
¡Hola! en este pequeño tutorial te ayudaré a graficar usando una librería de Python llamada Matplotlib y Pandas para el análisis y manipulación de datos.
Este metodo es un poco más complejo pero no imposible. Si estás interesado en hacerlo usando Pandas aunque no conozcas esta librería, no te preocupes, a cada paso que demos te iré explicando que hará cada linea de codigo y así podrás tener un conocimiento más claro sobre esta librería junto a la librería para graficar de Matplotlib.
Importante
DESTACO QUE ESTA GUIA FUE CREADA EN UN SISTEMA OPERATIVO LINUX UBUNTU
Los unicos comandos que cambiarán son la creación del entorno virtual env y la activación del mismo. El resto del codigo es el mismo.
Recuerda tambien tener el archivo csv de la superstore dado para el ejemplo de graficación.
Creación del entorno virtual
Lo primero que necesitarás es un entorno (env) para poder trabajar. En mi caso trabajaré de forma local usando Jupyter Notebook.
Para crear nuestro entorno virtual usamos:
python3 -m venv env
donde env será el nombre de nuestro entorno. Por comodidad usaré env
Para activar el entorno virtual escribimos en la terminal
source env/bin/activate
Ahora necesitarás instalar las siguientes librerías
- pandas
- numpy
- matplotlib
- jupyter
Para instalar usas
pip install <nombre_libreria>
Puedes hacer el proceso más rapido creando un archivo llamado requirements.txt donde pondrás el nombre de una librería por linea.
Posteriormente usarás
pip install -r requirements.txt
De esta forma, todas las librerías que pongas en el requirements.txt se instalarán de forma automatica.
Ejecutando Jupyter Notebook
Jupyter es un “entorno” que nos permite escribir codigo y ejecutarlo de manera asincrona, esto quiere decir, que no tenemos que ejecutar todo el script para poder ver el resultado, solo deberemos ejecutar la linea de codigo que queremos y este nos devolverá un resultado.
Para activar el Jupyter Notebook usamos en la terminal:
jupyter notebook
Una vez ejecutado y pasado unos segundos, se abrirá una ventana en el navegador como la siguiente:
Estando ahí le daremos a New y luego a Python3.x.x ('env') en mi caso, por mi versión de Python aparece Python3.8.5 64-bit ('env).
Debe aparecerles su versión de python, la arquitectura de su procesador y el nombre de su entorno.
Pasemos al codigo
Lo primero que haremos es importar nuestras librerías.
import pandas as pd
import numpy as np
import random
import matplotlib.pyplot as plot
Cada vez que queramos ejecutar una linea de codigo usamos Ctrl + Enter. En caso de querer ejecutar y pasar a la siguiente linea de código usamos Shift + Enter
Ejecutamos ese bloque de codigo usando Shift + Enter y pasamos a empezar a ver nuestro Data Set
Usamos:
df = pd.DataFrame(pd.read_csv('nombre_del_archivo.csv')
- pd.read_csv nos permite leer un archivo en formato csv. Como su nombre nos indica
- pd.DataFrame convierte el archivo (DataSet) que tomemos en un Data Frame
Ahora si queremos ver el resultado de esto, llamamos a nuestra variable dfpara ver su contenido
Lo primero que vemos al ejecutar ḑf son una serie de filas y columnas.
Lo primero raro es que hay una columna llamada Row ID y a su izquierda a una columna sin nombre que tiene una enumeración.
Dentro del archivo original, el Row ID es la columna indice, pero Pandas no detecta esto y la crea por cada registro (fila) que exista en el Data Frame.
Para evitar que se duplique usamos el siguiente comando:
df = df.set_index('Row ID')
Usamos el comando
df.dtypes
Veremos que la mayoria de las columnas tienen a su derecha un nombre, la mayoria son object y eso está mal, pues tenemos valores numericos, de fecha, numeros enteros y flotantes.
Para acomodar esto usamos:
df = df.convert_dtypes()
Esto hará una conversión aproximada a los tipos de datos que tenemos. Si volvemos a usar df.dtypes ahora el resultado será distinto.
Sin embargo ‘Order Date’ y ‘Ship Date’ todavía no tiene el tipo de dato correcto.
Estos son datos datetime arreglamos esto rapido usando:
df['OrderDate'] = pd.to_datetime(
df['OrderDate'],
dayfirst = True,
errors = 'coerce'
)
df['Ship Date'] = pd.to_datetime(
df['Ship Date'],
dayfirst = True,
errors = 'coerce'
)
Si ejecutamos de nuevo df.dtypes ya estará todo listo.
Agrupando y graficando
<h3>Pregunta 1: ¿Cuál es la categoría de productos más vendida?</h3>Esto se responde de una manera sencilla. Tenemos que ver el total de registros que en su columna Category tengan el nombre de alguna categoria. En otras palabras ver cuantas veces se repite esa categoria en el total de registros.
Eso lo obtenemos usando:
df['Category'].value_counts()
Veremos que esto nos devuelve una especie de tabla donde vemos el nombre de las categorias que tenemos y la cantidad de ventas realizadas por categoria. Pero vamos a graficar. Borra esa linea de codigo anterior o agrega lo siguiente:
df['Category'].value_counts().plot(kind="bar", fontsize = 15, color=['red', 'orange', 'blue'], figsize=(10,10))
plot.xticks(rotation = 45)
plot.xlabel('Categorias')
plot.ylabel('Cantidad de ventas')
plot.title('Categorias más vendidas')
plot.grid(axis='y')
plot.savefig('cat-sold.png')
Quedará algo como esto:
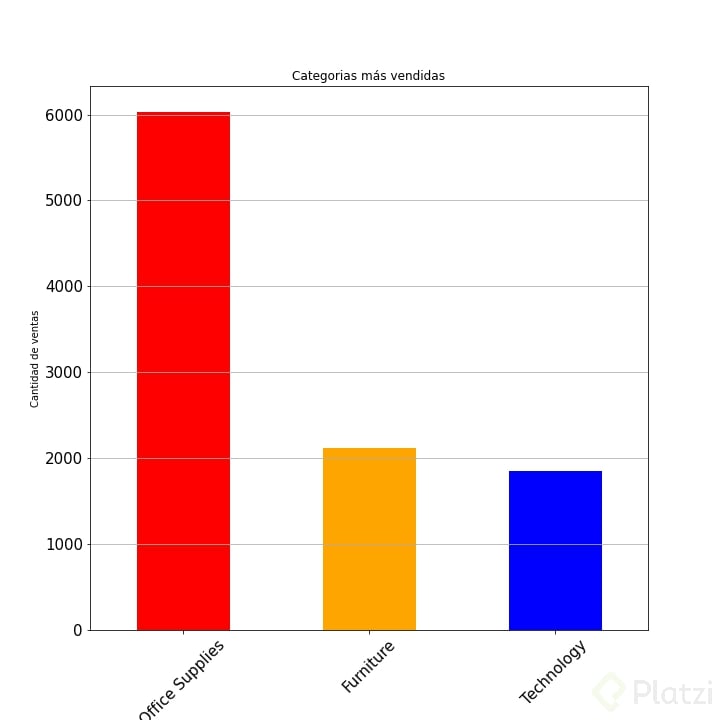
- con plot() llamamos a la librería de matplotlib.pyplot para graficar. y en su paramero kind le indicamos el tipo de grafica. En este caso “bar”. fontsize para determinar el tamaño de la letra. color para darle colores distintos a cada barra. figsize para cambiar el tamaño de la figura.
- plot.xticks(rotation=45) permite hacer que los nombres de las etiquetas en el eje de las X roten 45 grados.
- plot.xlabel(‘Categorias’) para darle nombre al eje X
- plot.ylabel(‘Cantidad de ventas’) para darle nombre al eje Y
- plot.title(‘Categorias más vendidas’) para darle titulo a la grafica
- plot.grid(axis=‘y’) para mostrar la grilla en el eje de las Y
- plot.savefig(‘nombre-imagen.formato’) nos permite guardar esa grafica como imagen.
Primera pregunta, resuelta.
<h3>Pregunta 2: ¿Quién es el cliente que compra más?</h3>Esta pregunta se resuelve de dos formas.
- Ubicar los clientes en función a cuantos gastan
- Ubicar cuantas veces se repite el nombre del cliente en los registros para saber con que frecuencia compran.
En mi caso optaré por la 1 usando el siguiente codigo:
cs = df.groupby('Customer Name')['Sales'].sum()
pr = cs.loc[cs > 12000]
pr.sort_values().plot(kind='barh', figsize=(20,10), fontsize=18, color=choice_c)
plot.grid(axis='x')
plot.title('Clientes más frecuentes', fontsize=18)
plot.ylabel('Cliente', fontsize=18)
plot.xlabel('Totalde compras', fontsize=18)
plot.savefig('customers.png')
Fijate que en color= hay una variable no definida todavía llamada choice_c. Es para generar un recorrido aleatorio de colores según la cantidad de clientes existentes. Te dejo esa función para que la definas y la uses:
color_w = ['b', 'g', 'r', 'c', 'm', 'y', 'k']
choice_c = []
foriin pr:
c = random.choice(color_w)
choice_c.append(c)
Una vez graficado te debería quedar algo así:
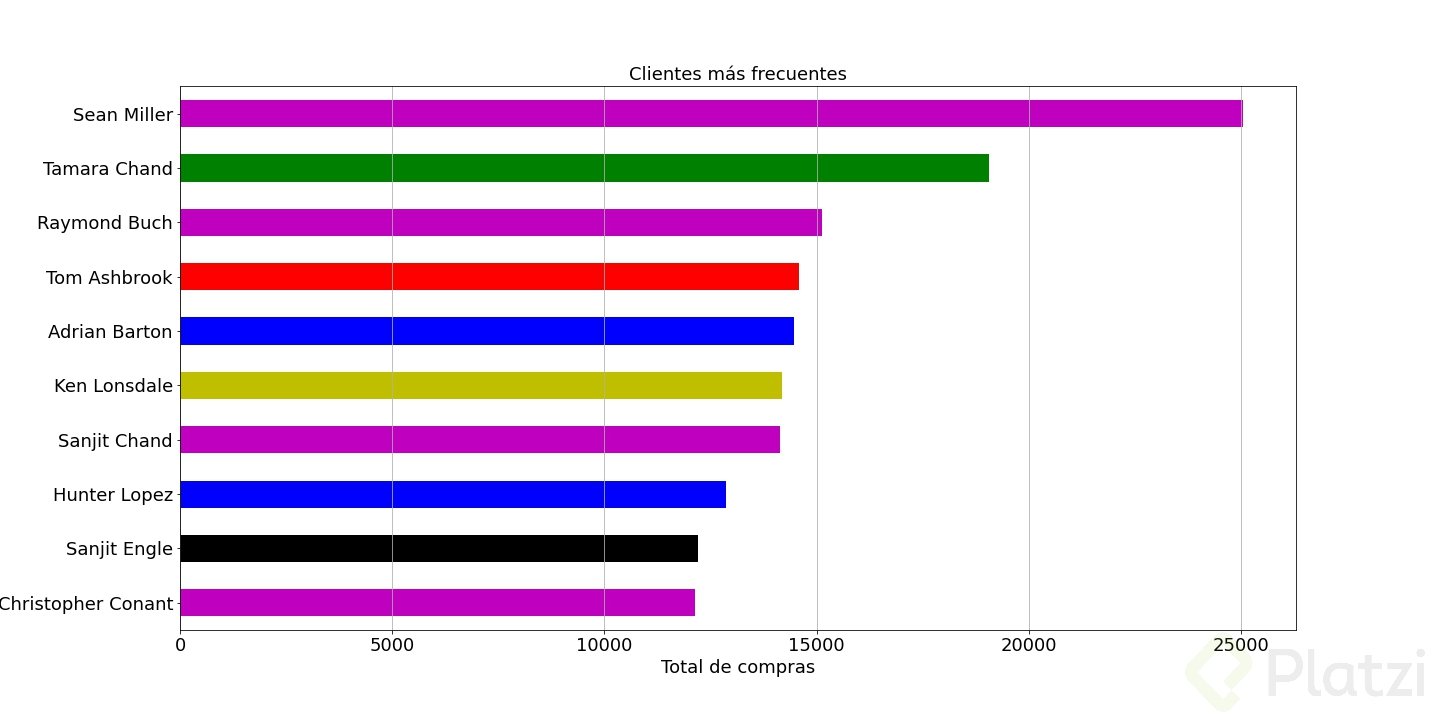
- usando
groupby('Customer Name')['Sales'].sum()puedo agrupar los clientes en función a la suma (sum) de cuanto han gastado (‘Sales’) - luego usando .loc[cs > 12000] le digo que solo me muestre clientes que hayan gastado más de 12k. Esto debido a que hay muchos clientes y nos importa los que gasten más
- por ultimo le digo
.sort_values()para que los ordene y usoplot(kind='barh')en este caso “barh” es para graficar barras horizontales.
El resto de comandos se explicaron en la grafica anterior.
Segunda pregunta, resuelta.
<h3>Pregunta 3: ¿En qué Trimestre (Q) se realizan más ventas?</h3>Para responder esta pregunta necesitamos 2 cosas
- La fecha de la orden
- La suma de las ventas
Para esto vamos a usar dos columnas y creamos un Data Frame a partir de dos columnas, usando:
new_data = df[['Order Date', 'Sales']]
Podemos usar new_data para ver su contenido.
Ahora que tenemos estos datos apartados, necesitamos quitar ese Row ID pues, lo que nos guiará para graficar esta información son los años, serán nuestros indices y nuestros valores en el eje X de la grafica.
Para eso usamos:
new_data.set_index('OrderDate', inplace=True)
usando inplace=True le decimos que cambie el indice y se guarde de una vez se ejecute el codigo.
Si vuelves a usar new_data verás que ya el Row ID no existe y ahora nuestro indice son las fechas de cada transacción.
Pero ahora solo queremos saber en que año fue y en que trimestre del año pasó un conjunto de transacciones. Para esto debemos crear dos columnas, una que nuestros muestre el año y otros que no muestre el trimestre de ese año.
Usamos
new_data['freq'] = new_data.index.quarter
new_data['year'] = new_data.index.year
donde freq son los trimestres (Q) del año.
Si ejecutamos new_dataotra vez, verás que tenemos dos columnas nuevas.
Ahora tenemos un nuevo reto:
- Nuestros indices deben ser los años.
- Nuestras columnas deben ser los trimestres (freq)
- Los valores de cada Filax*Columna debe ser el TOTAL de transacciones ocurridas durante ese año Y trimestre
Para lograr esto debemos hacer una transformación, en Pandas llamado Pivot. Usaremos lo siguiente:
pivot = pd.pivot_table(
new_data,
index='year',
values='Sales',
aggfunc='count',
columns='freq'
)
Donde:
- new_data hace referente a la tabla (Data Frame) que le haremos Pivot
- index=‘year’ para decirle cuales serán nuestros nuevos indices
- values=‘Sales’ para decirle cuales serán los valores de las FilasxColumnas
- aggfunc=‘count’ para tener el conteo de las transacciones. Si no lo ponemos por defecto usa ‘mean’ o sea, nos calculará la media.
- columns=‘freq’ para decirle cuales serán nuestras nuevas columnas.
Ahora si llamamos a pivot veremos la mágia lista.
Por ultimo nos queda graficar para ver que ha pasado de manera visual. Usamos:
pivot.plot(kind='bar', figsize=(10,10), fontsize=18)
plot.xlabel('Años', fontsize=18)
plot.ylabel('Total de ventas', fontsize=18)
plot.title('Ventas por cada cuarto de año', fontsize=18)
plot.legend(labels=['Q1', 'Q2', 'Q3', 'Q4'], fontsize=18)
plot.xticks(rotation=0)
plot.grid(axis='y')
plot.savefig('solds-per-q.png')
Quedará algo así:
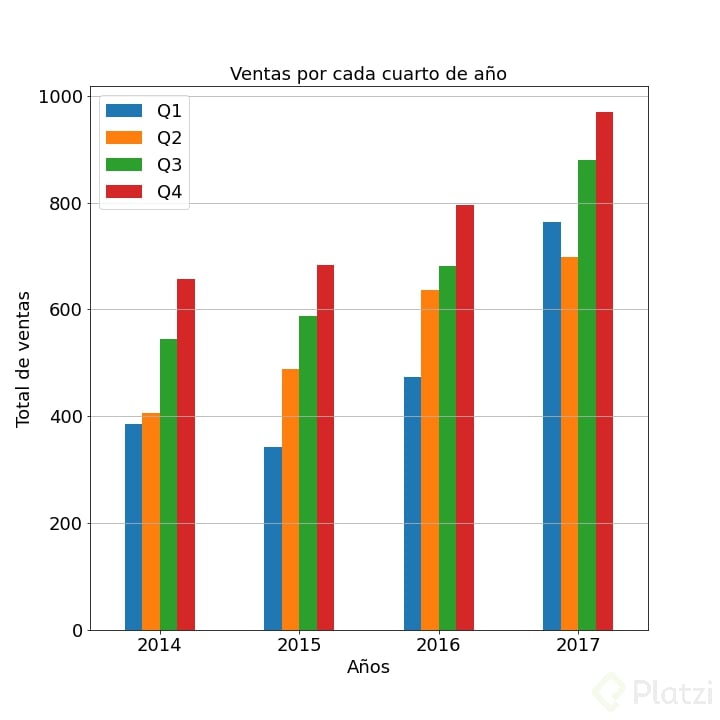
Y el unico comando nuevo aquí es:
plot.legend(labels=) en el cual reescribimos el nombre de nuestros valores en nuestra grafica, para que sea más intuitivo.
Pregunta tres, resuelta.
Fin
Espero te haya servido esta guiá de graficacion y tratado de datos con Pandas y Matplotlib.
¿Tienes algunas mejoras al codigo? Te leo en la caja de comentarios
Curso de Principios de Visualización de Datos para Business Intelligence (2021)
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE



