

Si bien en los últimos años se ha popularizado el término observabilidad, dado el progreso de la ingeniería del software y la facilidad para resolver problemas que nos brinda, este no es un término nuevo. Tiene sus orígenes allá por 1960 y en este artículo verás cómo pasó de ser un término que surge en la teoría del control, en una época en el que la computación solo era accesible en universidades y grandes compañías, a la aplicación en sistemas distribuidos de hoy en día.
Como vamos a hacer un repaso histórico, te recomiendo tomar el Curso de Introducción a la Web: Historia y Funcionamiento de Internet. De esta forma entenderás mejor el contexto y lo relacionarás con los hechos históricos que marcaron al funcionamiento de internet y la web.

1960’s: Kálmán y la teoría del control
La observabilidad surge de la necesidad de conocer el estado interno de un sistema mecánico a partir de la información que este arroja. Y es aquí que Rudolf E. Kálmán acuña el término en su paper On the general theory of control systems. Para aquel entonces, Kálmán no tenía la mínima intención de aplicar la observabilidad a sistemas de software. La computación estaba apenas iniciando. Su idea era más bien aplicarlo a un sistema industrial para optimizarlo.
En aquella época, la computación moderna estaba apenas iniciando, no se hizo mucho con respecto a observabilidad e ingeniería de software. Es más, su relación continuará mucho después, como leerás a continuación.
1990’s: Sun Microsystems y los primeros enfoques de software
En la década de los 90’s un par de equipos de ingeniería de software hicieron los primeros esfuerzos por aplicar el concepto de observabilidad en sus sistemas. Entre ellos estaba Sun Microsystems, que fue la compañía que creó Java.
Su enfoque se trataba de ver la observabilidad como un paso hacia el manejo del rendimiento de una aplicación, antes que de ver este último como un paso dentro de la observabilidad.
Si conocer sobre la compañía que creó Java te hizo dar ganas de aprender este lenguaje, te recomiendo tomar el Curso de Introducción a Java SE.

2010’s: Twitter y el auge de la observabilidad
Y a pesar de que los fundamentos de la observabilidad se plantearon en los 60’s y los primeros acercamientos para aplicarlo en la ingeniería del software se dio en los 90’s, no fue hasta la década del 2010 que empezó a popularizarse entre los equipos de IT. Su principal artífice: Twitter.
En septiembre de 2013, Cory Watson publica el artículo Observability at Twitter. En él se manifiesta la transición de Twitter de una arquitectura monolítica a una distribuida. Por lo tanto, el mantener el rendimiento a lo largo de todos sus servicios distribuidos se vuelve una tarea compleja. Allí proponen instrumentar ciertas partes de su código.
En la imagen de abajo puedes ver cómo diseñaron su arquitectura para determinar el rendimiento de sus servicios y saber cuándo algo está fallando.
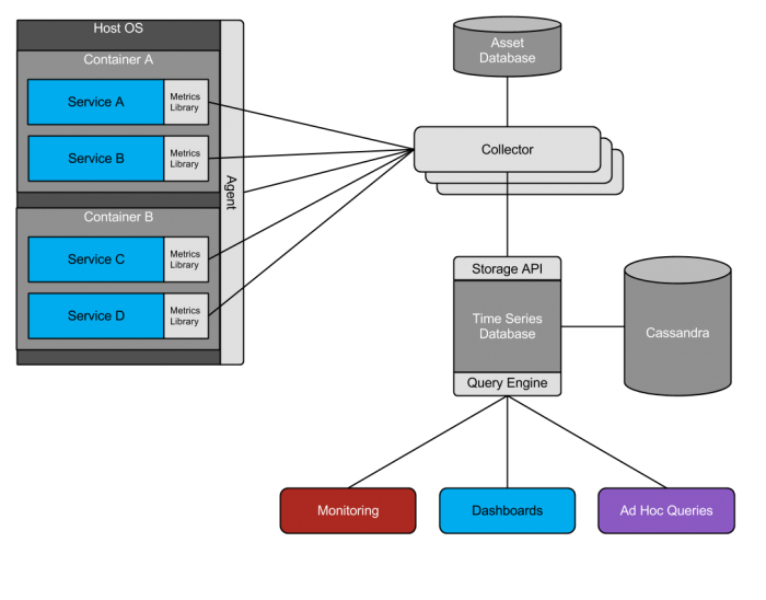
Fuente de imagen: Watson, C. Observability at Twitter, 2013.
Luego, en 2016, en otro artículo publicado en Twitter Observability at Twitter: technical overview, part I por Anthony Asta, se indica cómo el equipo de Observability Engineering de Twitter provee de librerías y servicios a los demás equipos internos de ingeniería para monitorear el rendimiento de sus servicios. Entonces proponen 4 pilares de la observabilidad:
- Monitoring
- Alerting/visualisation
- Distributed systems tracing infrastructure
- Log aggregation/analytics
2020’s: tu turno de aprender observabilidad
Tú también puedes formar parte de la historia y del desarrollo de la observabilidad dentro de la ingeniería del software. Para ello puedes tomar el Curso de New Relic: Observabilidad, Monitoreo y Performance Web. Con este curso aprenderás a implementar observabilidad en tus apps, ir más allá del monitoreo y obtener información en tiempo real sobre el rendimiento, el status y todos los puntos claves del negocio de forma automatizada y en tiempo real con New Relic.
Además, si finalizas dicho curso, podrás acceder, de manera completamente GRATUITA, a una cuenta de New Relic for students (lo cual te dará acceso a herramientas que, de otra forma, tendrías que pagar).
Para acceder a dicho beneficio, debes registrarte aquí. Solo recuerda usar el correo que usas como estudiante de Platzi. 😉
Curso de Fundamentos de Observabilidad con New Relic
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE




