Configuración del agente de infraestructura New Relic
Contenido del curso
APM avanzado
- 2

Qué es APM y sus señales doradas
04:43 min - 3

Buenas prácticas de configuración en APM
09:58 min - 4

Transacciones y métricas custom en New Relic
17:35 min - 5

Seguimiento de cambios en New Relic con GitHub Actions
16:44 min - 6

Métricas personalizadas y seguimiento de cambios en tableros de New Relic
05:58 min - 7

Métricas personalizadas y dashboards en New Relic
02:06 min
Agente de Infraestructura
- 8

Monitoreo de infraestructura con New Relic
03:09 min - 9

Agente de infraestructura New Relic en Docker
10:25 min - 10
Configuración del agente de infraestructura New Relic
Viendo ahora - 11

Métricas de infraestructura en New Relic: CPU, memoria y red
09:42 min - 12

Panel de infraestructura en New Relic sin consultas
05:25 min - 13

Configuración de alertas paramétricas para métricas de infraestructura
09:12 min - 14

Configuración de integraciones personalizadas con New Relic Flex
09:26 min - 15

Proyecto final: crea tu integración Flex para New Relic
00:31 min
Registros (Logs)
- 16

Gestión eficiente de registros con New Relic en sistemas distribuidos
02:39 min - 17
Envío de registros a New Relic mediante API directa
07:46 min - 18

Cómo filtrar logs en New Relic con Lucene
09:31 min - 19

Cómo convertir logs no estructurados con Grok
10:45 min - 20

Particiones de datos para gestionar logs de gran volumen
12:24 min - 21

Los registros en contexto conectan datos de APM con rastreo de errores
06:24 min - 22

Proyecto final: dashboard de logs
00:36 min
Optimizar el rendimiento
Configuración del agente de infraestructura New Relic
Resumen
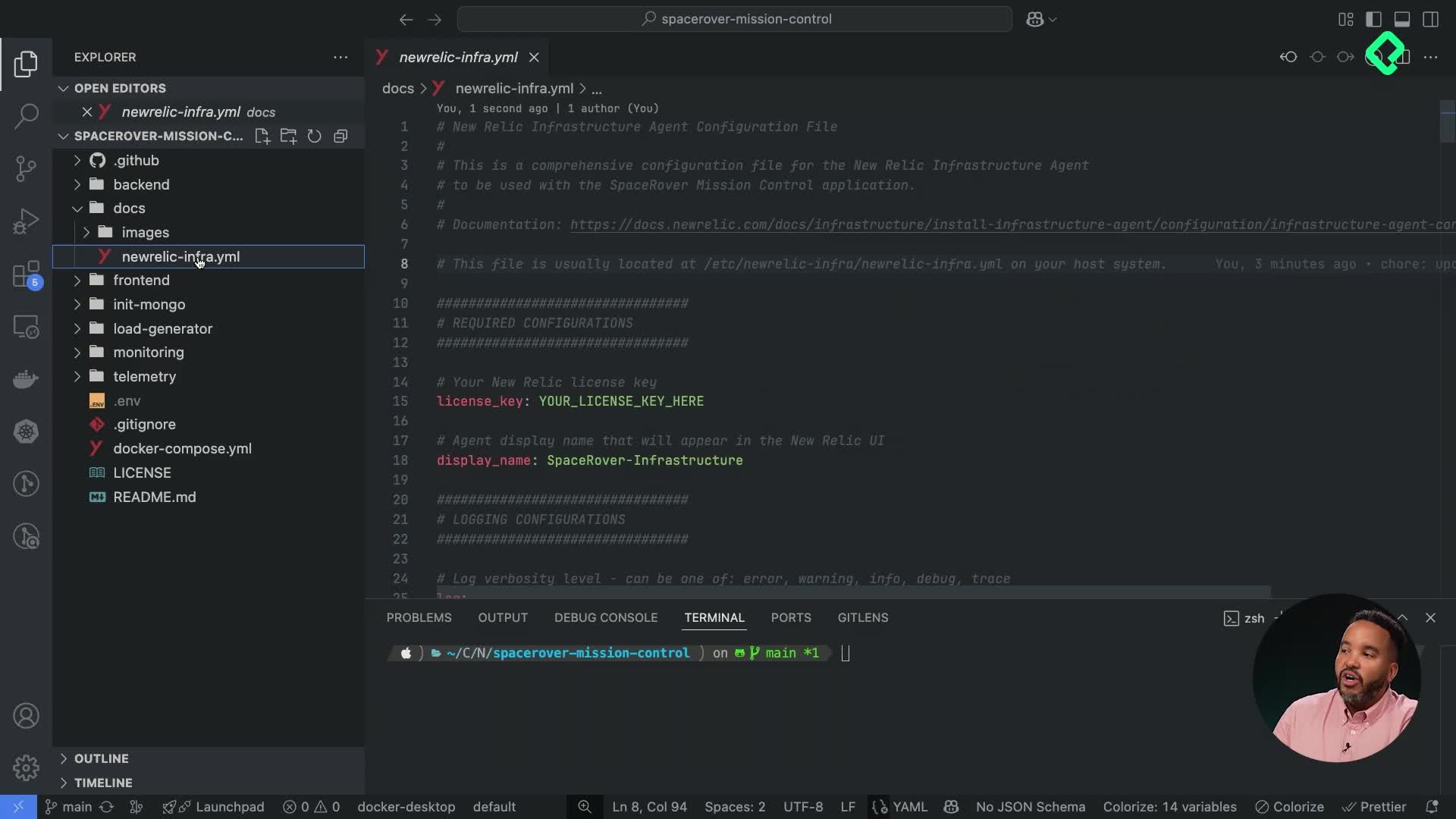
Configurar el agente de infraestructura de New Relic empieza por un solo dato obligatorio: tu license key. Todo lo demás viene con valores predeterminados que reflejan las mejores prácticas de New Relic, pero puedes ajustarlo todo según tu arquitectura. Esta guía recorre las configuraciones más útiles del archivo newrelic-infra.yml para que sepas qué tocar y qué dejar como está.
¿Cómo se configura el agente de infraestructura de New Relic?
Cuando usas la imagen de Docker, no manejas un archivo de configuración tradicional: pasas variables de entorno al contenedor, empezando por la license key y un display name que te permita encontrar el host fácilmente dentro de la plataforma.
Si prefieres más control, puedes proporcionar un archivo newrelic-infra.yml ubicado en /etc/newrelic-infra/ dentro del host. En el repositorio del curso encuentras un ejemplo comentado en el directorio docs que puedes usar como punto de partida.
¿Cuál es la única configuración obligatoria del agente? La license key. Todas las demás opciones tienen valores predeterminados definidos por New Relic, aunque se recomienda añadir un display name para identificar el host.
¿Qué controlan las configuraciones de logging y proxy?
Los logs tienen niveles de severidad y el agente te deja decidir cuánta información enviar. Un buen punto de partida es el nivel info, que cubre errores, advertencias e información general útil para depurar.
- Error logs: algo falló por completo.
- Warning logs: hay funciones obsoletas o mejoras pendientes.
- Info logs: contexto general para debugging.
- Debug y trace logs: detalle profundo para diagnósticos complejos.
Además del nivel, puedes definir la ruta del archivo de logs, su tamaño máximo y la cantidad de archivos rotados (cinco por defecto) para evitar degradar CPU y memoria del servidor. También eliges si envías esos logs a New Relic o los manejas con otra herramienta, y puedes fijar el formato en texto o JSON, siendo JSON la opción recomendada [03:25].
Si tu red usa un proxy, defines la ruta en la sección correspondiente. Si no, lo dejas comentado.
¿Cómo monitorear Docker, procesos e inventario?
Aquí decides qué partes de tu infraestructura observa el agente y con qué frecuencia. La granularidad importa porque afecta tanto la calidad de los datos como el costo en recursos.
Monitoreo de Docker y procesos
Para Docker, habilitas la integración y luego usas listas de inclusión y exclusión para señalar qué contenedores observar. La opción all te permite monitorear todos o ninguno de un solo golpe.
En procesos, activas las métricas y defines:
- La tasa de muestreo, que controla cada cuánto se recolectan datos.
- El número máximo de procesos a monitorear con
max processes. - Listas de inclusión y exclusión para enfocarte solo en lo crítico, como Java, Node, MongoDB y New Relic en este proyecto.
- La opción para recopilar argumentos de procesos si los necesitas.
Configuraciones de inventario
