Muchas veces al trabajar con MongoDB nos vamos a topar con escenarios donde necesitaremos procesar los datos que tenemos almacenados, y que solo con las operaciones CRUD se hace bastante difícil de lograr. Para estos casos, se realizan operaciones de agregación sobre los datos, las cuales permiten operar y agrupar datos en base a las necesidades que presenten nuestras aplicaciones. MongoDB cuenta con tres maneras de realizar operaciones de agregación: el pipeline de agregación, la función map-reduce, y métodos de agregación de un solo propósito.
A lo largo de este tutorial nos enfocaremos en el uso del pipeline de agregación y los distintos elementos que se ven involucrados en el mismo. Trabajaremos con el mismo modelo de datos del curso pero con solo una pequeña modificación: haremos un parsing a float del campo “total_supply”, con el fin de poder realizar operaciones aritméticas sobre dicho campo. Para lograr lo anterior, podemos agregar la siguiente línea en la función save_ticker del agente de cryptongo:
ticker_data['total_supply'] = float(ticker_data['total_supply'])
Primero que nada, el pipeline (tubería en español) consiste en ir pasando nuestros datos por una serie de etapas en las cuales se modifica, agrupa u opera sobre los mismos; los datos resultantes pueden pasar a una nueva etapa y repetir este proceso tantas veces se quiera hasta obtener los resultados finales que se necesiten.
Las etapas a lo largo del pipeline tienen forma de documentos, y trabajan con operadores nativos de Mongo para hacer la transformación de los datos de manera eficiente, así como cuando se hacen consultas usando los operadores $gt o $lt vistos en el curso.
Es importante destacar, que durante el proceso de agregación se irá operando sobre cada documento y estos no pueden acceder a datos de otros documentos de la misma colección. Sin embargo, con $group se disponen de acumuladores que permiten mantener información de cada uno de los documentos analizados en el pipeline, lo cual es de bastante utilidad cuando queremos calcular máximos, mínimos, apariciones de datos, entre otros.
Al hacer uso del método aggregate, se pasa toda la colección (es decir todos los documentos que están almacenados) al pipeline, por lo cual es altamente recomendado hacer uso de la etapa $match para filtrar los documentos en caso de que no se necesite operar con cada uno de ellos. Asimismo, otra de las ventajas que obtenemos al usar $match o $sort al principio del pipeline es que podemos aprovechar los índices de la colección, lo cual mejora el rendimiento general de la operación.
Para usar el pipeline de agregación, haremos uso del método aggregate, el cual tiene la siguiente forma:
db.collection.aggregate(pipeline, options)
En pipeline se definen las operaciones o etapas por las cuales pasaran los datos, pueden ser elementos separados o un arreglo que contenga cada una de ellas; en caso de optar por definir cada operación o etapa en elementos separados, no se podrán definir las opciones. A su vez, en el documento options se definen las opciones adicionales que tratará el método de agregación.
A modo de ejemplo, supongamos que en nuestra colección tickers tenemos los siguientes documentos:
[
{
"id": "bitcoin",
"total_supply": 55
},
{
"id": "bitcoin",
"total_supply": 80
},
{
"id": "dogecoin",
"total_supply": 30
},
{
"id": "ethereum",
"total_supply": 45
}
]
Si modificamos los datos con la agregación descrita a continuación:
db.tickers.aggregate([
{$match: {total_supply: {$gt: 30} } },
{$group: {_id: "$id", supply: {$sum: "$total_supply"}}}
])
Visualmente lo que está pasando es lo siguiente:
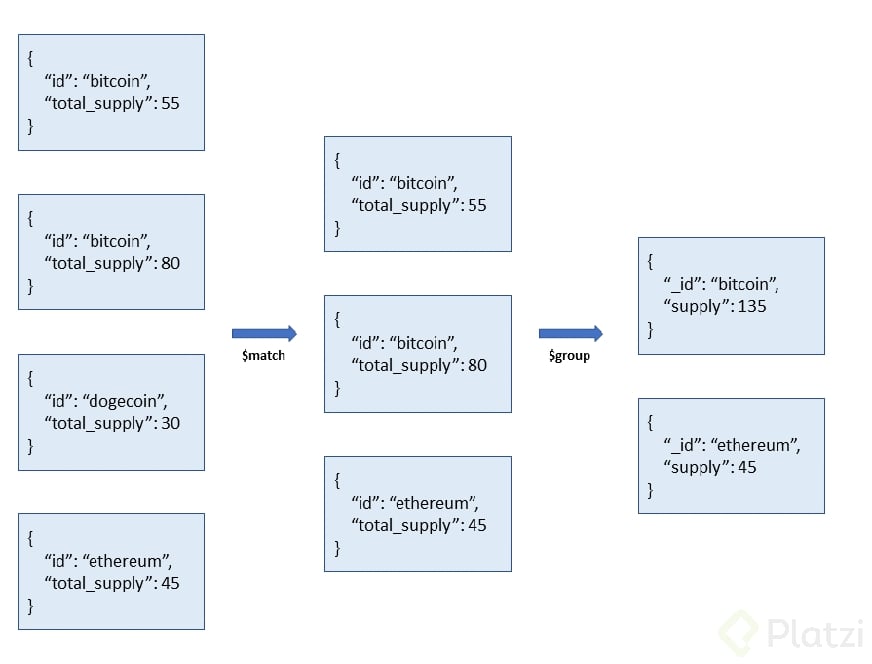
Primero, mediante la etapa de $match se seleccionaran los documentos que tengan un “total_supply” mayor a 30. Luego de aplicar el filtro, aplicamos la etapa de $group para agrupar los documentos en base al _id que le especifiquemos al operador (importante, al usar $group es requerido que le definamos un valor para _id, debido a que es lo que permite la agrupación de los documentos).
Manos a la obra
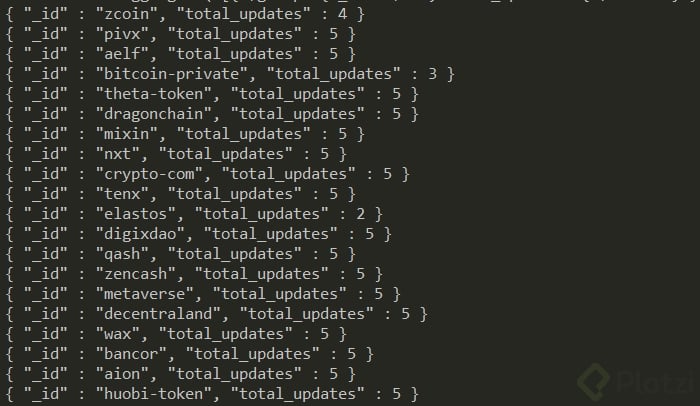
Ahora que tenemos suficiente base teórica, es momento de empezar a trabajar con datos verdaderos en nuestra base de datos. Si quisiéramos saber las veces que se repiten cada una de las criptomonedas en nuestra base de datos podríamos hacer lo siguiente:
db.tickers.aggregate( [{ $group: { _id: "$id", total_updates: { $sum: 1 } }}])
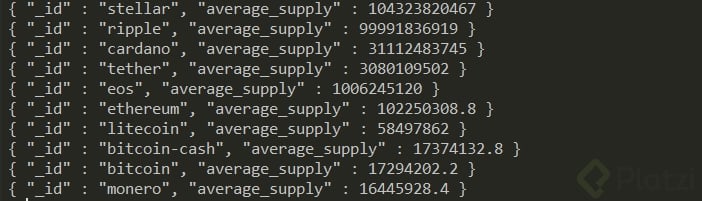
Como segundo ejemplo, si quisiéramos obtener el promedio de suministro (supply) de las criptomonedas con un rank menor a 10, y que los resultados estén ordenados de mayor a menor en base al campo average_supply que se genera en la etapa de $group, hacemos lo siguiente:
db.tickers.aggregate([
{ $match: { rank: { $lte: 10 } } },
{ $group: { _id: "$id", average_supply: { $avg: "$total_supply" } }},
{ $sort: { average_supply: -1 } }
])
Luego de los dos ejemplos anteriores, es probable que tengas dudas acerca del símbolo de dólar ($), y es que MongoDB usa strings que comienzan con dicho símbolo para referenciar a campos del documento que se esté analizando. En el ejemplo anterior, “$id” hace referencia al valor del campo id del documento que se está tratando en ese momento (recordemos que toda nuestra colección pasa por el pipeline, pero se trata documento por documento).
Además de las etapas que hemos visto a lo largo del tutorial, me gustaría comentarles que hay muchas más y les queda como reto ir probando cada una de ellas. Sin embargo, hay dos etapas que quisiera introducirles debido a que han sido de gran utilidad en mis aplicaciones:
$lookup: permite obtener los documentos de otra colección a lo que se les tiene una referencia, los anexa en un campo de tipo arreglo y permite tratarlo en la siguiente etapa. En ocasiones, tendremos referencias a otros documentos y si el driver del lenguaje que usemos no nos brinda una manera de hacer esta clase de join, la etapa $lookup es la manera correcta de hacerlo.
$unwind: Desarma un campo de tipo arreglo del documento que se está analizando, y genera un documento nuevo para cada elemento del arreglo. Es de suma utilidad cuando se tienen arreglos de documentos, una vez que se tiene cada subdocumento se pueden tratar de manera individual.
Conclusiones
Al trabajar con las bases de datos es común que nos encontremos con solicitudes de información que no se logren con sólo las operaciones CRUD tradicionales y es justo donde entra el pipeline de agregación. Luego de seguir este tutorial, cuentas con suficiente base para investigar más y dominar de principio a fin esta herramienta, la cual es de gran utilidad para el manejo de bases de datos en MongoDB. Espero que les sea de gran utilidad.




Muchas gracias por este tutorial, ¡es realmente revelador y significativo para mí! drift hunters
Oh, great, your article provided me with useful information and a fresh perspective on the subject. I love Sonic games!
Great explication! thanks!
Esta lectura también está buenísima: https://platzi.com/blog/agregaciones-con-mongodb-y-rails/.