Hola, chicos! dos cosas, usen python version inferior al 3.11, yo use 3.9 y no hubo lios(en dic-2022), lo segundo si no les corre gradio en el colab solo coloquen share=True en el launch
demo.launch(share=True)
import tensorflow as tf
import gradio as gr
import requests
import numpy as np
fromPILimportImagefrom tensorflow.keras.applications.inception_v3import decode_predictions
# Cargar modelo preentrenado
inception_net = tf.keras.applications.InceptionV3(weights='imagenet')# Descargar etiquetas
response = requests.get("https://git.io/JJkYN")labels = response.text.split("\n")def clasifica_imagen(imagen): # Convertir el array a imagen PIL imagen =Image.fromarray(np.uint8(imagen)) # Redimensionar la imagen a 299x299
imagen = imagen.resize((299,299)) # Convertir la imagen a un array de NumPy imagen = np.array(imagen) # Asegurarse de que la imagen tiene 3 canales
if imagen.ndim==2: imagen = np.stack([imagen]*3, axis=-1) # Preprocesar la imagen para el modelo
imagen = tf.image.convert_image_dtype(imagen, dtype=tf.float32) imagen = tf.keras.applications.inception_v3.preprocess_input(imagen) # Añadir una dimensión batch
imagen = tf.expand_dims(imagen, axis=0) # Realizar la predicción
predicciones = inception_net.predict(imagen) confidences =decode_predictions(predicciones, top=3)[0]return{etiqueta:float(confianza)for(_, etiqueta, confianza)in confidences}# Crear la interfaz de Gradiodemo = gr.Interface(fn=clasifica_imagen, inputs=gr.Image(), outputs=gr.Label(num_top_classes=3))demo.launch(debug=True)```import tensorflow as tfimport gradio as grimport requestsimport numpy as npfrom PILimportImagefrom tensorflow.keras.applications.inception\_v3 import decode\_predictions
\# Cargar modelo preentrenadoinception\_net = tf.keras.applications.InceptionV3(weights='imagenet')\# Descargar etiquetasresponse = requests.get("https://git.io/JJkYN")labels = response.text.split("\n")def clasifica\_imagen(imagen): # Convertir el array a imagen PIL imagen =Image.fromarray(np.uint8(imagen)) # Redimensionar la imagen a 299x299 imagen = imagen.resize((299,299)) # Convertir la imagen a un array de NumPy imagen = np.array(imagen) # Asegurarse de que la imagen tiene 3 canales if imagen.ndim==2: imagen = np.stack(\[imagen] \*3, axis=-1) # Preprocesar la imagen para el modelo imagen = tf.image.convert\_image\_dtype(imagen, dtype=tf.float32) imagen = tf.keras.applications.inception\_v3.preprocess\_input(imagen) # Añadir una dimensión batch imagen = tf.expand\_dims(imagen, axis=0) # Realizar la predicción predicciones = inception\_net.predict(imagen) confidences = decode\_predictions(predicciones, top=3)\[0]return{etiqueta:float(confianza)for(\_, etiqueta, confianza)in confidences}\# Crear la interfaz de Gradiodemo= gr.Interface(fn=clasifica\_imagen, inputs=gr.Image(), outputs=gr.Label(num\_top\_classes=3))demo.launch(debug=True)
La liga con las etiquetas no esta funcionando, en su lugar use:
def classify_imagen(inp): inp = inp.reshape((-1,224,224,3)) inp = tf.keras.applications.mobilenet_v2.preprocess_input(inp) # Modificacion en reshape, para que funcione con decode_predictions
prediction = inception_net.predict(inp).reshape(1,1000) # Nuevo metodo para etiquetar predicciones
pred_labels = tf.keras.applications.mobilenet_v2.decode_predictions(prediction, top=100) confidence ={f'{pred_labels[0][i][1]}':float(pred_labels[0][i][2])for i inrange(100)}return confidence
Al comienzo de la corrida, ambos códigos (el de Omar y el de Miguel) mostraron: "Something went wrong Unexpected end of JSON input ". Al intentar otras veces la corrida y con reinicio del colab runtime, ambos códigos de función corrieron correctamente con igual resultado para banana de 97%. No se entiende la causa esto.
