Observabilidad con New Relic: APM, logs e infraestructura
Contenido del curso
APM avanzado
- 2

Qué es APM y sus señales doradas
04:43 min - 3

Buenas prácticas de configuración en APM
09:58 min - 4

Transacciones y métricas custom en New Relic
17:35 min - 5

Seguimiento de cambios en New Relic con GitHub Actions
16:44 min - 6

Métricas personalizadas y seguimiento de cambios en tableros de New Relic
05:58 min - 7

Métricas personalizadas y dashboards en New Relic
02:06 min
Agente de Infraestructura
- 8

Monitoreo de infraestructura con New Relic
03:09 min - 9

Agente de infraestructura New Relic en Docker
10:25 min - 10
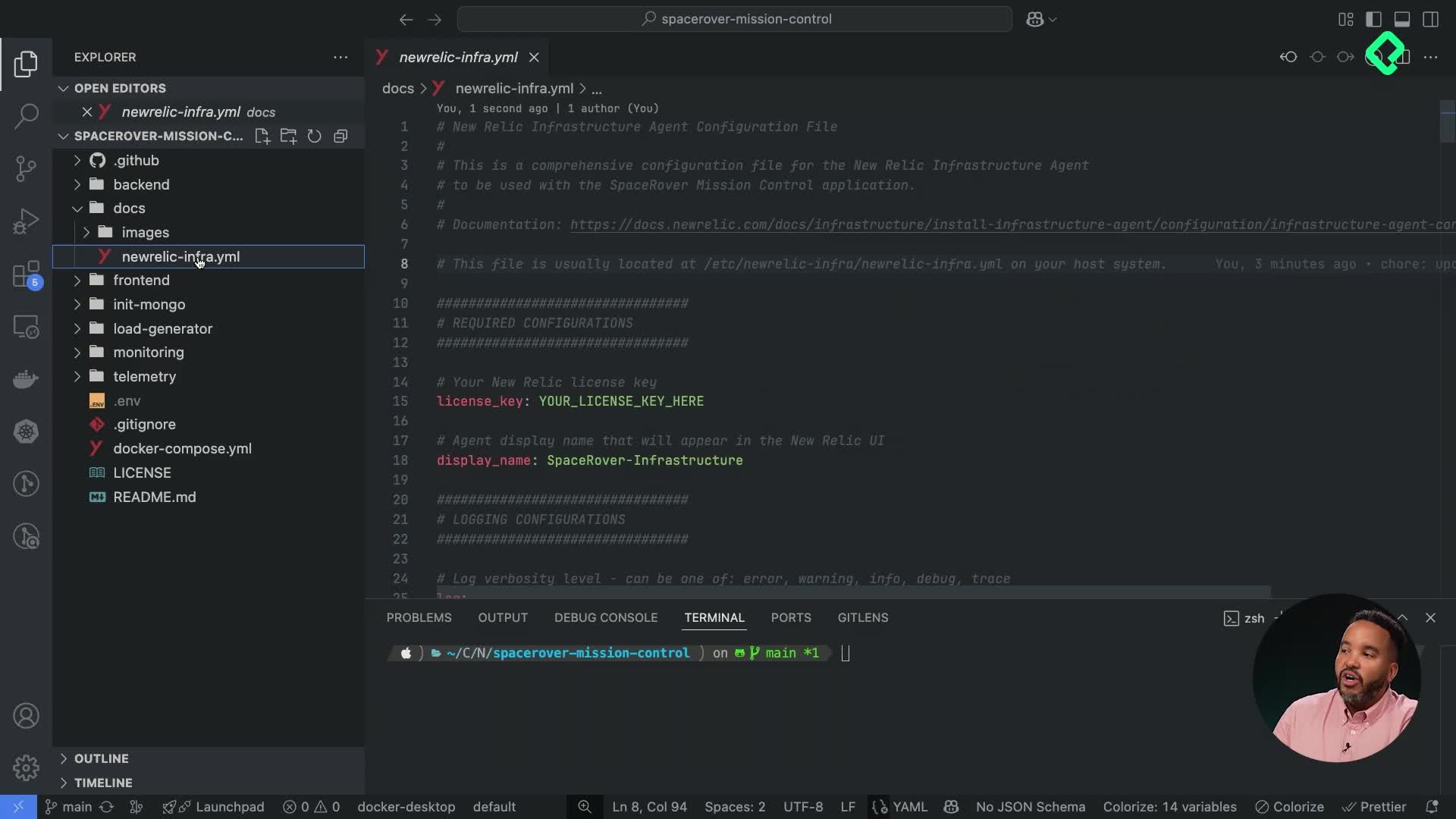
Configuración del agente de infraestructura New Relic
14:28 min - 11

Métricas de infraestructura en New Relic: CPU, memoria y red
09:42 min - 12

Panel de infraestructura en New Relic sin consultas
05:25 min - 13

Configuración de alertas paramétricas para métricas de infraestructura
09:12 min - 14

Configuración de integraciones personalizadas con New Relic Flex
09:26 min - 15

Proyecto final: crea tu integración Flex para New Relic
00:31 min
Registros (Logs)
- 16

Gestión eficiente de registros con New Relic en sistemas distribuidos
02:39 min - 17
Envío de registros a New Relic mediante API directa
07:46 min - 18

Cómo filtrar logs en New Relic con Lucene
09:31 min - 19

Cómo convertir logs no estructurados con Grok
10:45 min - 20

Particiones de datos para gestionar logs de gran volumen
12:24 min - 21

Los registros en contexto conectan datos de APM con rastreo de errores
06:24 min - 22

Proyecto final: dashboard de logs
00:36 min
Optimizar el rendimiento
Observabilidad con New Relic: APM, logs e infraestructura
Resumen
Monitorear sistemas críticos exige el mismo rigor que operar un rover en Marte: cada métrica cuenta y cada anomalía importa. La observabilidad con New Relic te permite ver, comprender y actuar sobre plataformas de comercio electrónico, aplicaciones fintech o sitios de alto tráfico, conectando tres pilares que funcionan como una misión espacial coordinada.
¿Por qué el APM avanzado es el cerebro de tu sistema?
El Application Performance Monitoring avanzado es la inteligencia central que procesa señales en tiempo real y anticipa fallos antes de que lleguen al usuario final.
Cuando configuras un APM con la profundidad adecuada, dejas de reaccionar y empiezas a prevenir. Eso significa optimizar parámetros, definir métricas personalizadas según el comportamiento real de tu aplicación y rastrear cambios al instante para detectar desviaciones mínimas.
Piensa en un e-commerce durante una campaña de descuentos. Si el tráfico se dispara y el APM no está afinado, una latencia de pocos segundos puede traducirse en carritos abandonados y pérdida directa de ingresos. Con un APM bien configurado, ves la curva subir, identificas el cuello de botella y actúas antes de que el usuario lo note.
¿Qué es el APM y para qué sirve? Es una herramienta que monitorea el rendimiento de aplicaciones en tiempo real. Sirve para detectar problemas de latencia, errores y consumo anómalo antes de que impacten al usuario.
¿Cómo aprovechar las métricas personalizadas?
Las métricas personalizadas son el equivalente a sensores específicos en un rover: capturan exactamente lo que tu negocio necesita medir, no solo lo genérico.
- Define indicadores ligados a transacciones críticas, como tiempos de checkout o respuesta de API de pago.
- Rastrea cambios después de cada despliegue para validar que una nueva versión no degrade el rendimiento.
- Conecta esas métricas con alertas tempranas para ganar margen de reacción.
¿Cómo funciona el agente de infraestructura como soporte vital?
El agente de infraestructura es la columna vertebral que mantiene vivos a los demás componentes. Sin energía ni comunicación, ningún rover sobrevive; sin infraestructura observada, ningún sistema escala con seguridad.
Al instalar agentes, construir paneles de control y establecer alertas, creas una red de resiliencia que sostiene la operación día y noche. En sectores como finanzas o salud, este nivel de monitoreo no es un lujo, es la base de la confianza del usuario.
Un panel bien diseñado te muestra de un vistazo el estado de servidores, contenedores y servicios dependientes. Las alertas, configuradas con umbrales realistas, te avisan cuando algo se desvía del comportamiento esperado y te dan tiempo para intervenir.
¿Qué hace un agente de infraestructura? Recolecta datos de servidores, contenedores y procesos en tiempo real. Permite construir paneles, lanzar alertas y mantener la resiliencia de los sistemas que sostienen tu aplicación.
¿Por qué los logs son la caja negra de tu operación?
Los logs registran cada acción y cada anomalía. Son la evidencia que te permite reconstruir lo que pasó, descubrir patrones repetidos y llegar a la causa raíz de un incidente.
En una aplicación fintech, por ejemplo, los logs ayudan a detectar comportamientos inusuales que podrían indicar fraude, errores de lógica o degradación de un servicio externo. En un problema de rendimiento, los logs te llevan al punto exacto donde la transacción falló.
¿Cómo convertir logs en decisiones?
Leer logs sin estrategia es ruido. Convertirlos en decisiones requiere método.
- Centraliza los logs de todos tus servicios en una sola plataforma para correlacionar eventos.
- Filtra por severidad y contexto para enfocarte en lo accionable.
- Cruza logs con métricas de APM e infraestructura para entender el panorama completo.
Con esa práctica, pasas de apagar incendios a tomar decisiones informadas que mejoran la confiabilidad a largo plazo.
¿Cuál es tu próxima misión con New Relic?
La analogía del rover no es solo una imagen, es una forma de pensar la observabilidad. Ahora tienes el cerebro (APM), el soporte vital (infraestructura) y la caja negra (logs) trabajando como un sistema integrado.
Tu siguiente paso es aplicarlo: optimiza el rendimiento de un servicio crítico, mejora la confiabilidad de tu plataforma o reduce el tiempo de resolución de incidentes. ¿Qué sistema vas a empezar a monitorear primero? Cuéntalo en los comentarios.