

GLM-5.2 es el nuevo modelo chino de frontera que Z.ai lanzó en junio de 2026 y ya se metió en la conversación. Programa mejor que GPT-5.5 en varias pruebas, se acerca a Claude Opus 4.8 y lo puedes descargar gratis. Si sigues la carrera de la IA o escribes código, esto te interesa.
¿Qué es GLM-5.2 y qué lo hace diferente?
Lo creó Z.ai, una empresa china antes conocida como Zhipu AI, y entra en la categoría de modelo de frontera: el grupo de los sistemas de IA más avanzados del momento. Su gran apuesta es el contexto largo.
GLM-5.2 maneja hasta 1 millón de tokens, donde un token es la unidad mínima con la que un modelo lee y mide texto. En la práctica, eso alcanza para cargar un proyecto de software entero (código, pruebas y documentación) sin perder el hilo a mitad de camino.
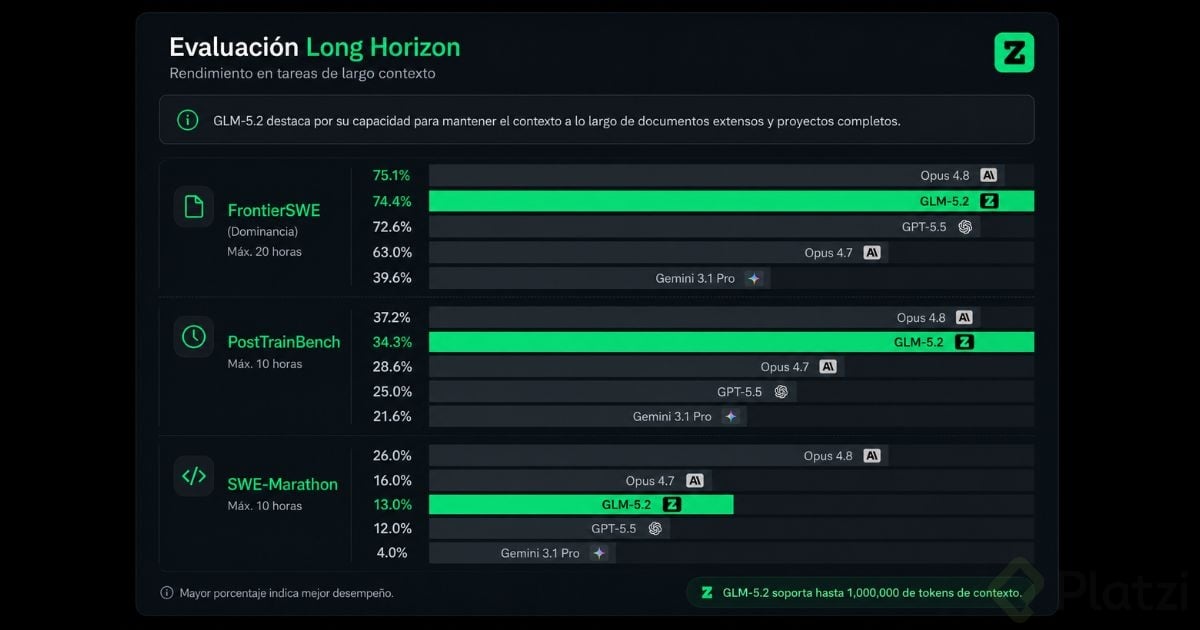
La otra apuesta es que es open source bajo licencia MIT, una de las más permisivas que existen: puedes descargar el modelo, desplegarlo en tu propio servidor y usarlo sin pagar por API ni lidiar con restricciones según tu país.
¿Qué es GLM-5.2? Es un modelo de lenguaje open source de la empresa china Z.ai, enfocado en tareas largas de programación. Maneja hasta 1 millón de tokens de contexto y se descarga gratis bajo licencia MIT.
¿Es GLM-5.2 mejor que GPT-5.5, Gemini y Claude?
En las pruebas de programación los números lo respaldan. Un benchmark es una prueba estandarizada para comparar modelos bajo las mismas reglas, y aquí GLM-5.2 quedó arriba:
- En Terminal-Bench 2.1 sacó 81.0, frente al 62.0 de GLM-5.1, a cuatro puntos de Claude Opus 4.8 (85.0) y por encima de Gemini 3.1 Pro.
- En SWE-bench Pro subió a 62.1, superando a GPT-5.5 (58.6).
- En FrontierSWE se quedó a apenas 1% de Opus 4.8 y volvió a ganarle a GPT-5.5.