El inventario es la lista de componentes activos en tu arquitectura. El intervalo de recolección se mide en minutos y el valor por defecto son 15 minutos [05:48]. En el ejemplo se eleva a 600 minutos porque el inventario cambia poco.
¿Cuándo conviene reducir el intervalo de inventario? Cuando usas microservicios con autoescalado en Kubernetes o Docker. Un intervalo corto te da un registro preciso de cuántos pods o contenedores se están creando en tiempo real.
Las fuentes posibles incluyen Docker, paquetes del gestor del sistema, procesos, archivos de configuración y sistemas. Puedes ser específico sobre qué archivos rastrear (Helm Charts, configuraciones de Kubernetes) y excluir los sensibles como host files o archivos de contraseñas.
¿Qué métricas, atributos e integraciones puedo ajustar?
Esta capa define la información que llega a New Relic y cómo se etiqueta. Es donde personalizas el comportamiento para que coincida con tu negocio.
Métricas de sistema, red y almacenamiento
Controlas la tasa de muestreo de las muestras del sistema y activas métricas de red, útiles por ejemplo para una empresa de videojuegos con componente multijugador que necesita detectar cuellos de botella. También recopilas métricas de dispositivos de almacenamiento como bases de datos o buckets de S3.
El porcentaje de CPU se calcula en modo escalado (0 a 100% por núcleo) o normalizado entre todos los núcleos.
Atributos personalizados globales
Los atributos personalizados que defines en este archivo se aplican como atributos globales: decoran todas las métricas, logs, eventos y trazas que recolecte el agente. Si necesitas atributos específicos para un servicio, como un checkout de e-commerce, los defines en archivos de configuración por componente, no aquí.
Integraciones y proveedores de nube
Las integraciones viven por defecto en /etc/newrelic-infra/integrations.d/, donde colocas archivos YAML para Aurora, Flex u otras integraciones generadas desde las instalaciones guiadas.
Para AWS, Google Cloud o Azure, las configuraciones del proveedor se activan al vincular tu cuenta. En la página de integraciones de AWS encuentras un botón de autodescubrimiento que instala el agente sin trabajo manual y empieza a monitorear automáticamente.
¿Qué hacen las feature flags y las configuraciones avanzadas?
Las feature flags controlan a qué conjuntos de funciones accede el agente. La integración de Docker es una feature flag, igual que Kubernetes, el reenvío de logs o Prometheus. Activar el reenvío de logs habilita los logs in context, lo que te permite ver desde una instancia EC2 con problemas los logs asociados sin filtrar manualmente entre miles.
Para ingenieros SRE más avanzados existe una sección con cientos de ajustes de bajo nivel: cómo identifica el agente a los hosts, tamaño de cargas útiles, protocolos antiguos, archivos de paquetes, timeouts y reintentos cuando no puede conectarse a New Relic. Para el usuario promedio, los predeterminados bastan, pero es bueno saber que existen.
Empieza con la configuración por defecto, observa cómo se comporta tu infraestructura y ajusta a partir de ahí. ¿Cuál de estas configuraciones te dieron ganas de modificar primero? Cuéntanos en los comentarios.