Entre 2028 y 2030, el mundo no va a tener suficiente energía para sostener el ritmo actual de entrenamiento y servir modelos.
Esta es la alarma que acaba de prender Naveen Rao, neurocientífico y exjefe de IA en Databricks, que lleva 30 años pensando en los límites físicos de la IA.
Su charla más reciente plantea algo incómodo para quienes asumimos que el cómputo siempre podrá escalar. Estamos construyendo máquinas para la inteligencia artificial sobre un sustrato de 80 años pensado para otra cosa, y la física empieza a pasar la cuenta.
La charla completa de Rao está acá:
¿Cuánta energía consume la IA hoy y cuánta queda en el mundo?
Para entender el tamaño del problema ayuda comparar dos cifras. El planeta produce alrededor de 9,000 gigavatios de capacidad eléctrica, y eso alimenta absolutamente todo: calefacción, autos eléctricos, industria, hogares. Mientras tanto, los centros de datos ya queman varios gigavatios solo en entrenar y servir modelos.
Si proyectas el crecimiento de inferencia y entrenamiento tres o cuatro años hacia adelante, la curva se come la capacidad disponible. Por eso se habla de fusión nuclear, de centros de datos en el espacio o de redes dedicadas: no es ciencia ficción, es presupuesto energético.
¿Cuánta energía consumen los centros de datos de IA? Ya consumen varios gigavatios al año y, según Rao, podrían superar la capacidad eléctrica disponible entre 2028 y 2030 si el ritmo de entrenamiento e inferencia se mantiene.
¿Qué dice el principio de Landauer sobre la inteligencia por vatio?
El principio de Landauer establece un piso termodinámico para el cómputo: hay una cantidad mínima de energía que se necesita para procesar un bit, y por debajo de ese umbral no se puede bajar. Es física, no ingeniería.
Rao lo grafica como una asíntota a la que distintos sistemas se acercan en distintos grados:
- La biología vive cerca de ese límite, separada apenas por dos órdenes de magnitud.
- Los chips actuales, fabricados con litografía 2D, están unos tres órdenes de magnitud por debajo de la biología.
- Cinco órdenes de magnitud separan tu GPU favorita del piso físico de Landauer.
O sea, hay un margen enorme de mejora que la industria todavía no ha explorado, porque seguimos construyendo sobre la arquitectura que heredamos de los años 40.
¿Por qué el cerebro humano es más eficiente que cualquier GPU?
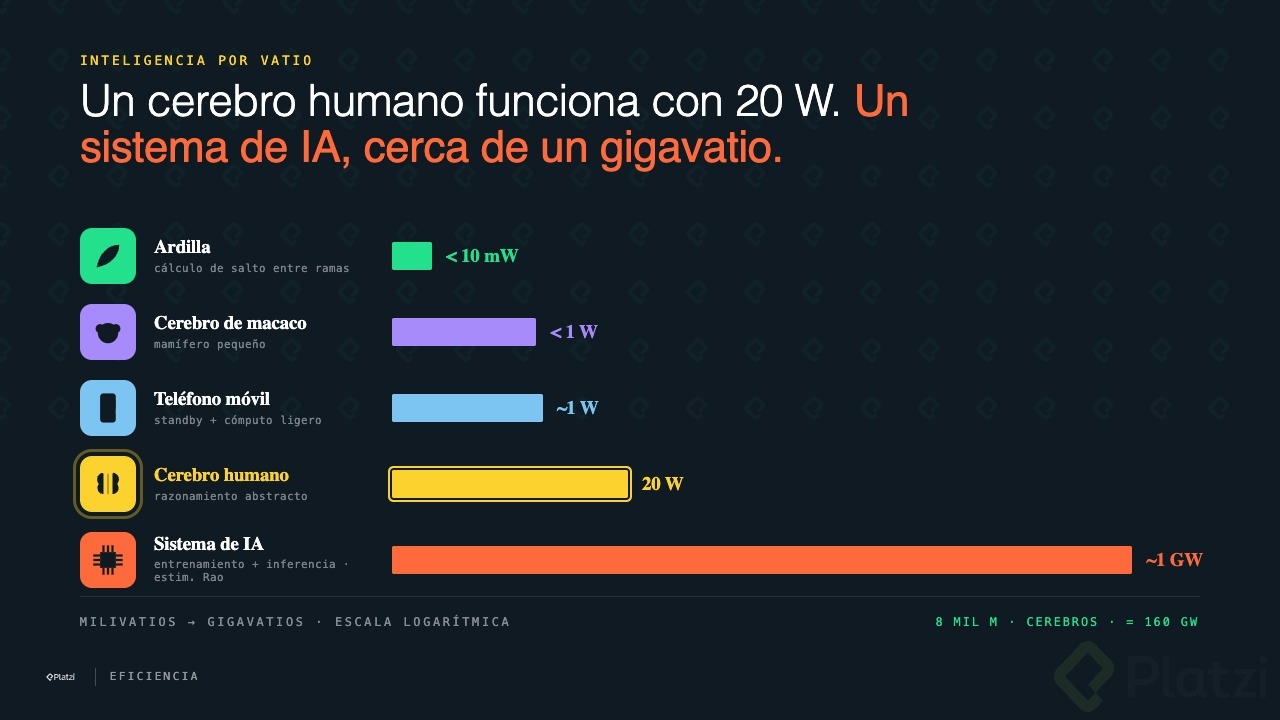
Aquí está el número que pega. El cerebro humano consume apenas 20 vatios. Multiplica eso por los 8,000 millones de personas en el mundo y obtienes 160 gigavatios para toda la humanidad pensante.
Y no es solo el humano. Mira la escala que arma Rao:
- Sistema de IA en producción (entrenamiento + inferencia): del orden de megavatios, cerca de un gigavatio.
- Cerebro humano: 20 vatios.
- Teléfono móvil: alrededor de 1 vatio.
- Cerebro de un macaco: menos de 1 vatio.
- Ardilla saltando entre ramas: menos de 10 milivatios (1/100 de un teléfono).
Una ardilla calcula viento, distancia y aterrizaje con esa miseria de energía. Ningún sistema artificial actual logra esa coordinación con tan poca electricidad.
La razón, según Rao, no es que el cerebro use mejor matemática. Es que no usa matemática matricial en absoluto. El cerebro computa con dinámicas no lineales: interacciones que varían en el tiempo entre neuronas, donde el cálculo no es determinista ni binario sino estocástico. Equivocarse por un bit no rompe el sistema, lo que en un chip digital sería catastrófico.
¿Cuántos vatios consume el cerebro humano? Cerca de 20 vatios, menos que una bombilla LED. Toda la humanidad junta usaría 160 gigavatios solo en pensar.
¿Qué es la computación dinámica y por qué rompe con von Neumann?
La propuesta de Unconventional AI, la startup que Rao acaba de fundar, es construir chips que imiten esa idea: osciladores acoplados de forma entrenable, donde la propia física del circuito hace el cálculo.
En una máquina von Neumann, el cuello de botella es mover datos entre memoria y procesador. Escribes estado, lo lees, operas, lo escribes de nuevo. Ese vaivén es lo que quema la mayoría de la energía.
En un sistema dinámico das un estado inicial, lo “pateas”, y dejas que el sistema evolucione por sí solo. El estado y el cómputo viven juntos en la física del chip.
Rao mostró un prototipo entrenable que ya genera imágenes simples partiendo de ruido y converge hacia clases aprendidas como caballos o gatos. No es una demo de pizarrón. Pasaron de cero equipo en enero de 2026 a un prototipo funcional en seis meses, gracias a que la propia IA acelera el diseño de hardware.
Pero, incluso si Unconventional AI acierta, los chips comerciales tardan años, así que la pared energética se va a sentir antes de que llegue esta solución al rescate.
¿Qué es una arquitectura no von Neumann? Es un diseño donde la memoria y el procesamiento no están separados. La información se almacena y se transforma en el mismo sustrato físico, eliminando el coste energético de transferir datos.
Si Rao tiene razón, el escalamiento por fuerza bruta tiene fecha de caducidad. La siguiente ola de progreso no va a venir de modelos más grandes corriendo sobre más GPUs, sino de repensar el sustrato físico sobre el que corre el cómputo. La inteligencia por vatio se vuelve la nueva métrica de frontera, y los límites físicos de la IA dejan de ser un tema de paper para convertirse en problema de hoja de ruta.
Aprende más sobre machine learning y deep learning
Si quieres entender por dónde va el cómputo del futuro, recorre la Ruta de Machine Learning y Deep Learning de Platzi.
Y cuéntanos en los comentarios: ¿crees que la computación neuromórfica va a reemplazar a las GPUs antes de 2030, o seguiremos apostando por más datacenters? ¿Cuál crees que será la solución?
Curso de Fundamentos de Machine Learning
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE