

Qué hizo DeepSeek R1 para vencer a ChatGPT y cómo se entrenó para convertirse en el LLM open-source más potente del mercado.
Por: Adriana Urrego, Product Manager en el equipo de AI de Platzi.
Deepseek R1 es un modelo de lenguaje natural recientemente lanzado por la compañía Deepseek. En particular, esta semana ha alcanzado gran relevancia, pues es uno de los primeros modelos open-source en lograr un rendimiento comparable al de modelos cerrados como OpenAI o1 en varios benchmarks de razonamiento.
Un anuncio importante antes de continuar:

🚨 ¡INSCRIPCIONES ABIERTAS! 🔥 Ya viene Platzi Conf CDMX 2025 🇲🇽 Reserva ahora tu entrada presencial u online y vive la experiencia tech que transformará tu carrera.
Ahora sí, continuemos con Deepseek:
Pero, ¿cómo hicieron esto a una fracción del costo en comparación con GPT-o1, logrando un rendimiento similar o incluso superior en algunas tareas? La respuesta se encuentra en las innovaciones que implementaron en la forma en que se entrena un modelo.
Innovaciones clave de Deepseek
Deepseek R1 introdujo innovación en dos componentes fundamentales:
-
Rule-based Reinforcement Learning
-
Chain-of-Thought
Si estos términos te suenan ajenos, no te preocupes. A continuación, te explicamos qué significan y cómo jugaron un papel clave en la creación de estos modelos.
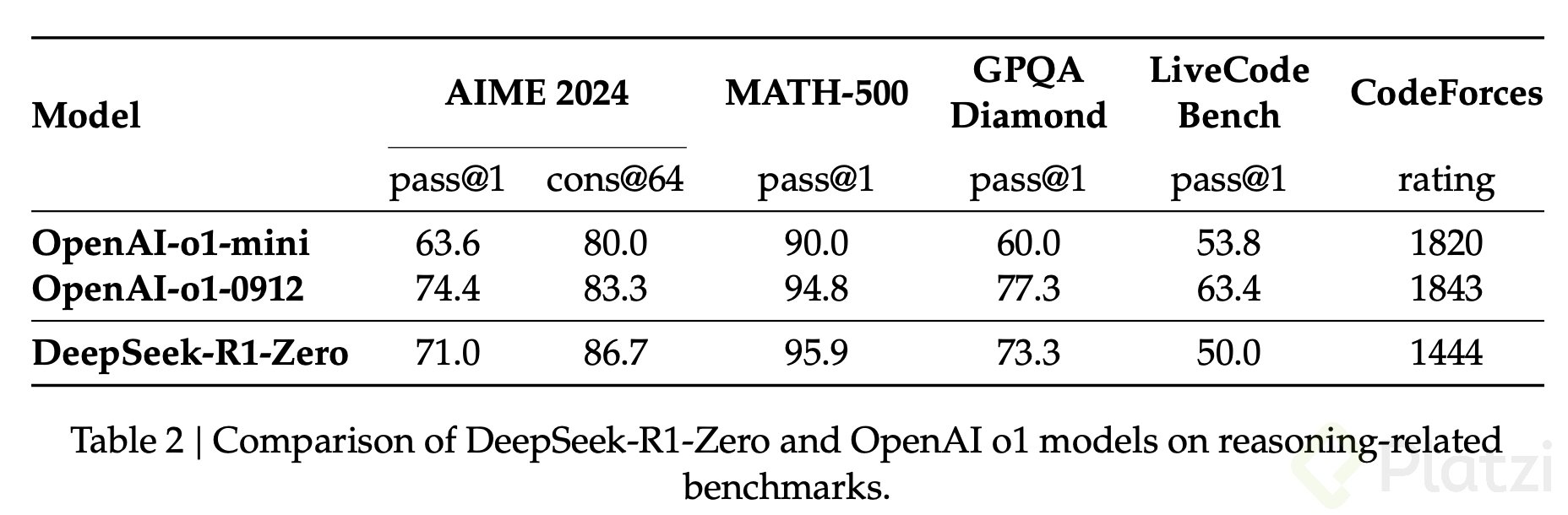
Para que R1 fuera posible, el equipo de Deepseek primero desarrolló el modelo R1-Zero, que logró un rendimiento comparable y, en algunos casos, superior al de OpenAI o1-mini.
¿Cómo se entrena un modelo de lenguaje natural o LLM?
