TI emergentes para alojar toda la base de datos en NVRAM; es más lento que DRAM, pero proporciona más capacidad con almacenamiento persistente si la alimentación está desactivada, como SSD (Solid-State Drive) y PCM (Phase Change Memory). La siguiente tabla compara la velocidad de diferentes tipos de tecnologías de almacenamiento:
Mejoras en IMDB
Indexación
El acceso a los datos en la memoria principal se puede lograr mediante el uso de indexación de estructura de árbol o funciones hash. T-tree es un tipo de árbol equilibrado que se utiliza específicamente para IMDB. Los índices de IMDB almacenan solo el puntero a los datos, no los datos, porque las colecciones de datos existen en la memoria principal.
Estudios recientes han demostrado que hay muchas técnicas de indexación que se han implementado para IMDB, tales como: B±Tree, wB±tree, T-Tree, DCB-Tree, BD-Tree, FAST, HHB+tree y PI.
B±Tree ha sido ampliamente utilizado en el sistema IMDB y se ha demostrado que tiene una gran sobrecarga de escritura y operaciones de vaciado de la memoria caché de la CPU, propusieron un nuevo tipo de árbol B+tree llamado wB±tree. Los resultados experimentales mostraron que la velocidad de búsqueda de wB±tree aumenta en DRAM y NVM.
La indexación basada en árbol, ha sido modificada y mejorada mediante el ahorro de ancho de banda y almacenamiento mediante la técnica de poda para eliminar los nodos de las hojas.
DCB-Tree (Delta Cache B-tree) fue presentado para una estructura de índice de memoria principal eficiente, mostró que el tamaño del índice se reduce al 80% en su mejor momento y en un 30% en el peor de los casos.
El HHB+tree (técnica de índice de hash híbrido) es una técnica que minimiza las operaciones de división utilizando el índice de hash expandido y también está diseñado para el almacenamiento flash NAND.
El estudio más reciente para la indexación en memoria propuso una nueva estructura de índice, que es PI (índice basado en la lista de saltos de la memoria paralela). En esta técnica, las consultas solicitadas se recopilan y se distribuyen de manera disjunta para varios subprocesos para su procesamiento a fin de evitar el uso de latches.
Control de Concurrencia
Las múltiples transacciones en múltiples servidores y la escalabilidad de datos aumentan la necesidad de un mecanismo eficiente de Control de Concurrencia. Varios esquemas se utilizan en IMDB.
El control de concurrencia de varias versiones (MVCC) es ampliamente utilizado. Este omite el uso de bloqueo en la base de datos y mejora el rendimiento mediante la creación de una nueva versión de los datos actualizados y la marca como la más reciente, mientras que los datos antiguos se marcan como obsoletos mediante las marcas de tiempo. De esta forma, los lectores de datos nunca bloquean a los autores de los mismos datos.
Otro esquema es el Control de Concurrencia Optimista (OCC). Este método supone que se pueden completar múltiples transacciones sin interferir entre sí. Antes de confirmar los datos, cada transacción verifica que ninguna otra transacción haya modificado los datos que ha estado leyendo. Si comprueba las modificaciones en conflicto, la transacción se revertirá y se puede reiniciar.
Replicación
Las IMDB deben garantizar alta disponibilidad y escalabilidad, ya que la cantidad de usuarios y máquinas se ha incrementado, y los datos crecen dramáticamente al replicar la base de datos para crear una base de datos secundaria en máquinas remotas u otros medios de almacenamiento. Esto garantizará una recuperación rápida de la base de datos en caso de que ocurra un problema importante en la base de datos principal, y un procesamiento de consulta de distribución entre múltiples núcleos o máquinas.
La base de datos de llaves de Google es una base de datos escalable y multiversión distribuida globalmente y replicada sincrónicamente. Los datos se distribuyen automáticamente y se migran en múltiples nodos en los centros de datos de todo el mundo. Está diseñado para escalar hasta millones de máquinas y centros de datos.
Sistemas de IMDB
Hay muchas bases de datos en memoria comerciales. Dichas bases de datos incluyen el servidor SQL Hekaton, Oracle TimesTen, SAP Hana, VoltDB, SolidDB, IBM DB2 y más. Además, se tienen IMDB open-source gratuitas, como MonetDB, FastDB, H-Store y Crescando.
Referencia: Najajreh, J y Khamayseh, F. “Contemporary Improvements of In-Memory Databases: A Survey”. 2017, 8th International Conference on Information Technology (ICIT).
Fundamentos de Bases de Datos 2017
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


