Introducción al despliegue de modelos en producción
Clase 27 de 28 • Curso Profesional de Redes Neuronales con TensorFlow
Contenido del curso
Manejo y preprocesamiento de datos para redes neuronales
- 3

Carga y Procesamiento de Bases de Datos en Inteligencia Artificial
02:48 min - 4

Carga de Bases de Datos JSON desde GCP en Google Colab
10:25 min - 5

Codificación Base64 y Gestión de Imágenes en Google Colab
12:50 min - 6

Preprocesamiento y limpieza de datos
12:15 min - 7

Keras datasets
10:14 min - 8

Datasets generators
18:36 min - 9

Aprende a buscar bases de datos para deep learning
04:14 min - 10

Cómo distribuir los datos
06:50 min - 11

Crear la red neural, definir capas, compilar, entrenar, evaluar y predicciones
14:35 min
Optimización de precisión de modelos
- 12

Métodos de regularización: overfitting y underfitting
11:16 min - 13

Recomendaciones prácticas para ajustar un modelo
12:00 min - 14

Métricas para medir la eficiencia de un modelo: callback
08:18 min - 15

Monitoreo del entrenamiento en tiempo real: early stopping y patience
07:04 min - 16

KerasTuner: construyendo el modelo
13:54 min - 17

KerasTuner: buscando la mejor configuración para tu modelo
08:45 min
Almacenamiento y carga de modelos
Fundamentos de aprendizaje por transferencia
Resultados de entrenamiento
Resumen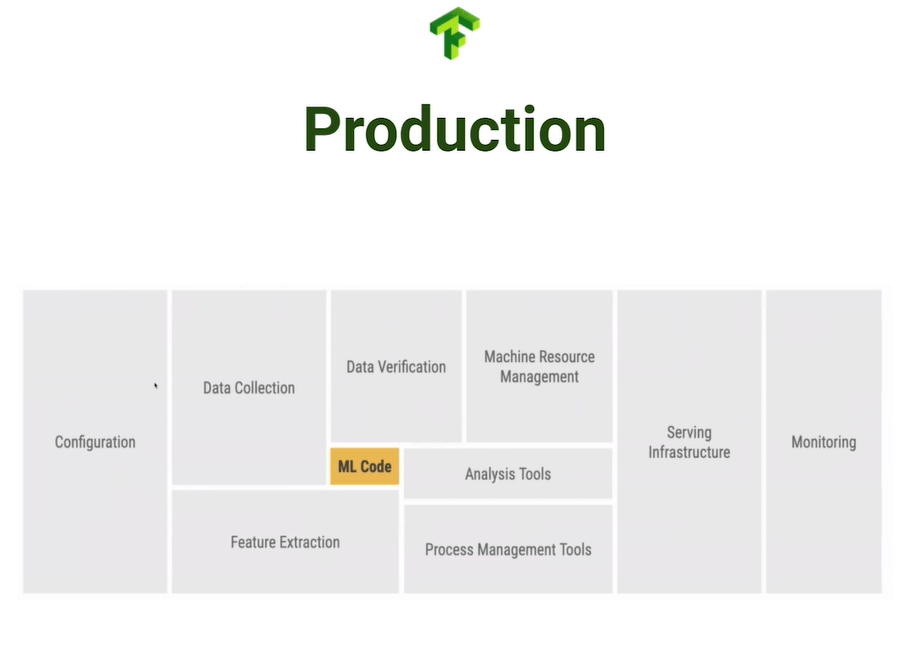
La generación de código para Machine Learning es una parte vasta y en la que se puede profundizar increíblemente, sin embargo, en el gran esquema de las cosas implica una pequeña parte del ciclo de vida entero de un proyecto.
En las siguientes entregas de esta saga se interiorizará sobre el resto de etapas, donde aprenderás a profesionalizarlas.
Ya tienes tus códigos, tus configuraciones y pesos, pero, ¿Cómo los haces accesibles al usuario final?
Ejemplos de producción
Puedes desplegar tus modelos en diferentes dispositivos según tu necesidad.
Si tu proyecto va a ser de consumo masificado, entonces la opción natural será desplegarlo en la nube, donde Google Cloud, Azure, AWS u Oracle Cloud podrán ayudarte. Esta ventaja es especialmente útil si debes escalar tu modelo a mayores capacidades sin necesidad de adquirir un equipo propio.
Si necesitas hacer inferencias en vivo entonces podrías optar por equipo IoT, donde dispositivos como la Raspberry Pi o el Jatson Nanon te ofrecerán una capacidad de cómputo decente para tareas en tiempo real.
Si tienes los recursos necesarios o el proyecto no es tan robusto, puedes correr tus modelos de manera local, donde tus equipos se encargarán de las inferencias.
Un caso final (y una extensión a los últimos 2 casos) sería el de usar un USB Accelerator, hardware con alta capacidad de cómputo que procesa las inferencias con alta facilidad.
Puedes concentrar los recursos de predicción sobre este hardware y dejar descansar al resto del equipo.
Contribución creada por Sebastián Franco Gómez.