9/062025 - Respuesta asistida por ChatGPT 04-mini
¡Hola a todos! Quería compartir que acabo de actualizar las librerías de mi proyecto y ya está todo funcionando con las versiones más recientes. El resultado de pip install --upgrade fue:
Gradio 5.33.0: acceso a las últimas mejoras en la interfaz de usuario y nuevas opciones de personalización.
gradio-client 1.10.2: compatibilidad y correcciones en las llamadas desde cliente.
Groovy 0.1.2, huggingface-hub 0.32.4 y Ruff 0.11.13: actualizaciones menores para mejorar la calidad de código y el soporte de modelos.
Si alguien está usando estas herramientas, ¡recomiendo esta actualización para evitar problemas de compatibilidad y aprovechar las nuevas funciones!
import tensorflow as tf
from PIL import Image
import requests
import gradio as gr
# Cargar el modelo MobileNetV2 preentrenado en ImageNetdefload_model(): model = tf.keras.applications.MobileNetV2( include_top=True, weights="imagenet")return model
mobile_net = load_model()# Obtener etiquetas de ImageNetresponse = requests.get("https://git.io/JJkYN")etiquetas = response.text.split("\n")# Función de clasificación de imagendefclasifica_imagen(inp):try:# Convertir entrada a tensor de TensorFlow tensor = tf.convert_to_tensor(inp)# Redimensionar a 224x224 tensor = tf.image.resize(tensor,[224,224])# Asegurar tipo float32 tensor = tf.cast(tensor, tf.float32)# Añadir dimensión de batch: (1, 224, 224, 3) batch = tf.expand_dims(tensor, axis=0)# Preprocesar según MobileNetV2 batch = tf.keras.applications.mobilenet_v2.preprocess_input(batch)# Predicción preds = mobile_net.predict(batch).flatten()# Mapeo de etiquetas a probabilidades confidences ={etiquetas[i]:float(preds[i])for i inrange(len(preds))}return confidences
except Exception:import traceback
traceback.print_exc()return{"error":1.0}# Interfaz Gradiodemo = gr.Interface( fn=clasifica_imagen, inputs=gr.Image(type="pil", height=224, width=224),# Imagen PIL con tamaño fijo outputs=gr.Label(num_top_classes=3),# Mostrar top 3 clases title="Clasificador MobileNetV2", description="Sube una imagen para ver las 3 clases más probables usando MobileNetV2.")# Lanzar la interfazif __name__ =="__main__": demo.launch(share=True)
a continuación las "20.000" explicaciones que el pedí a ChatGPT
Respuesta asistida por ChatGPT o4-mini
Ese fragmento:
# Lanzar la interfazif __name__ =="__main__": demo.launch(share=True)
cumple dos propósitos:
Protección de punto de entrada
La condición if __name__ == "__main__": asegura que el bloque de código solo se ejecute cuando el archivo se corre directamente como script, y no cuando se importa desde otro módulo. Así evitas que la interfaz de Gradio arranque automáticamente si, por ejemplo, alguien hace import tu_script en otro código.
Arranque de la demo de Gradio
Dentro de ese bloque se llama a demo.launch(share=True), lo que:
Inicia un servidor local que hospeda la interfaz web de Gradio.
Con share=True, además genera un enlace público temporal (en los servidores de Gradio) que puedes compartir con terceros, de modo que cualquiera con esa URL pueda probar tu modelo sin necesidad de acceso a tu máquina.
En conjunto, este patrón es muy común en scripts de Python para definir claramente el “punto de entrada” de la aplicación y controlar cuándo y cómo se pone en marcha la interfaz de usuario.
Respuesta asistida por ChatGPT o4-mini
PIL.Image forma parte de Pillow, la biblioteca de procesamiento de imágenes en Python (sucesora de la antigua PIL). Concretamente:
Qué es
Es un módulo (PIL.Image) que define la clase Image, la representación interna de una imagen en memoria.
Una instancia de Image encierra datos como el tamaño, el modo (RGB, L, CMYK…), y el propio píxel-mapa.
Para qué sirve
Abrir y cargar archivos de disco en distintos formatos (JPEG, PNG, BMP, GIF…):
from PIL import Image
img = Image.open("foto.jpg")
Inspeccionar propiedades de la imagen (tamaño, modo, metadatos EXIF):
Recortar, rotar, voltear, cambiar modo de color, aplicar filtros básicos…
Convertir entre formatos de datos:
A y desde arrays NumPy (para alimentar modelos de ML).
A tensores de TensorFlow directamente con tf.convert_to_tensor(img).
Guardar resultados en disco o en memoria:
img2.save("miniatura.png")
En resumen, PIL.Image es la piedra angular en Python para trabajar con imágenes: leerlas, modificarlas y pasarlas a otras librerías (NumPy, TensorFlow, OpenCV…) en tus flujos de visión por computador o procesamiento gráfico.
codigo actualizado a 08/2025 del ejemplo 2
from transformers import pipeline
import gradio as gr
model = pipeline("image-classification", model="microsoft/swin-tiny-patch4-window7-224")
def classify_image(image):
predictions = model(image)
return {pred["label"]: pred["score"] for pred in predictions}
title = "Mi primer Demo"
description = "Test con Hugging Face y Gradio"
demo = gr.Interface(
fn=classify_image,
inputs=gr.Image(type="pil", label="Selecciona la imagen"),
outputs=gr.Label(num_top_classes=5),
title=title,
description=description,
)
demo.launch()
Buenooo quedo super deprecado este curso?
es la última version: 4.32.0 funciona con este código:
Hola en la generación del primer Demo me sale un error con Jason. que puedo hacer
Importante!!
a Dic 2024, shape ya no existe. Pueden usar Height o Width
import gradio as gr
demo = gr.Interface(fn=clasifica_imagen, inputs = gr.Image(height=400, width=400), outputs = gr.Label(num_top_classes=3))demo.launch()
así es, complementé esta respuesta en un comentario el 09/06/2025
Ahora que estoy haciendo el curso, encuentro que hay algunas cosas desactualizadas. Dejo aquí los códigos actualizados para los ejemplos de los image_classifications:
Ejemplo 1:
import requestsimport numpy as npresponse = requests.get('https://git.io/JJkYN')labels = response.text.split('\n')def image_classification(inp): inp = tf.image.resize(inp, (224, 224)) inp = tf.keras.applications.mobilenet_v2.preprocess_input(inp.numpy()) inp = np.expand_dims(inp, axis=0) prediction = inception_net.predict(inp).flatten() confidences = {labels[i]: float(prediction[i]) for i in range(1000)} return confidences
from transformers import pipelineimport gradio as grmodel = pipeline("image-classification", model="microsoft/swin-tiny-patch4-window7-224")def classify_image(image): predictions = model(image) return {pred["label"]: pred["score"] for pred in predictions}
title = "Mi primer Demo"description = "Test con Hugging Face y Gradio"demo = gr.Interface( fn=classify_image, inputs=gr.Image(type="pil", label="Selecciona la imagen"), outputs=gr.Label(num_top_classes=5), title=title, description=description,)demo.launch()
Hola Comunidad. Por favor, su gentil ayuda:
import gradio as gr
demo = gr.Interface(fn = clasifica_imagen, inputs=gr.Image(shape=(224,224)), outputs=gr.Label(num_top_classes=3) )
demo.launch()
TypeError: Image.__init__() got an unexpected keyword argument 'shape'
Muchas gracias.