Antes de ver cómo Deepseek creó R1 y R1-Zero, es importante entender los tres pasos tradicionales en el entrenamiento de un LLM:
- Pre-entrenamiento: en este primer paso se alimenta al modelo con grandes volúmenes de texto para que aprenda a predecir la siguiente palabra en una frase. Luego de este paso, el modelo podría ser capaz de predecir la palabra “París” si le ingresas la frase “La capital de Francia es…".
- Supervised Fine-Tuning (SFT): luego, se le presenta un dataset de instrucciones/respuestas para que pueda generar contenido según indicaciones, como “Resume este texto”.
- Reinforcement Learning: finalmente, se ajusta el modelo para alinearlo con preferencias humanas. Modelos como GPT utilizan Reinforcement Learning with Human Feedback (RLHF), donde miles de personas ayudan a mejorar la calidad de las respuestas.
¿En qué innovó Deepseek?
Deepseek R1-Zero eliminó la fase de SFT antes del Reinforcement Learning. En su lugar, aplicó directamente Rule-based Reinforcement Learning, permitiendo que el modelo desarrollara habilidades de razonamiento sin supervisión humana previa.
¿Cómo se entrenó el modelo Deepseek R1-Zero?
Para crear Deepseek R1-Zero, el equipo de Deepseek realizó ajustes clave en el proceso de entrenamiento:
-
Usaron un modelo base, DeepSeek-V3, con 671 mil millones de parámetros, de los cuales solo 37B están activos por token gracias a la arquitectura Mixture of Experts (MoE).
-
Implementaron Group Relative Policy Optimization (GRPO), una variante de Rule-based Reinforcement Learning, donde el modelo recibe recompensas basadas en reglas predefinidas. Por ejemplo, en problemas matemáticos, la exactitud de la respuesta determinaba la recompensa.
-
Diseñaron un formato de prompt con dos etiquetas:
- <think> donde el modelo debe incluir su proceso de análisis
- <answer> donde incluye la respuesta final.

Este proceso forzó al modelo a reflexionar antes de responder, lo que se conoce como Chain-of-Thought (CoT). A diferencia de otros modelos, Deepseek R1-Zero desarrolló esta habilidad sin datos supervisados.
Gracias a este enfoque, Deepseek R1-Zero mejoró su capacidad de razonamiento en problemas complejos. Sin embargo, presentó problemas de legibilidad y respuestas en varios idiomas. Para solucionarlo, Deepseek lanzó R1.
¿Cómo se entrenó el modelo Deepseek R1?
Teniendo en cuenta todo lo aprendido con el modelo R1-Zero, para el modelo R1 Deepseek tomó un camino distinto:
-
Incorporó SFT hasta lograr respuestas consistentes en tareas de razonamiento. Para esto usaron cold-start data, un conjunto de aproximadamente 800,000 ejemplos de entrenamiento distribuidos en:
-
600,000 ejemplos de problemas con soluciones deterministas como matemáticas o código, junto con Chain-of-Thought detallado.
-
200,000 ejemplos de tareas generales (generación de texto, preguntas factuales y autoevaluación).
-
-
Luego se aplicó Rule-based Reinforcement Learning para mejorar la legibilidad y alinear las respuestas con preferencias humanas y así garantizar que el modelo fuera útil y seguro.
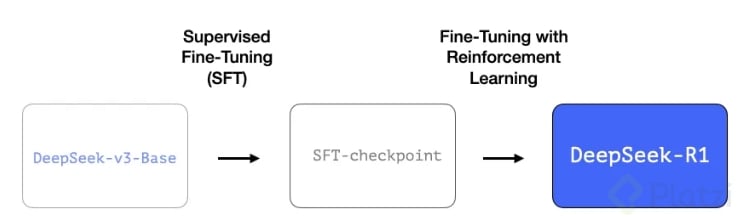
Con esto, lograron crear un modelo con un rendimiento igual o superior en tareas de razonamiento en comparación con otros modelos cerrados a una fracción del costo de entrenamiento tradicional.
