
¿QUÉ ES UNA BASE DE DATOS DISTRIBUIDA?
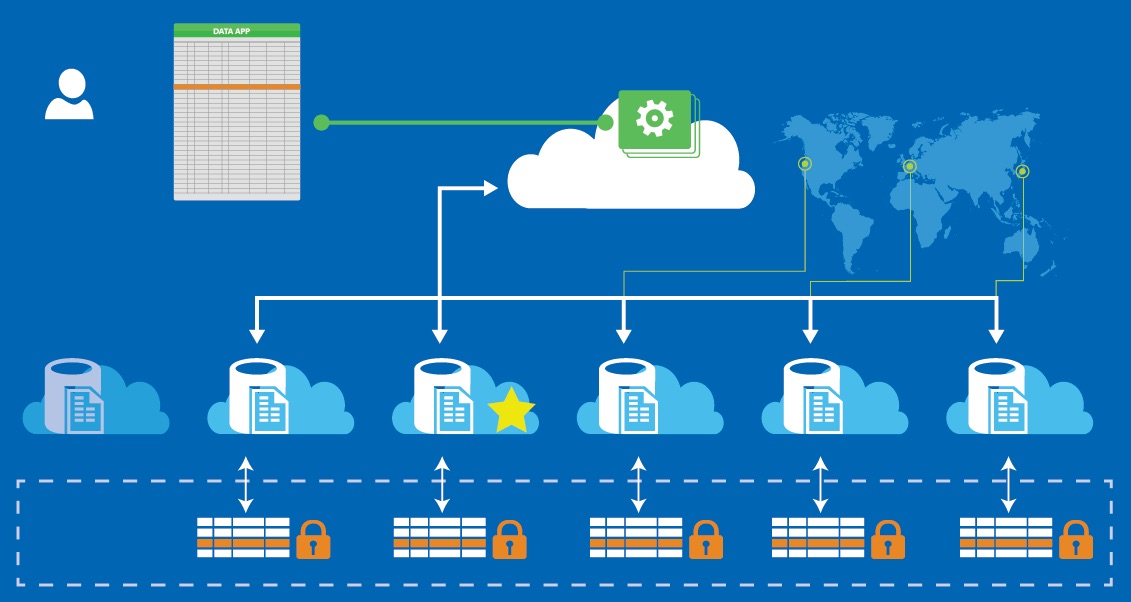
Una Base de Datos Distribuida es una colección de datos que pertenecen lógicamente a un solo sistema, pero se encuentra físicamente distribuido en varios computadores o servidores de datos en una red de computadoras. Un sistema de bases de datos distribuidas se compone de un conjunto de sitios lógicos, conectados entre sí, mediante algún tipo de red de comunicaciones, en el cual:
-
Cada sitio lógico puede tener un sistema de base de datos.
-
Los sitios han sido diseñados para trabajar en conjunto, con el fin de que un usuario de cualquier posición geográfica pueda obtener acceso a los datos desde cualquier punto de la red tal como si todos los datos estuvieran almacenados en la posición propia del usuario. Entonces, la llamada “Base de Datos Distribuida” es en realidad una especie de “objeto virtual”, cuyos componentes se almacenan físicamente en varias “bases de datos reales” ubicadas en diferentes sitios. En esencia es la unión lógica de esas diferentes bases de datos.
En otras palabras, cada sitio tiene sus propias “bases de datos reales" locales, sus propios usuarios locales, sus propios SGBD y programas para la administración de transacciones y su propio administrador de comunicación de datos. Así pues, el sistema de bases de datos distribuidas puede considerarse como una especie de sociedad entre los diferentes SGBD individuales locales. Un nuevo componente de software en cada sitio realiza las funciones de sociedad necesarias; y es la combinación de este nuevo componente y el SGBD ya existente constituyen el llamado Sistema de Administración o Gestión de Bases de Datos Distribuidas - SGBDD. (En ingles DDBMS, Distributed DataBase Management System).
Desde el punto de vista del usuario final, un sistema distribuido deberá ser idéntico a un sistema no distribuido. Los usuarios de un sistema distribuido se comportan en su manipulación de información exactamente como si el sistema no estuviera distribuido. Todos los problemas de los sistemas distribuidos son de tipo interno o a nivel de realización, no pueden existir problemas de tipo externo o a nivel del usuario final.
Los datos que se encuentran distribuidos en varios sitios y que están interconectados por una red de comunicaciones tienen capacidad de procesamiento autónomo de transacciones y hacer procesos locales. Cada sitio realiza la ejecución de al menos una transacción global, la cual requiere accesos a datos en diversos sitios.
Los principios fundamentales de un sistema de datos distribuido son:
(Estos doce postulados no son todas independientes entre sí, ni tienen todos la misma importancia que cada usuario le otorgue. Sin embargo, sí son útiles como fundamento para entender la tecnología distribuida y como marco de referencia para caracterizar la funcionalidad de sistemas distribuidos específicos.)
1. Autonomía local: Los sitios o posiciones de un sistema distribuido deben ser autónomos. La autonomía local significa que todas las operaciones en un sitio determinado se controlan en ese sitio; ningún sitio A deberá depender de algún otro sitio B para su buen funcionamiento (pues de otra manera el sitio A podría ser incapaz de trabajar, aunque no tenga en sí problema alguno, si cae el sitio B). La autonomía local significa que existe un propietario y un administrador local de los datos, con responsabilidad local: todos los datos pertenecen a una base de datos local, aunque los datos sean accesibles desde algún sitio distante. Todo el manejo de la seguridad y la integridad de los datos se efectúan con control de la instalación y administración local.
2. No dependencia de un sitio central : La no dependencia de un sitio central, sería lo ideal pero si esto no se logra la autonomía local completa se vería comprometida. La dependencia de un sitio central no es práctica al menos por las siguientes razones: en primer lugar, estos sitios podrían generar un cuello de botella, y en segundo lugar, el sistema sería vulnerable; si el sitio central sufriera un desperfecto, todo el sistema dejaría de funcionar.
3. Operación continúa: En un sistema distribuido, lo mismo que en uno no distribuido, nunca debería haber necesidad de apagar o dejar de funcionar. Es decir, el sistema nunca debería necesitar apagarse para que se pueda realizar alguna operación, como añadirse un nuevo sitio o instalar una versión mejorada del SGBD en un sitio ya existente.
4. Independencia con respecto a la localización : La independencia con respecto a la localización, permite que los usuarios finales no sepan donde están almacenados físicamente los datos, sino que trabajen como si todos los datos estuvieran almacenados en su propio sitio local. La independencia con respecto a la localización es deseable porque simplifica los sistemas de información de los usuarios y sus actividades en la terminal. Esto hace posible la migración de datos de un sitio a otro sin anular la validez de ninguno de esos sistemas o actividades. Esta función de migración permite modificar la distribución de los datos dentro de la red, en respuesta a cambios en los requerimientos de desempeño.
5. Independencia con respecto a la fragmentación: Un sistema tiene fragmentación de datos solo si es posible dividir una relación en partes o “fragmentos” para propósitos de almacenamiento físico. La fragmentación es deseable por razones de desempeño: los datos pueden almacenarse en la localidad donde se utilizan con mayor frecuencia, de manera que la mayor parte de las operaciones sean solo locales y se reduzca el tráfico en la red de cómputo. Existen en esencia dos clases de fragmentación, la fragmentación horizontal y la fragmentación vertical; estos tipos de fragmentación son correspondientes a las operaciones relacionales de restricción y proyección, respectivamente. Un fragmento puede ser cualquier sub relación que pueda derivarse de la relación original mediante operaciones de restricción y proyección; la reconstrucción de la relación originada a partir de los fragmentos se hace mediante operaciones de reunión y unión (reunión en el caso de fragmentación vertical, y la unión en casos de fragmentación horizontal).
6. Independencia de réplica: Un sistema maneja réplica de datos si una relación dada se puede representar en el nivel físico mediante varias copias réplicas, en muchos sitios distintos. La réplica es deseable al menos por dos razones: en primer lugar, puede producir un mejor desempeño (las aplicaciones pueden operar sobre copias locales en vez de tener que comunicarse con sitios remotos); en segundo lugar, también puede significar una mejor disponibilidad (un objeto estará disponible para su procesamiento en tanto esté disponible por lo menos una copia, al menos para propósitos de recuperación). La desventaja principal de las réplicas es cuando se pone al día un cierto objeto copiado, deben ponerse al día todas las réplicas de ese objeto. La réplica debe ser “transparente para el usuario final”, un sistema que maneja la réplica de los datos deberá ofrecer también una independencia de réplica (conocida también como transparencia de réplica); es decir, los usuarios deberán comportarse como si sólo existiera una copia de los datos.
7. Procesamiento distribuido de consultas: Este manejo de datos en las consultas permite las consultas eficientes desde diferentes usuarios con las características que determine el sistema; la consulta de datos es más importante en un sistema distribuido que en uno centralizado. Lo esencial es que, en una consulta donde están implicados varios sitios, habrá muchas maneras de trasladar los datos en la red de cómputo para satisfacer la solicitud, y es crucial encontrar una estrategia suficiente. Por ejemplo, una solicitud de unión de una relación Rx almacenada en el sitio X y una relación Ry almacenada en el sitio Y podría llevarse a cabo trasladando Rx a Y o trasladando Ry a X, o trasladando las dos a un tercer sitio Z.
8. Manejo distribuido de transacciones: Este manejo tiene dos aspectos principales, el control de recuperación y el control de concurrencia, cada uno de los cuales requiere un tratamiento más amplio en el ambiente distribuido. En un sistema distribuido, una sola transacción puede implicar la ejecución de programas o procesos en varios sitios (en particular puede implicar actualizaciones en varios sitios). Por esto, cada transacción está compuesta de varios agentes, donde un agente es el proceso ejecutado en nombre de una transacción dada en determinado sitio. Y el sistema necesita saber cuándo dos agentes son parte de la misma transacción. Es importante aclarar que no puede haber un bloqueo mutuo entre dos agentes que sean parte de la misma transacción.
9. Independencia con respecto al equipo: Las instalaciones de cómputo en el mundo real por lo regular incluyen varias máquinas de diferentes marcas comerciales como IBM, DELL, HP, SUN, entre otras; por esta razón existe una verdadera necesidad de poder integrar los datos en todos esos sistemas y presentar al usuario “una sola imagen del sistema”. Por tanto conviene ejecutar el mismo SGBD en diferentes equipos, y además lograr que esos diferentes equipos se integren en un sistema distribuido.
10. Independencia con respecto al sistema operativo: Es necesario y conveniente no sólo de poder ejecutar el mismo SGBD en diferentes equipos, sino también poder ejecutarlo en diferentes sistemas operativos y lograr que una versión LINUX y una WINDOWS participen todas en el mismo sistema distribuido.
11. Independencia con respecto a la red: Si el sistema puede manejar múltiples sitios, con equipos distintos y diferentes sistemas operativos, resulta obvia la conveniencia de manejar también varios tipos de redes de comunicación distintas.
12. Independencia con respecto al SGBD: En la independencia con respecto a su manejo, se requiere que los SGBD en los diferentes sitios manejen todos la misma interfaz; no necesitan ser por fuerza copias del mismo sistema.
Curso Práctico de SQL
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE







