
El auge de las soluciones de Machine Learning y de IA es innegable. Tenemos todo habilitado para la inteligencia artificial, desde la optimización de los diagnósticos médicos, RR.HH y los procesos de elaboración de cereza.
Pero, gracias a este auge, también nos dimos cuenta de que desarrollar y producir dichos productos es realmente muy difícil. Y no fue mucho antes de que empezáramos a ver estos tipos de artículos en prácticamente todos lados:

Artificial Intelligence Confronts a ‘Reproducibility’ Cris by Wired

Hutson M., revista Science, febrero de 2018, volumen 359, p. 725.
¿Qué es la reproducibilidad y por qué nos interesa?
Un resultado es reproducible cuando los mismos pasos de análisis realizados en el mismo conjunto de resultados generan de manera uniforme la misma respuesta.
El Machine Learning reproducible pueden evitar errores y costos importantes en el futuro. Además, también facilita llevar un seguimiento de las conclusiones o predicciones generadas y explicarlas.
Pero más allá de eso, el uso de la reproducibilidad facilita los procesos de colaboración y revisión, garantiza la continuidad del trabajo y conserva el conocimiento institucional y las pruebas futuras del trabajo. Esto es muy importante, ya que la mayoría de las veces no se trabaja solo, sino con un grupo de científicos de datos, ingenieros de software y muchas otras partes interesadas.
La verdad es que la reproducibilidad en Machine Learning es un problema al que cada profesional se enfrenta a diario.
¿Alguna vez se ha preguntado algo de esto?
- ¿Qué versión del conjunto de datos se usó para entrenar este algoritmo?
- ¿Qué versión del algoritmo o modelo tenemos en I+D/ensayo/producción/se publicó en el documento?
- ¿Hicimos un seguimiento de todos los parámetros y las características que exploramos y de los modelos de base de referencia?

Foto de Paolo Nicolello en Unsplash
Créame… a todos nos ha pasado.
Por tanto, sin más demora, vamos a profundizar en cómo hacer que los flujos de trabajo sean más reproducibles.
0. Identificación de los actores clave
La base de los flujos de trabajo reproducibles radica en poder hacer un seguimiento de los datos, del entorno informático y del código y reproducirlos.
Así es que verá que la mayoría de estas recomendaciones se centra en estos tres recursos críticos:

No voy a profundizar mucho en esto, porque merece una publicación entera. Pero idealmente querrá hacer la reproducibilidad de todo su trabajo en tres niveles:
- Metodología: por ejemplo, cómo formula los experimentos y comprueba o desmiente su hipótesis.
- Modelo/algoritmo (aunque Machine Learning va más allá de los modelos que se implementan). Por ejemplo, explique la complejidad del algoritmo y el espacio que cubre y cómo se eligieron los hiperparámetros.
- Infraestructura: aquí quiere asegurarse de que hay una infraestructura sólida para que otros usuarios accedan a sus datos y ejecuten el código. Asegúrese también de describir el hardware que usó (como la GPU).

1. Sepa siempre lo que espera de los datos.
Todos sabemos que los datos de buena calidad son fundamentales para una buena calidad y Machine Learning confiable. Así es que siempre tenemos que saber qué esperamos de los datos en todo momento: qué tipos, distribuciones, intervalos y esquemas.
Una de mis herramientas favoritas para hacerlo es Great expectations, porque se integra con otras herramientas que uso como Spark, Airflow, Jupyter Notebooks y Pandas (entre otras). Es una herramienta excelente para la validación, prueba y documentación de los datos.
Por ejemplo, si tiene un origen de datos sin procesar en el que hace alguna manipulación antes de almacenarlos en una base de datos, puede agregar varios pasos de validación para los datos de entrada y salida.

Si va a recopilar datos desde API de terceros, puede usar el esquema JSON para realizar la validación con el meta esquema.
2. Desarrolle canalizaciones.
La mejor manera de realizar un seguimiento de todas las salidas, entradas, métricas, modelos y datos, incluso antes de usar herramientas especializadas, es poder realizar un seguimiento de cada una de las tareas que se llevan a cabo.
Muchas herramientas le permiten crear canalizaciones sólidas. Muchas de ellas se centran en el concepto de grafos acíclicos dirigidos. Algunas de mis favoritas son:
- Dagster: descubrí que es muy fácil de usar y que tiene una integración nativa con Jupyter (¿qué mejor?).
- Airflow: este proyecto de incubación de Apache ha ganado mucha popularidad. La interfaz de usuario permite que sea muy sencillo tener una visión general de los DAG y sus estados.
Estas agregan mucha complejidad:
Pero debe tener en cuenta esta regla general si decide implementar sus canalizaciones:
✨ Sugerencia principal: Divida las tareas en unidades atómicas de trabajo, en las que cada nodo del DAG o cada paso de la canalización realiza una sola tarea.
Esto ayuda a evitar el problema en el que, si se cambia algo, se cambia todo (Scully et al).
3. Hay aceptar que el ML adora la aleatoriedad.
La aleatoriedad está en todos lados:
- Inicializaciones aleatorias
- Aumentos aleatorios
- Introducciones de ruido aleatorias
- Orden aleatorio de los datos
El mejor consejo que encontrará en todos lados es que siempre debe establecer y guardar su inicialización.
Si trabaja con Python, a menudo debería verse haciendo una versión de este ritual:
import os
import tensorflow
import numpy
os.environ['PYTHONHASHSEED'] = str(seed)
random.seed(seed)
tensorflow.random.set_seed(seed)
numpy.random.seed(seed)
tensorflow.keras.layers.Dropout(x, seed=SEED)
tensorflow.image.random_flip_left_right(x, seed=seed)
tensorflow.random_normal_initializer(x, y, seed=seed)
Otro origen de aleatoriedad son los datos. Cuando dividimos los datos para el entrenamiento y la validación, a menudo usamos divisiones distintas.
La solución: corrija las divisiones de entrenamiento y validación antes del entrenamiento. Si usa métodos como test_split_train de scikit-learn, asegúrese de especificar también el argumento seed.
4. Hiperparámetros en todas partes
La búsqueda de los hiperparámetros correctos para sus modelos puede ser un proceso bastante complicado. Estos pueden ser especialmente problemáticos cuando se ejecutan varios experimentos con distintas arquitecturas de red.
✨ Sugerencia principal: Como regla general, no solo haga un seguimiento de los parámetros, sino también de las métricas de salida de cada modelo asociado y del proceso o la base de referencia de selección.
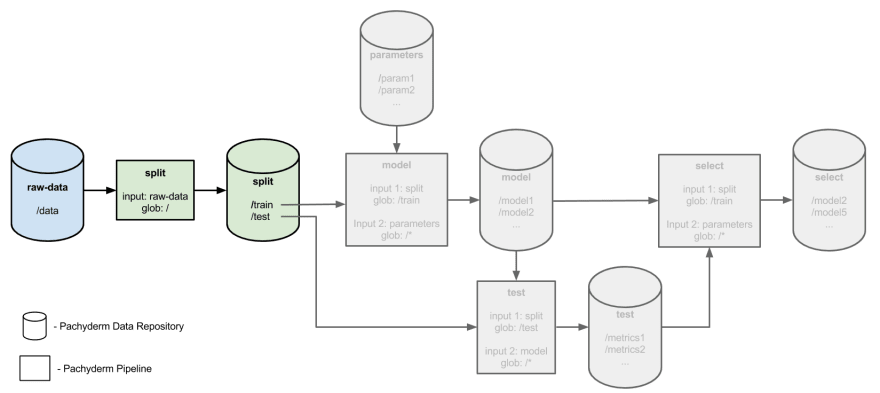
Puede encontrar un excelente ejemplo de cómo hacer el seguimiento de los hiperparámetros de una manera correcta en el ejemplo de ajuste de los hiperparámetros distribuidos de Pachyderm.
 .
.
El uso de canalizaciones para dividir, entrenar, probar y seleccionar los modelos y el hiperparámetro facilita mucho realizar un seguimiento de las salidas en todas las fases, así como informar con respecto a la lógica que explica por qué eligió hiperparámetros específicos.
5. y 6. Control de versiones y desacoplamiento de los datos.
¿Con qué frecuencia ha trabajado en fragmentos de código con líneas como esta?
import pandas as pd
df = pd.read_csv("../../../data.csv")
En este escenario, los datos y el código están estrechamente acoplados. Para garantizar la reproducibilidad, debe hacer un seguimiento del código y de las versiones de los datos, no solo para las salidas finales, sino también para los resultados intermedios.
Imagine que tiene un flujo de trabajo como este:
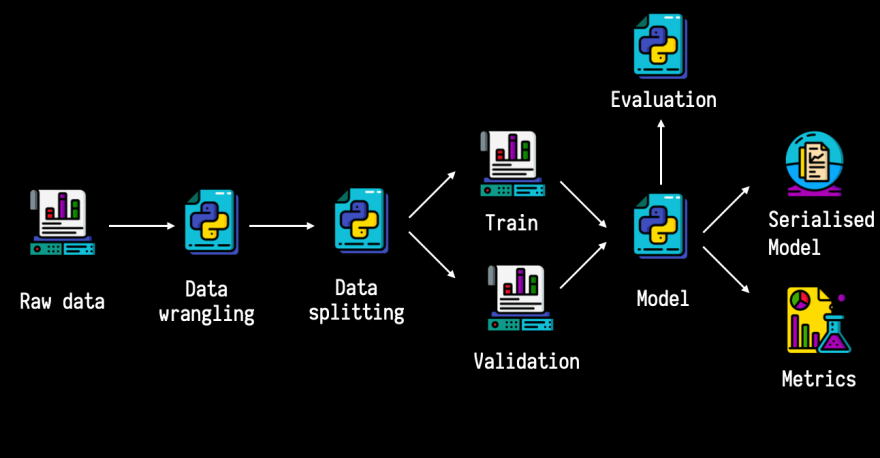
Aunque se trata de una canalización ligeramente simplificada, de todos modos, hay varias salidas a las que quiere hacer un seguimiento (datos, código y archivos serializados).
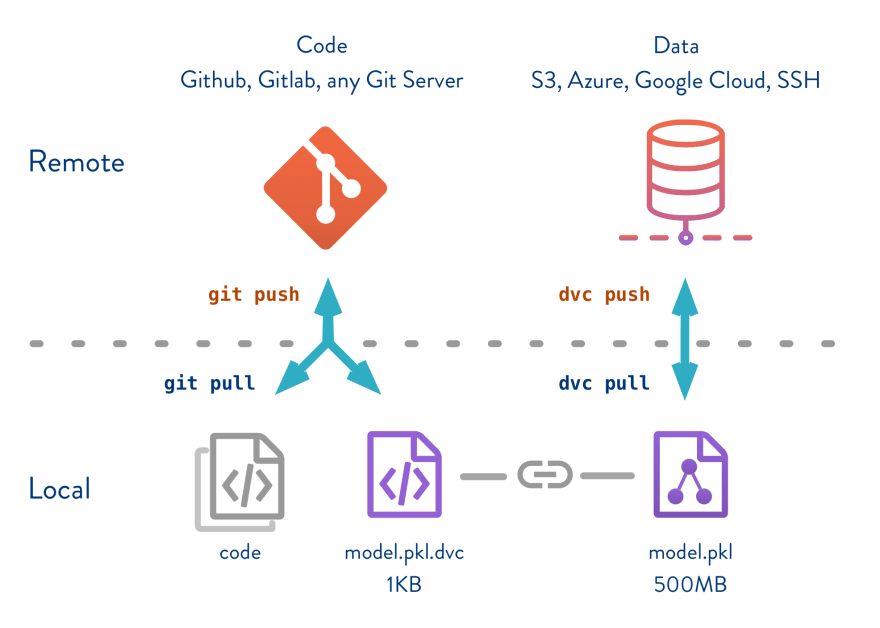
Una herramienta ideal para esto es dvc, que permite llevar un seguimiento de todos los recursos con Git sin tener que * almacenar los datos en Git*.
Esto le permite desacoplar los datos y el código, así como sus versiones respectivas, para garantizar la reproducibilidad:
7. Pruebas
En Machine Learning, las pruebas pueden ser muy complejas. Como ya dije, no voy a profundizar demasiado en esto porque las estrategias de pruebas merecen una publicación exclusiva. Así es que aquí tenemos una lista de comprobación de los elementos y las estrategias de pruebas que debe tener en cuenta:
- Llamadas API y pruebas de contrato en los esquemas de datos.
- Pruebas de integración para las canalizaciones.
- Pruebas de regresión.
- Pruebas unitarias: pruebe sus métodos y transformaciones.
- Prueba de que los pesos del modelo y las salidas son numéricamente estables.
- Reproducibilidad en los distintos entornos: desarrollo, ensayo y producción. Las predicciones entre ellos deben ser las mismas.
✨ Sugerencia principal: Un paquete que uso una y otra vez es Hypothesis para las pruebas basadas en propiedades. No solo me ha permitido simplificar las estrategias de pruebas, sino también ha aumentado mi confianza en las pruebas.
Estas son algunas extensiones de Hypothesis que vale la pena revisar: https://hypothesis.readthedocs.io/en/latest/strategies.html.
8. Entornos reproducibles
Para que un trabajo se pueda reproducir, se debe capturar el entorno informático donde se realizó para que otros puedan replicarlo.
Muchas herramientas le permiten crear entornos reproducibles o, al menos, acercarse.
En función de los proyectos en los que estoy trabajando, suelo combinar algunas de estas herramientas:
Y me sigue encantando Make porque es fantástico.
✨ Sugerencias principales:
- No hay un método que sea igual para todos. Elija el método más adecuado para su proyecto a fin de capturar el entorno informático.
- Capture el entorno informático. No solo recomiendo anclar las dependencias principales, sino también las subdependencias y usar una herramienta con resoluciones de dependencia (pip-tools, pipenv y Poetry son herramientas ideales para esto).
- Comparta el entorno informático capturado junto con su código y datos, si es posible.
9. Automatice
Se pueden producir muchos errores cuando se depende demasiado del humano en el bucle para los flujos de trabajo.
Por lo tanto, recurrir a la automatización cada vez que sea posible no solo le permitirá ahorrar tiempo, sino que también optimizará los flujos de trabajo y aumentará su confianza.
Estas son algunas de las excelentes herramientas que uso para la automatización:
- Tox, para pruebas automatizadas.
- Nox, automatización flexible de pruebas.
- Invoke, ejecución de tareas de uso general (muy similar a Make, pero específica para Python).
- Repo2docker, crea contenedores de Docker a partir de repositorios de GitHub.
- Binder, crea entornos interactivos reproducibles a partir de repositorios de GitHub.
- GitHub Actions: integración y entrega continuas, así como automatización de los flujos de trabajo.
✨ Sugerencia principal: Comience a automatizar las partes más críticas: implementación, creación de contenedores, pruebas y avance desde ahí.
10. Coherencia y estándares
Lee también: Machine Learning vs. Deep Learning
Con la infinidad de herramientas y flujos de trabajo que existen, no hay una solución única para el problema de la reproducibilidad.
Pero lo que he aprendido es que la coherencia es crítica. Estas son mis últimas ✨ Sugerencias principales:
- Debe tener una estructura de proyecto coherente. Puede usar herramientas como Cookiecutter Data Science.
- Cumpla con los estándares de codificación:
- Documentos y documentación como código.
- Hay muchos usuarios a los que no les gusta escribir documentación, pero algo que empecé a hacer hace un tiempo es tratar los documentos como si fueran código (bueno…casi). Creo todos mis documentos a través de mis canalizaciones de integración continua y también ejecuto pruebas en ellos.
- Elección de las herramientas:
- Aquí ya mencioné muchas herramientas, pero cada una de ellas implica una curva de aprendizaje y trucos que tiene que aprender. Elija lo que más le convenga y apréndalo bien, en lugar de intentar aprender a usar todas las herramientas.
¡Eso es todo! Estas son algunas sugerencias prácticas para empezar a usar Machine Learning reproducible.
¿Cree que me faltó alguna sugerencia? Cuénteme en los comentarios.
Curso de Fundamentos Prácticos de Machine Learning
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


