Para el resultado final, haremos lo siguiente:
Hay una web que reporta caídas eventuales en horarios aleatorios, que hace que sea difícil realizar un seguimiento de las horas exactas para revisar a profundidad las causas que generan este comportamiento, por lo que es necesario tener un log donde se almacene la respuesta del estatus periódicamente y partir de allí identificar posibles soluciones.
No tenemos acceso al servidor web, pero si podemos consultar la página desde un navegador para poder ver si carga correctamente o no. (De tener acceso al servidor web, podríamos instalar una herramienta de monitoreo, pero la incidencia de esta tarea disminuirá un poco el rendimiento del servidor por lo que consideramos otra opción).
En la web Everything curl de cURL se explican los comandos útiles para hacer algunas monerías con cURL, así que habiendo leído algunas de ellas y otros recursos llegamos a una opción para el uso de cURL.
La otra herramienta a emplear será usando un archivo bash (.sh) para poner todas las instrucciones dentro de un solo script y ejecutarlo todo junto.
a) Entendiendo cURL
De manera predeterminada curl permite descargar una página web, mediante la siguiente instrucción
curl -o output.html http://example.com/
Esta opción, genera un archivo llamado output.html con el contenido de la url ingresada.
Esta parte -o nos servirá para definir el nombre del archivo y evitar que sea el servidor quien defina el nombre de nuestro archivo, como ocurriría si utilizáramos -O.
b) cURL, parámetros
Para propósitos de generar sólo un log, nos interesa sólo el «status code» de la página, es decir el Código de estado de la respuesta HTTP, que nos dirá si nuestra página se está cargando o no. No nos interesa el contenido de toda la página.
Para obtener el status code tomamos el siguiente ejemplo.
curl -s -o statuscode.html -w «%{http_code}» http://example.com
Esto generará un archivo llamado statuscode.html con el contenido de la página web, pero a la vez imprimirá en pantalla el status code de la página web.
El status code devuelto es el 200.
El código de respuesta de estado satisfactorio HTTP 200 OK indica que la solicitud ha tenido éxito.
c) cURL, afinando detalles
El status es bueno, aunque ahora para mejorar nuestro log, nos interesará también obtener la cabecera y saber detalles, como la hora del servidor, el tiempo de expiración de la sesión, etc. por lo que a la consulta agregaremos el modificador -I y el resultado lo guardamos en un archivo llamado statuslog.html
curl -I https://example.com -o statuslog.html -w '%{http_code}' -s
Esto nos devuelve en un archivo statuslog.html la cabecera de la página, misma que contiene el código de respuesta http y a la vez nos imprime en pantalla el código devuelto.
-I, modificador por el cual obtenemos la cabecera de la URL consultada-o, escribe la salida en un archivo-w, write-out, hace que curl muestre información en la salida estándar después de una transferencia completa}-s, modo silencioso o silencioso. No muestra el medidor de progreso ni los mensajes de error
Para mejorar la instrucción anterior, podremos usar el caracter >> y escribir la salida en un archivo, y generar la salida a un archivo vacío, para evitar escribir un archivo statuslog.html.
Hasta este punto, ya tenemos lo básico para generar un estatus code por cada url a consultar, ahora pongamos todo en un script para ejecutar facilmente.
Nos aseguramos de estar en el directorio correcto
Creamos un archivo con extensión .sh y verificamos su existencia
Abrimos el archivo y editamos
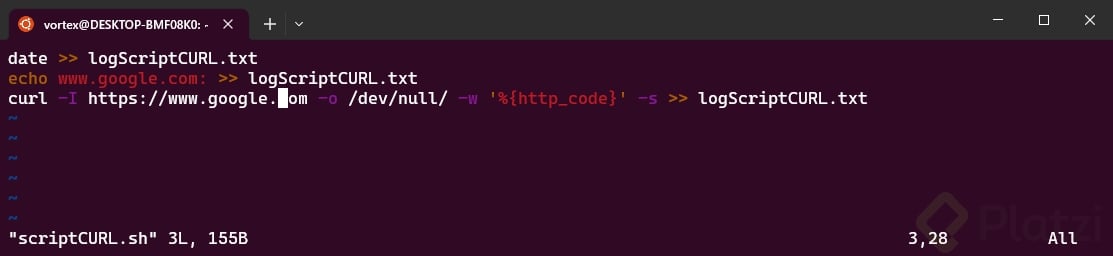
Guardamos y salimos de la edición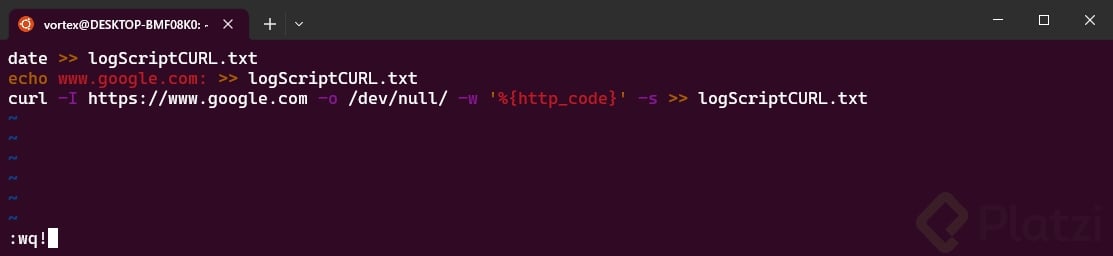
Ejecutamos el script recien creado
Verificamos que ahora se creó un nuevo archivo llamado logScriptCURL.txt
Abrimos el archivo con el comando less y visualizamos el contenido
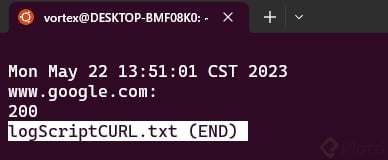
Podemos observar que el estatus code fue 200, lo que significa que la url solicitada está respondiendo de manera exitosa a la hora que se realizó la solicitud a través de cURL.





