
Estructuras de datos en JS 💛
¡Las estructuras de datos es un tema tan amplio y tan hermoso, yo las aprendí por mi cuenta a medida que aprendía a programar y me interesaba por los algoritmos, este curso hacía falta!
Las usaremos mucho ya que son las que nos permitirán solucionar distintos problemas que nos encontremos como devs, es la forma en que podemos estructurar, almacenar y usar la data que tengamos.
No hay ninguna estructura mejor que otra ni perfecta
Cada una cumple una función y resuelve un problema en particular, es nuestro deber y responsabilidad darles el mejor uso posible, y esto dependerá del problema que tengamos y como queramos abórdalo para solucionarlo. Esto lo podemos lograr entendiendo como funcionan cada estructura en su base conceptual
Memoria y como se guardan los datos
Ok para entender mejor esto es necesario que conozcas como gestiona JS en particular, el espacio en memoria, donde se almacena los valores de las variables, funciones y todo aquello que no sea un valor primitivo es en el memory heap (los valores primitivos se almacenan en el call stack dentro del scope en el que se encuentre las funciones o variables) y como se mandan a llamar es con el call stack, ya que aquí se guardan las referencias a las funciones con sus respectivos scopes locales.
- Cabe mencionar que acceder al call stack es mucho mas rápido que al memory heap porque la información en el memory heap no se guarda de manera lineal, es decir que la info se guarde de manera aleatoria.
- En JS cuando inicializamos una variable con otra que tiene como valor un objeto, esta solo recibe como valor la referencia en memoria al objeto al cual apunta dicha variable que contiene el objeto originalmente.
- Si el objeto tiene atributos, estos se guardan en la posición en memoria reservada para ese objeto.
- En JS los objetos pueden contener a otros objetos dentro, en este caso, en la posición en memoria del objeto padre, se guarda también una referencia a otras posiciones en memoria, estos serían las de los objetos hijos.
Arrays
Es una de las estructuras de datos mas básica y que probablemente ya hayas utilizado, es muy común que cuando no sepamos sobre este tema de Data Structures todo absolutamente todo lo metamos en un array y ya esta. Esto no suele ser buena practica ya que los Arrays no son la mejor de las soluciones en muchos casos.
-
Son una colleción de información, donde cada elemento (los valores que guardemos separados por coma) dentro del array tiene una posición, (Siempre iniciamos a contar en la posición 0).
-
En JS tenemos métodos que nos ayudan a manipularlos y recorrerlos.
También existen los Arrays dinámicos y estáticos. Por default en JS todos los Arrays son dinámicos. -
A diferencia de otros lenguajes que definimos el tamaño del array desde el momento en el que lo declaramos, esto es para que se reserve el espacio en memoria de dicho array y no sea mutable. Reservando únicamente los slots correspondientes al tamaño del array.
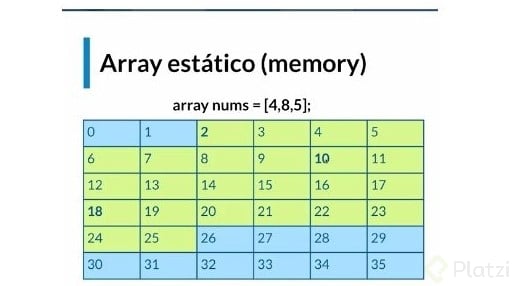
- Un array dinámico reserva el doble de slots correspondientes al tamaño del array en memoria por si llegan a crecer. Recordemos que al ser un array, los datos en memoria se tienen que guardar de manera continua, es decir, un dato seguido de otro, byte a byte.
- Si nos excedemos de los slots reservados inicialmente, el pc de manera automática copiara el array a un espacio en memoria donde tenga el doble slots disponibles y el espacio que reservo en un inicio lo va a liberar.