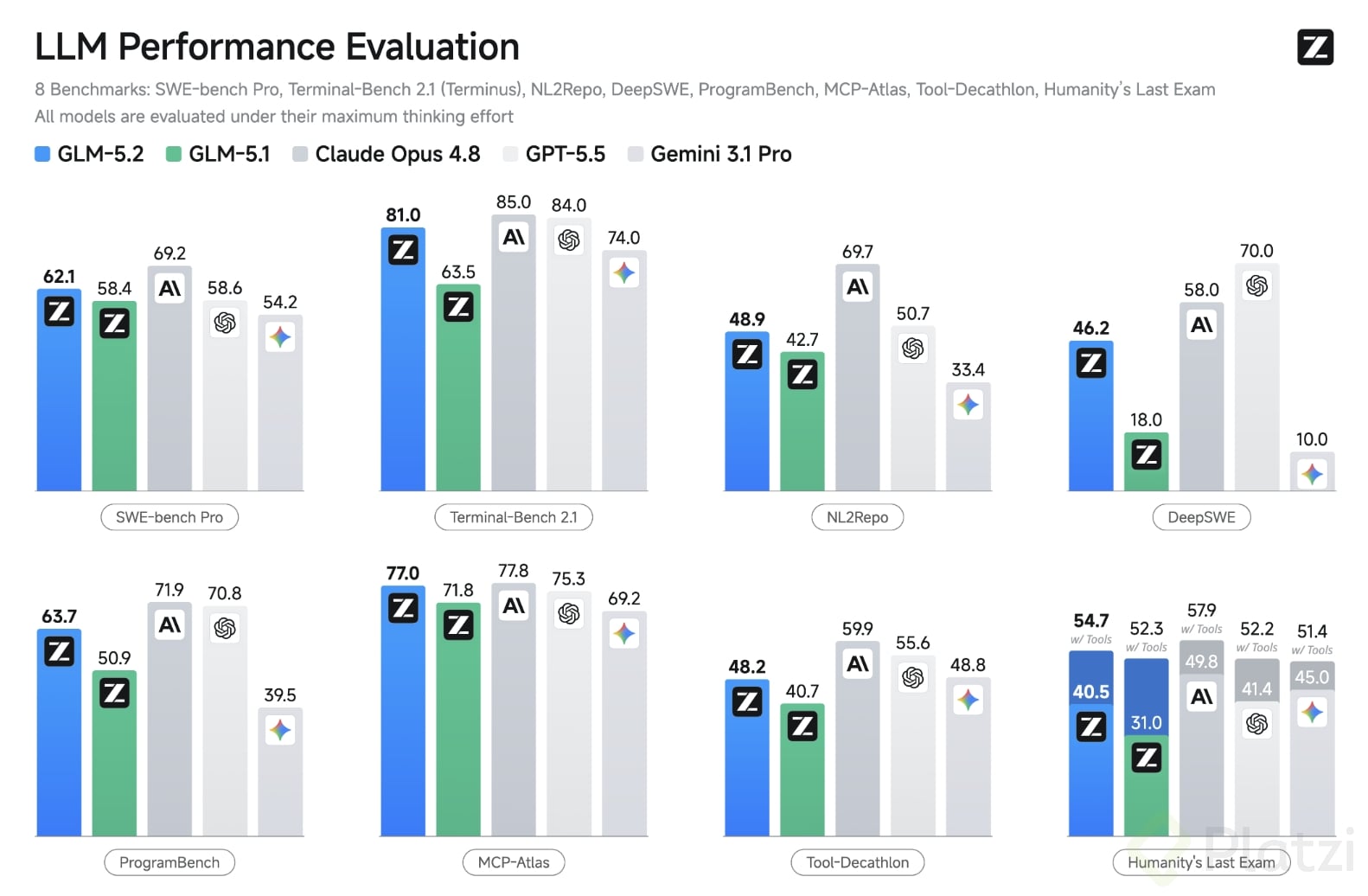
Más interesante todavía: en Code Arena, una clasificación que se arma con votos humanos a ciegas y es mucho más difícil de manipular que los números que reporta cada empresa, quedó segundo en el mundo y primero entre los modelos que hoy puedes usar. Donde más brilla GLM-5.2 es en tareas largas de código (refactors de varios archivos, proyectos completos) y en diseño web, donde encabezó el ranking de Design Arena.
