
Cuando nos proponemos establecer los promedios mensuales de una variable a partir de una serie de datos históricos con frecuencias de medición diaria, su obtención mediante Query’s del lenguaje SQL parece una labor sencilla. Sin embargo, para obtener datos confiables no resulta una tarea de un solo paso.
En este caso desarrollo la ruta que encontré para solucionar está necesidad de información. Mí caso de estudio fue el análisis de series históricas de lluvias diarias de una estación meteorológica ubicada en Colombia.
Contamos con mediciones desde el día 15 de octubre de 1973 hasta el 31 de diciembre de 2021. En total, la serie histórica cuenta con 17.187 registros de lluvias medidas cada 24 horas. A partir de estos datos, queremos establecer en promedio cuánto llueve en cada mes del año en el territorio que abarca esta estación. Nuestro Dataset (el cual es de libre descargar dispuesto por IDEAM en Colombia) cuenta con los siguientes campo o columnas de información:
['CodigoEstacion', 'NombreEstacion', 'Latitud', 'Longitud', 'Altitud', 'Categoria', 'Entidad', 'AreaOperativa', 'Departamento', 'Municipio', 'FechaInstalacion', 'FechaSuspension', 'IdParametro', 'Etiqueta', 'DescripcionSerie', 'Frecuencia', 'Fecha', 'Valor', 'Grado', 'Calificador', 'NivelAprobacion'],
Nuestra consulta de salida queremos que agrupe el nombre de cada mes con su promedio de lluvias. De el Dataset de entrada, solo utilizaremos en nuestro Query los campos ‘Fecha’ y ‘Valor’, porque todos los datos pertenecen a una sola estación. En casa de tener más de una estación, se requeriría agregar el campo ‘CodigoEstacion’ o ‘NombreEstacion’ para agrupar los resultados para cada estación.
Sí ejecutamos el siguiente código
SELECT MONTHNAME(Fecha) AS mes, AVG(Valor) AS lluvia_mensual
FROM estaciones_ideam.`momil [13070020]`
GROUPBY mes;
La tabla que resulta de este Query es:
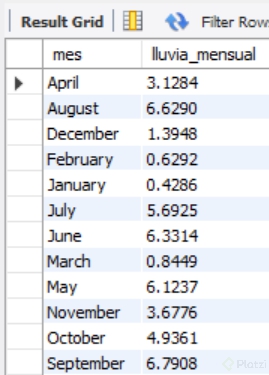
Este Query tiene dos inconvenientes, el más importante es que los resultados de la columna lluvia_mensual muestra en promedio cuánto llueve en un día dentro de cada mes, y el otro inconveniente es que los meses no están organizados por su orden anual, sino alfabético. Ante esta situación, mí solución fue ejecutar Query’s anidados para organizar la información y luego agrupar en sumatorias mensuales de cada año, que al final me permitan extraer el promedio para cada mes.
Como primer paso ejecutó el siguiente Query
CREATEVIEW p_mensual_transitiva AS
SELECTYEAR(`estaciones_ideam`.`momil [13070020]`.Fecha) AS ano, MONTH(`estaciones_ideam`.`momil [13070020]`.Fecha) AS idmes, MONTHNAME(`estaciones_ideam`.`momil [13070020]`.Fecha) AS mes, `estaciones_ideam`.`momil [13070020]`.Valor AS Valor
FROM estaciones_ideam.`momil [13070020]`;
El código inicia con el comando de creación de una vista o consulta, porque MySQL no permite crear la consulta final si tiene varios Querys anidados dentro de mismo código. Se debe construir un Query a la vez, y la anidación se da al referenciarlo en el Query subsiguiente.
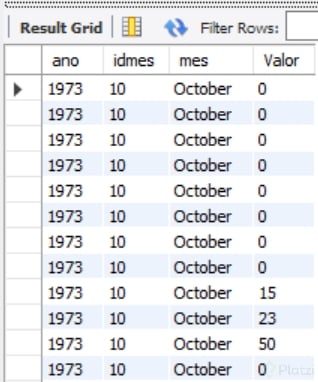
Es Query sigue mostrando los resultados diarios dela serie histórica de lluvias. Con la diferencia de que cada valor tiene asociado el atributo del mes en que se midió. El año se invoca para que en los siguientes Query’s no se confundan mismos meses de distintos años. Y mucha atención, en el atributo mes invoqué dos funciones: la función MONTH que me devuelve el número cardinal del mes dentro de un año natural del campo ‘Fecha’ (por ejemplo, si la fecha es 27/04/1986 el resultado de MONTH es ‘4’, porque se realizó en abril que es el mes 4 del año), y la segunda función es MONTHNAME que devuelve solo el nombre del mes. Con estos dos atributos del mes se puede ordenar el resultado final en orden cronológico dentro de un año.