Es que en la nueva version, el argumento shape ya no existe, en su lugar están los parametros width y height
import tensorflow as tfimport gradio as grimport requestsimport numpy as npfrom PIL import Imagefrom tensorflow.keras.applications.inception_v3 import decode_predictions
# Cargar modelo preentrenadoinception_net = tf.keras.applications.InceptionV3(weights='imagenet')
# Descargar etiquetasresponse = requests.get("https://git.io/JJkYN")labels = response.text.split("\n")
def clasifica_imagen(imagen): # Convertir el array a imagen PIL imagen = Image.fromarray(np.uint8(imagen)) # Redimensionar la imagen a 299x299 imagen = imagen.resize((299, 299)) # Convertir la imagen a un array de NumPy imagen = np.array(imagen) # Asegurarse de que la imagen tiene 3 canales if imagen.ndim == 2: imagen = np.stack([imagen] * 3, axis=-1) # Preprocesar la imagen para el modelo imagen = tf.image.convert_image_dtype(imagen, dtype=tf.float32) imagen = tf.keras.applications.inception_v3.preprocess_input(imagen) # Añadir una dimensión batch imagen = tf.expand_dims(imagen, axis=0) # Realizar la predicción predicciones = inception_net.predict(imagen) confidences = decode_predictions(predicciones, top=3)[0] return {etiqueta: float(confianza) for (_, etiqueta, confianza) in confidences}
# Crear la interfaz de Gradiodemo = gr.Interface(fn=clasifica_imagen, inputs=gr.Image(), outputs=gr.Label(num_top_classes=3))demo.launch(debug=True)
La unica version que me funciona es la 4.15.0, ahorita estamos en la version 4.32.0 pero me da este error:
ValueError:The truth value of an array with more than one element is ambiguous.Use a.any() or a.all()
como arreglo este error?
Traceback(most recent call last):File"/usr/local/lib/python3.10/dist-packages/gradio/queueing.py", line 521,in process_events
response =await route_utils.call_process_api(File"/usr/local/lib/python3.10/dist-packages/gradio/route_utils.py", line 276,in call_process_api
output =await app.get_blocks().process_api(File"/usr/local/lib/python3.10/dist-packages/gradio/blocks.py", line 1945,in process_api
result =await self.call_function(File"/usr/local/lib/python3.10/dist-packages/gradio/blocks.py", line 1513,in call_function
prediction =await anyio.to_thread.run_sync(File"/usr/local/lib/python3.10/dist-packages/anyio/to_thread.py", line 33,in run_sync
returnawaitget_asynclib().run_sync_in_worker_thread(File"/usr/local/lib/python3.10/dist-packages/anyio/_backends/_asyncio.py", line 877,in run_sync_in_worker_thread
returnawait future
File"/usr/local/lib/python3.10/dist-packages/anyio/_backends/_asyncio.py", line 807,in run
result = context.run(func,*args)File"/usr/local/lib/python3.10/dist-packages/gradio/utils.py", line 831,in wrapper
response =f(*args,**kwargs)File"/usr/local/lib/python3.10/dist-packages/gradio/external.py", line 371,in query_huggingface_inference_endpoints
data =fn(*data) # type: ignore
File"/usr/local/lib/python3.10/dist-packages/huggingface_hub/inference/_client.py", line 1021,in image_classification
response = self.post(data=image, model=model, task="image-classification")File"/usr/local/lib/python3.10/dist-packages/huggingface_hub/inference/_client.py", line 259,in post
response =get_session().post(File"/usr/local/lib/python3.10/dist-packages/requests/sessions.py", line 637,in post
return self.request("POST", url, data=data, json=json,**kwargs)File"/usr/local/lib/python3.10/dist-packages/requests/sessions.py", line 568,in request
data=data or {},ValueError:The truth value of an array with more than one element is ambiguous.Use a.any() or a.all()```Este es mi código:
```python
import gradio as gr
titulo ="Mi primer demo con Hugging Face"descripcion ="Este es un demo ejecutado durante la clase"gr.load("huggingface/microsoft/swin-tiny-patch4-window7-224", inputs=gr.Image(label="Carga una imagen aqui"), title = titulo, description = descripcion
).launch(debug=True)```Porque como dice @LinaMarcela da error en gr.Interface.load por la version
Si tienen error en gr.Interface.load es porque la version de gradio 4.15.0 tiene algunos cambios. Revisando la documentacion, me funciono quitar la palabra Interface, es decir:
import gradio as gr
titulo ="Mi primer demo con Hugging Face"descripcion ="Este es un demo ejecutado durante la clase con Platzi."demo1 = gr.load("huggingface/microsoft/swin-tiny-patch4-window7-224", inputs=gr.Image(label="Carga una imagen aquí"), title = titulo, description = descripcion,).launch()```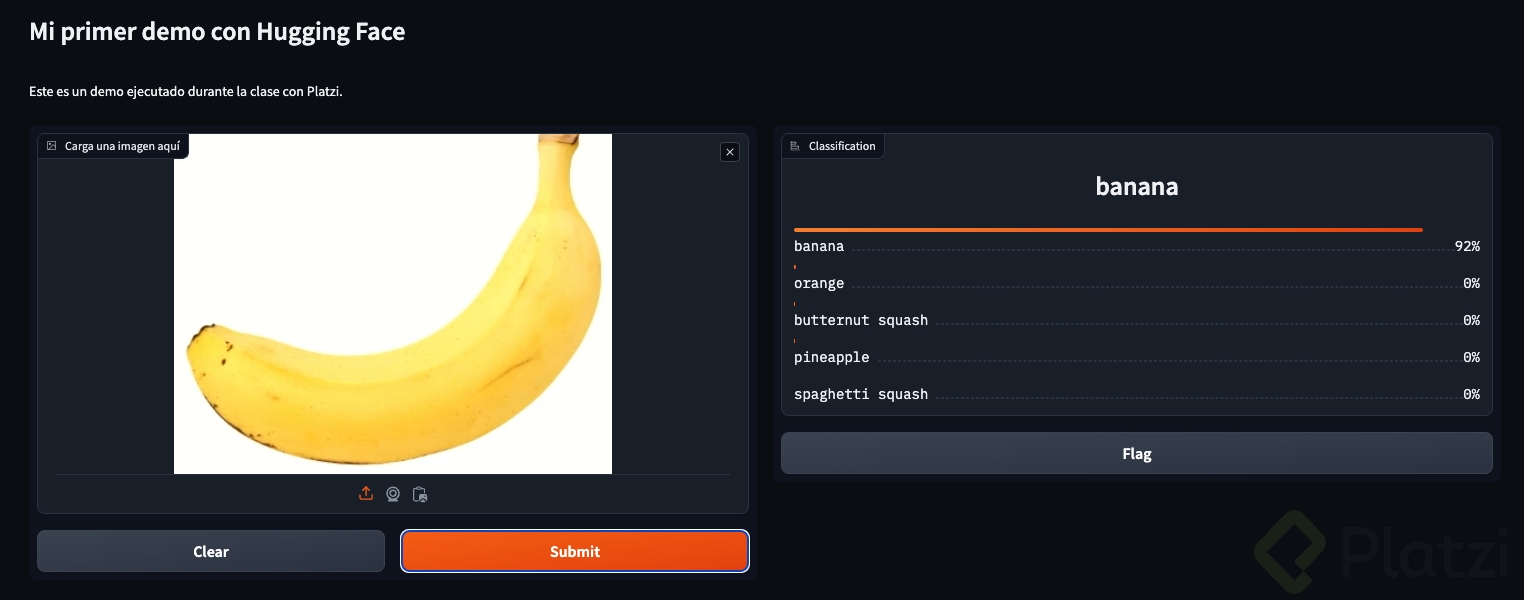
Hola, les dejo el código que me funcionó (enero 2024):