Strings
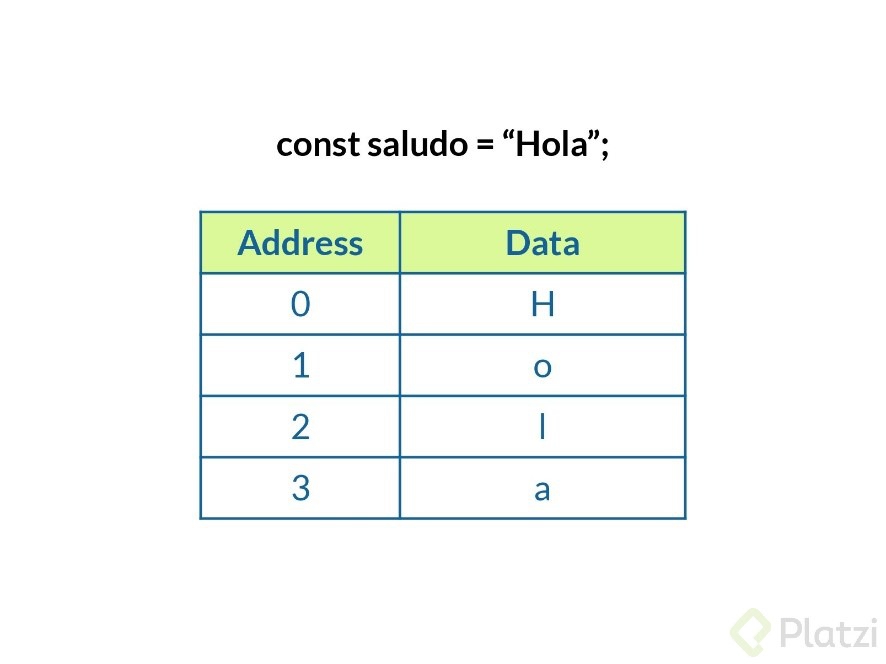
Los strings no son una estructura de datos perse, pero se pueden comportar como un array, con la diferencia es que un string no es mutable, una vez declarado no se puede modificar dicho valor, se debe crear otra variable, o re asignar el valor.
- Cuando generamos strings con JavaScript casi nunca tenemos modificarlos.
- Los strings se guardan como un arreglo (Array), esto nos permite acceder a los caracteres por su indice (Recuerda que siempre empezamos a contar desde el 0).
En resumen: Los strings son inmutables es decir que una vez los definidos no podemos cambiar “letra por letra” si no que tendremos que tomar todos los items y comenzar a realizar la operación deseada también significa mayor esfuerzo de computo.
Hash Tables
En JS esta es una estructura de datos que no viene creada como tal. Esta estructura de datos tiene distintos nombres según el lenguaje, en js son los objetos, aunque no es lo mismo que un hast table 100%
- Esta estructura de datos se caracteriza por tener la nomenclatura key: value / llave: valor
- En JS tenemos que hacer un paso extra y es que debemos crear una hash function, esto es una funcion que lo que hace es que a la key que le pasemos la convertirá en una referencia en memoria donde se guardaran los valores que asociadas a la llave.
- Para acceder a los valores debemos usar la misma llave, que será parseada al hash, (que es la referencia en memoria donde se encuentras los valores).
Esta estructura de datos es perfecta para resolver problemas que tengan que ver con búsquedas.
Las hash tienen distintos métodos, entre ellos están
- insert: que inserta un elemento en la tabla.
- search: buscar un elemento por key
- delete: borra un elemento
El problema de las hash
La colisión: en ocasiones puede ocurrir que cuando pasemos por la hash function un key distinto a todos los key anteriores, nos puede retornar un hash repetido. Eso hace que tengamos dos elementos guardados con el mismo hash, y como te estas imaginando eso es un problema bastante feo y adivina, no hay manera de evitar esto.
Pero la colisión se puede tratar, y la manera de hacerlo es curiosamente con otra estructura de datos, las linked list (listas enlazada)
En resumen: Las hash tables se parecen a los objetos porque podemos guardar valores por llave, valor. Pero su principal diferencia es que genera un hash para cada llave valor. El único problema es que se puede generar un mismo hash, colisionando así con uno anterior.
Linked List (Listas enlazadas)
Son un conjuntó de nodos, donde en cada nodo esta el valor que guardamos y también una referencia en memoria de donde esta el nodo siguiente.
Te dejo este articulo para que profundizes mas sobre las linked list en JS Mas sobre las linked list en JS
- Hay dos tipos de linked list, las que solo apuntan a su nodo siguiente, (singly linked list) y las que tienen dos referencias en memoria (Doubly Linked List), los cuales corresponden al nodo anterior y al nodo siguiente
Pero pensemos en las Singly Linked List como un edificio con escaleras donde cada piso sería un Nodo. Si quisiera ir del piso 1 al piso 5, estoy obligado a pasar por los pisos 2, 3 y 4. Además siempre debo entrar por el primer piso.
-
Para recorrer una linked list tenemos que pasar por todos y cada uno de los nodos, y siempre desde la cabeza, entonces ya podemos ver que es un poco ineficiente para algunos casos ya que no podemos acceder al valor de un nodo de manera rápida solo como su índice o su key como si seria el caso en los arrays y las tablas de hash.
-
Sino que por el contrario debemos de recorrer cada uno de los nodos si o si hasta llegar al que nos interesa.
-
Una ventaja es que al tener direcciones de en donde está en siguiente nodo, no hace falta que estén en memoria continua, como los arrays, sino que estos pueden estar en cualquier parte de la memoria y simplemente se referencia la ubicación en memoria de los nodos.
-
El último nodo siempre tiene un puntero que no tiene una referencia en memoria, es null, esto es para que podamos agregar mas elementos a la linked list
Stacks
O pila en español. Piensa en la pila como un conjunto de platos, apilados uno encima de otro, esta estructura de datos tiene un comportamiento tipo LIFO (last in, fisrt out)
- Es decir lo ultimo que agregamos es lo primero que debe (y puede salir). Continuando con nuestro ejemplo de los platos. Si tenemos 10 platos apilados y queremos el plato numero 4 tenemos que quitar 6 platos primero para poder acceder al plato numero 4.
- Siempre que agregamos elementos al stack estos se van a la cima de la pila, y asi mismo cuando retiremos elementos siempre sacaremos de esta el elemento en la cima de la pila, es decir, el ultimo elemento que agregamos
Queue
O fila en español. Son bastante similar a las stacks, pero tiene un comportamiento distinto, El de esta es FIFO (First in, first out), como un fila de personas en un banco por ejemplo. La persona que llega primero tiene derecho a ser atendida antes que el ultimo.
Tenemos métodos que nos ayudan en el manejo de las Queue:
- Enqueue: agrega elementos al final de la fila
- Dequeue: remueve el primer elemento de la fila
- Peek: toma el primer elemento de la fila
Trees
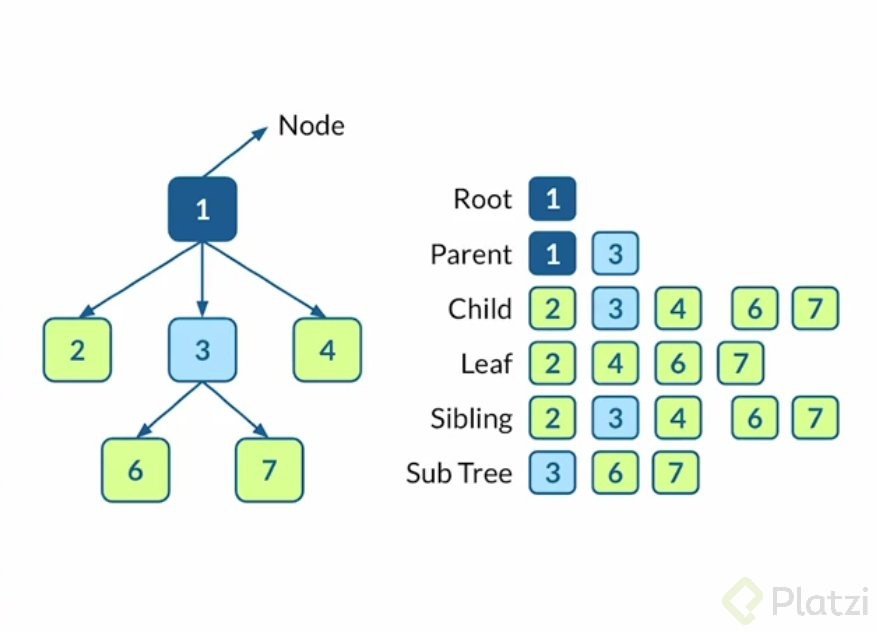
Consta de un único elemento raíz, que es de donde parten todos los hijos, y los hijos de estos, el termino correcto es que se genera una ramificación de datos.
-
Se compone de nodos y a partir del nodo raíz se empieza a ramificar todos los demás nodos.
-
Los nodos padres son aquellos de los cuales se desprendes otras ramas, las cuales serán sus hijos.
-
También tenemos las hojas del árbol (leafs) que son los nodos finales. El ultimo nodo de cada ramificación.
-
Los nodos hermanos son los nodos que provengan del mismo padre
-
Por ultimo tenemos los sub arboles, estos se forman en la ramificaciones que se vayan haciendo.
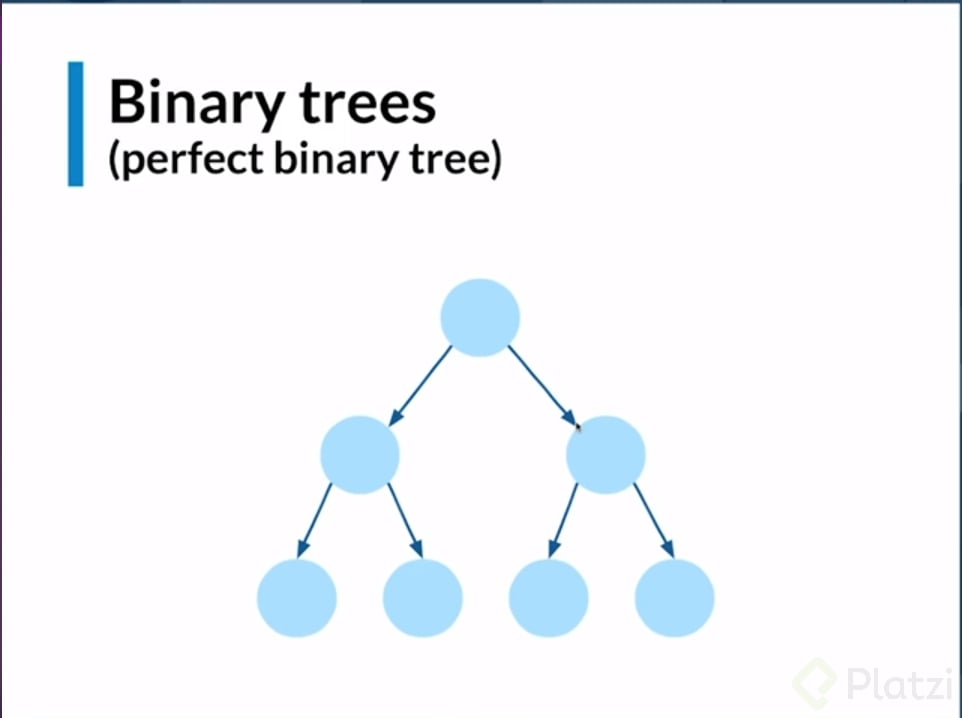
Binary Tree (Perfect Binary Tree)
Este es otro tipo de árbol y lo que lo hace especial es que sus nodos se van multiplicando, también se conoce como árbol balanceado, ya que tiene la misma cantidad de nodos a ambos lados del árbol.
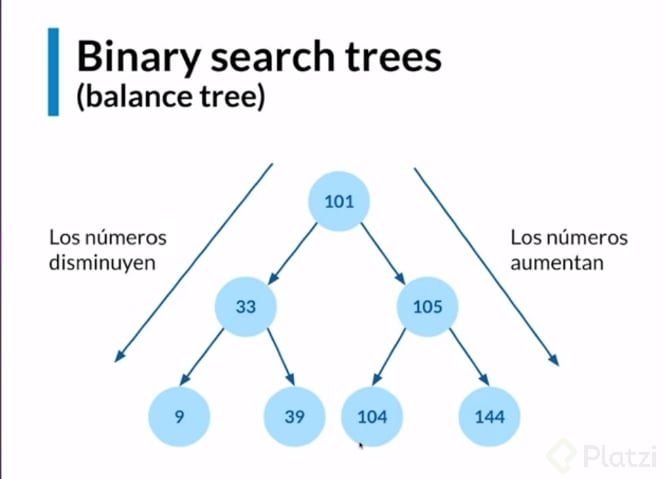
Binary Search Tree
Tiene la misma estructura de un binary tree perfect o árbol balanceado pero se diferencia en algo y es que un nodo solo puede tener dos ramificaciones y estas a su vez siguen un patrón:
- A la izquierda irán los elementos que sean menores a su padre directo.
- A la derecha irán los elementos que sean mayores a su padre directo.
¿Esto en que nos ayuda? Bueno en mucho, ya que nos ayuda a buscar valores de manera mas rápida. Aplicando el algoritmo “divide and conquer” Este se aplica a la búsqueda binaria, justo lo como se llama este árbol. ¿Coincidencia? Para nada!
Los métodos que vemos en el curso son:
- Search: para buscar un nodo
- Insert: inserta un nodo
- Delete: borra un nodo
Graphs
Son nodos interconectados entre si.
- Existen los dirigidos que son los que ya tienen un ruta especifica donde se sabe que nodo se conecta con que nodo (como las singly linked list), y los no dirigidos son nodos que tienen una conexión en doble sentido (como los doubly linked list).
- Otro tipo de grafo son los ponderados y los no ponderados, los primeros tienen un peso y nos dicen si cual es el camino mas eficiente para llegar a un destino. Los segundos no tienen esto pesos y no nos pueden ayudar a saber cual es el mejor camino, en comparación a los que si son ponderados.
- El grafo cuenta de dos partes, el vértice (nodo), y el borde (lo que lo conecta a otro grafo).
Hay distintas maneras de representar los grafos pero en el curso se ve de la siguiente manera:
- Adjacent list: es una lista de arrays, nos dice con quienes conecta nuestro nodo, a que nodos conoce.
Curso de Estructuras de Datos con JavaScript
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