El resultado de este Query es el siguiente:
Una vez creada esta Viewse referenciará como Query anidada en el siguiente código
CREATEVIEW p_mensual_transitiva2 AS
SELECT ano, idmes, mes, COUNT(Valor) n_registros, SUM(Valor) p_mensual
FROM estaciones_ideam.p_mensual_transitiva
GROUPBY ano, mes
HAVING n_registros >= 28;
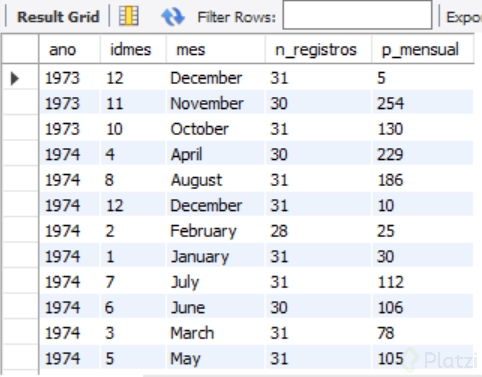
Con esta consulta se pueden agrupar las sumas de lluvias para cada mes a lo largo de los años que integran la serie de datos, es el paso último para obtener el promedio mensual.
Nótese que se uso el comando HAVING para condicionar que solo muestre resultados si el conteo de registros mensuales es mayor a 28, porque suele suceder en el caso de estaciones meteorológicas que en algunos periodos no se registrasen mediciones por avería de equipos o ausencia dela persona encargada de hacer las mediciones. Se podrá argumentar que el HAVING sería más efectivo si lo condiciono con la función MAX(COUNT(Valor)), pero en el mes de febrero los años bisiestos tienen 29 días, y esa condición descartaría la mayoría de años donde son 28 días. En contra, se podría argumentar que en meses de duración de 30 o 31 días que no estén completos, pero cumplan con la condición >= 28 se incluyan, estadísticamente es válido al tener un rango de confiabilidad superior al 90%.
El resultado del Query es el siguiente:
Surtidos estos pasos, calcular el promedio mensual de lluvias mediante un Query será una acción sencilla. Se crea la tabla deseada con el siguiente código:
CREATEVIEW p_mensual_promedio AS
SELECT idmes, mes, AVG(p_mensual)
FROM estaciones_ideam.p_mensual_transitiva2
GROUPBY mes
ORDERBY idmes;
Obteniendo el siguiente VIEW
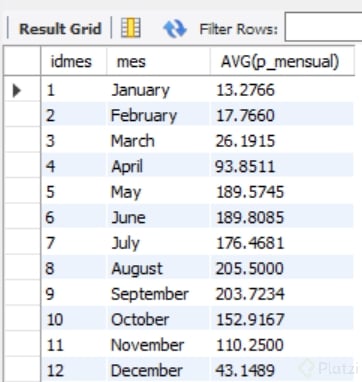
Hemos logrado llegar a la información deseada en tres (3) sencillos pasos. En este caso podemos ver como usar Query’s anidados para ir dándole el orden a los datos hasta lograr una agregación final que responda a la necesidad. Recordando que en MySQL si deseamos que la consulta de Query’s anidados nos arroje una tabla dinámica sobre la cual descargar la data o seguir operando, cada Query se debe generar como vista independiente e ir anidando a través dela referencia de los VIEW creados.
Este caso de estudio se puede ampliar a otros campos, por ejemplo conocer el promedio de ventas mensuales de cada mes de año si tenemos los registros históricos de ventas diarias.
Esta fue mí ruta de solución, comprendo que los Query’s anidados pueden ser contraproducentes al ocupar mucha memoria si los datos son lo suficientemente grandes. Sí conoces o te ideas una ruta más corta para llegar a esta solución ¡No dudes dejarla en los comentarios!
Curso de Fundamentos de Bases de Datos 2019
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE