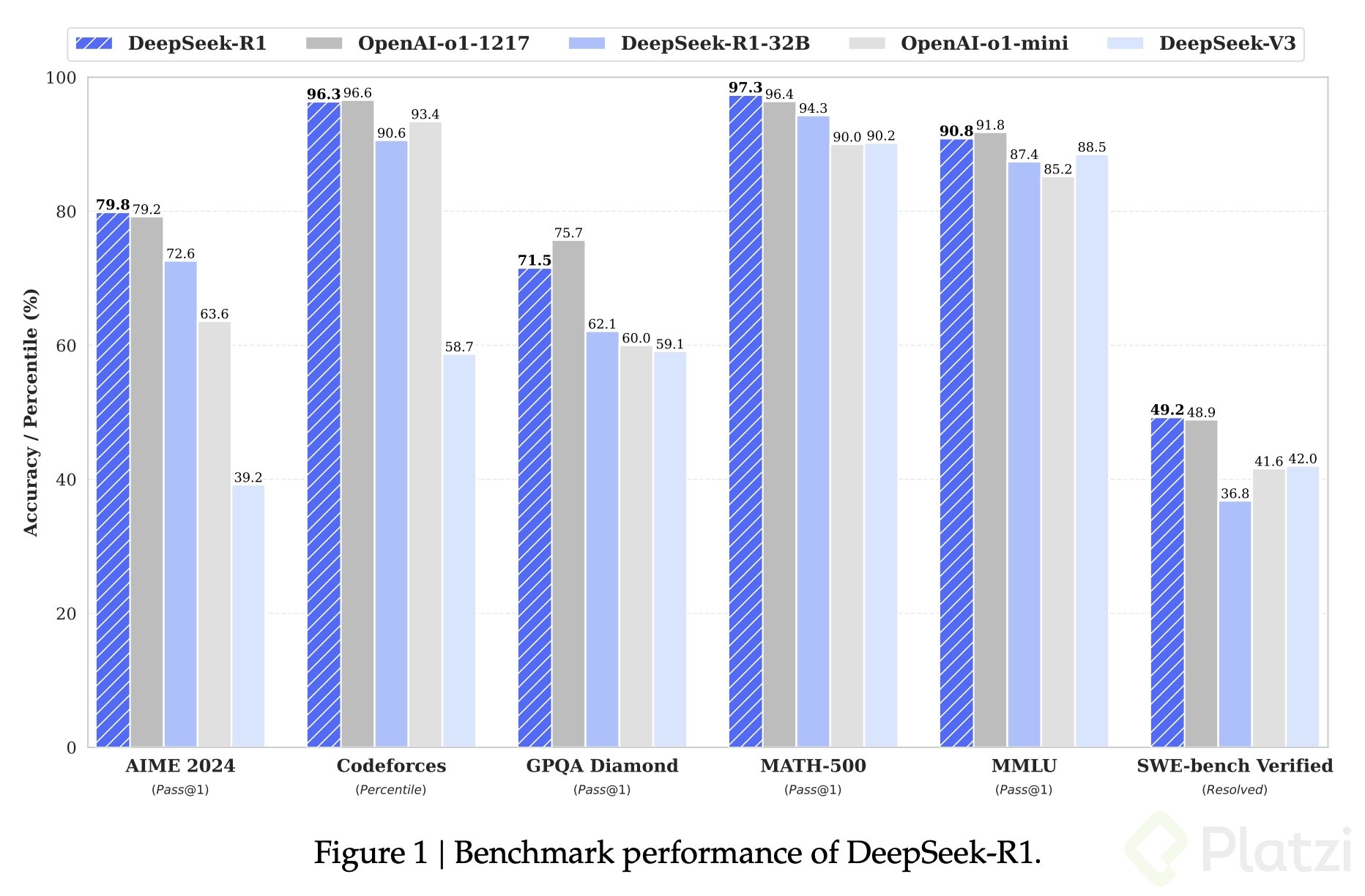
Gracias a esto, Deepseek R1 es un modelo open-source que cualquier persona puede ejecutar y personalizar según sus necesidades.
Deepseek R1 marca un hito en la inteligencia artificial open-source, permitiendo que empresas y desarrolladores utilicen modelos avanzados sin depender de soluciones cerradas.
El tiempo corre: la IA no espera a nadie
Si te interesa experimentar con este modelo, en este post te explicamos cómo instalar y ejecutar DeepSeek-R1 de manera local. Además, te recomendamos leer el paper oficial de Deepseek para profundizar en los detalles técnicos.
Sin duda, los trabajos y la cotidianidad se transformarán por la IA en los próximos años. Prepárate ahora: en nuestra Escuela de Data Science e Inteligencia Artificial encontrarás las herramientas para liderar esta revolución, no solo seguirla. Únete a los profesionales que están escribiendo el futuro, no leyéndolo.
¡Esperamos que pronto puedas experimentar y hasta crear tu propio modelo!
Educación online efectiva
Aprende con expertos de la industria
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE