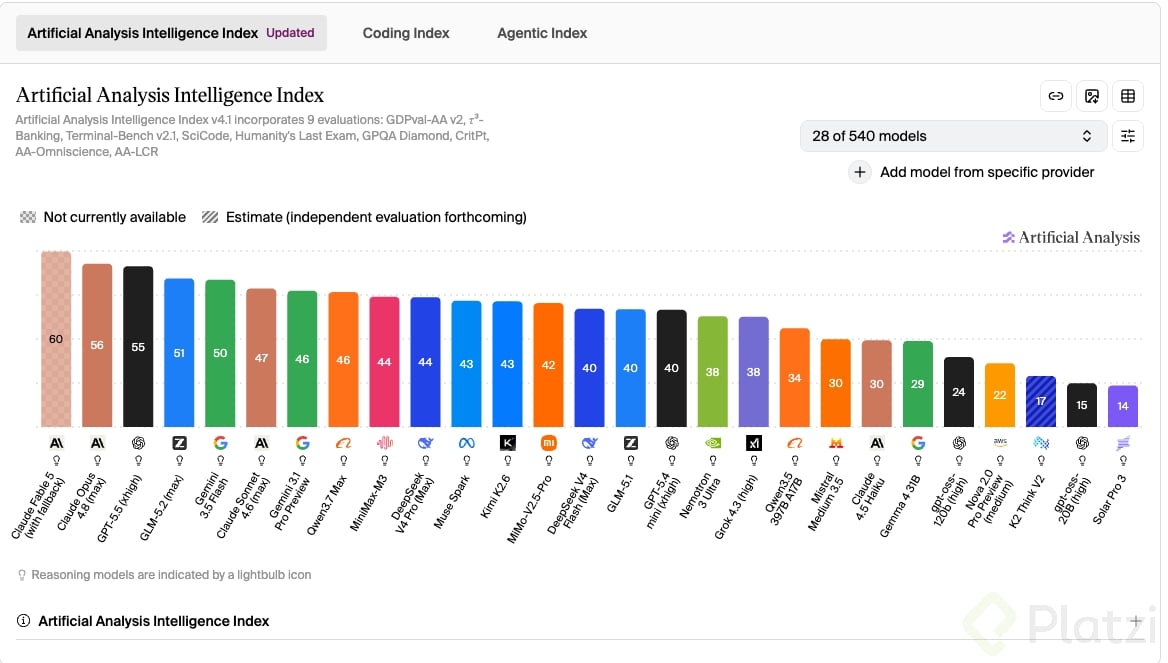
Conviene una aclaración para no exagerar: ese liderazgo es en código. Si miras inteligencia general, el índice de Artificial Analysis, que combina 9 evaluaciones distintas, deja a GLM-5.2 en cuarto lugar con 51 puntos, detrás de Claude Opus 4.8 (56) y GPT-5.5 (55), y apenas por encima de Gemini 3.5 Flash (50). Para programar le pelea a lo mejor, pero no es el modelo más inteligente en todo.
La reacción de los desarrolladores fue casi unánime: entusiasmo. Herramientas como Kilo Code lo integraron el mismo día. Pero hubo una crítica que se repitió. Z.ai presentó el modelo el 13 de junio sin una sola tabla de benchmarks y recién los publicó el 17, junto con los pesos. Para muchos, eso olió a marketing primero y datos después.
¿Por qué GLM-5.2 responde que es Claude?
Aquí viene el detalle más curioso. Cuando le preguntas a GLM-5.2 quién es, a veces contesta que es Claude, de Anthropic. No es un error de marketing: es una pista de cómo lo entrenaron.
La explicación más probable es que durante el post-entrenamiento usaran a Claude como profesor. GLM-5.2 generaba respuestas y Claude servía de referencia para validarlas. Esas trazas de razonamiento, es decir las cadenas de pensamiento (CoT) y los resultados, se convierten en datasets para una fase de aprendizaje por refuerzo, donde el modelo aprende a pensar mejor.
Y aquí conviene frenar un mito: esto no es robar datos. Un modelo ya entrenado no se puede descomprimir para sacar con qué se entrenó. Lo que se reutiliza no es la información original de Claude, sino su forma de razonar frente a cada tarea.
¿Qué es la destilación de un modelo de IA? Es una técnica donde un modelo más pequeño aprende imitando las respuestas de uno más grande y capaz. El grande hace de profesor y el pequeño copia su forma de razonar para acercarse a su nivel.
Lo fascinante es lo que revela: un modelo puede copiar la forma de pensar de otro tan a fondo que herede hasta su sentido de quién es.
¿Conviene usar GLM-5.2? Lo bueno y lo incómodo
Lo bueno es claro: es el mejor modelo de código open source disponible hoy, rinde cerca de la frontera y, dentro de su Coding Plan, cuesta entre 5 y 10 veces menos que Claude Opus 4.8 o GPT-5.5. Para experimentar o construir, es una ganga.
Lo incómodo aparece al elegir cómo lo usas. Si lo corres por la API en la nube de Z.ai, tus datos pasan por servidores sujetos a la ley de inteligencia de China, que obliga a las empresas chinas a cooperar con el Estado cuando se los pide. Hacer self-host, es decir correrlo en tu propia infraestructura, evita ese riesgo, pero el modelo completo pide cerca de 1.5 TB de memoria de GPU: fuera del alcance de casi cualquier equipo. Y hay otro dato a tener en cuenta: Zhipu está en la Entity List de Estados Unidos desde enero de 2025, una lista de empresas con restricciones comerciales.
¿Es seguro usar GLM-5.2? Depende de cómo. Hacer self-host con los pesos descargados es lo más seguro, porque tus datos nunca salen de tu servidor. Usar su API en la nube expone tu código a la legislación china. Para proyectos sin datos sensibles es práctico; para código confidencial, mejor self-host u otro modelo.
¿Ya lo probaste? Cuéntanos en los comentarios cómo te fue. Y si quieres entender de fondo cómo funcionan estos modelos y sacarles partido, en Platzi tenemos nuestra AI Academy para que entiendas desde los fundamentos de AI, hasta la Ingeniería de Aplicaciones con LLMs y Agentes.
Curso Gratis de Introducción a la Inteligencia Artificial
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


