
Hola, en este post aprenderemos inglés con python utilizando las palabras más comunes y servira como bienvenida a lo que viene para la ruta.
import = Importar
from = desde
naaah es broma.
Estaba en el Curso de Estrategias para Aprender Inglés Online. Para formar vocabulario, la profesora recomienda leer noticias, blogs u otros y formar listas de vocabulario. Como buenos programadores tenemos el superpoder de crear así que manos a la obra.
Crearemos un scraper para obtener, desde un texto, las palabras más frecuentes traducidas y así crear una lista de vocabulario de nuestra lectura diaria. Para el ejemplo usaremos un post de platzi escrito por Miguel Torres un amigo de la comunidad (Recomiendo leer).
El primer paso es importar las librerías que usaremos
#Para extraer la inforacion
import requests
from bs4 import BeautifulSoup as bs
#Para trabajar con el texto
import nltk
import re
#Para la presentacion
from wordcloud import WordCloud
import matplotlib.pyplot as plt
import pandas as pd
#Para traducir
import goslate
Luego de importar toca hacer la extracción del post. Si quieres aprender más sobre este paso te recomiendo tomar los siguientes cursos:
-
Curso de Fundamentos de Web Scraping con Python y Xpath
-
Curso de Web Scraping: Extracción de Datos en la Web
-
Curso de Ingeniería de Datos con Python
url ="https://platzi.com/tutoriales/1841-probabilistica/6623-conoce-lo-esencial-para-aprender-machine-learning-2/"
response = requests.get(url) # ahcemos una peticion a la pagina
soup = bs(response.text, "html.parser")
#titulos = soup.find("div", attrs={"class":"MainContribution-text"}).find_all("h2")
#titulos = [titulo.text for titulo in titulos]
parrafos =soup.find("div", attrs={"class":"MainContribution-text"}).find_all("p") #nos genera una lista con los parrafos
Ya tenemos el texto, pero este está “sucio”, palabras en mayúsculas, minúsculas, con signos de puntuación. Toca limpiar, si quieres profundizar te recomiendo tomar:
- Curso de Fundamentos de Procesamiento de Lenguaje Natural con Python y NLTK
stopwd = nltk.corpus.stopwords.words("spanish") # Nos ayudara a eliminar los stopwords
pattern = r'[.,¿?!¡:]' #expresion que usaremos para borrar algunos signos de puntuacion
parrafos =[parrafo.text for parrafo in parrafos] #obtenemos el texto de cada parrafo de la lista
parrafos =[palabra for lista in parrafos for palabra in lista.split(" ") ]# creaos una lista donde cada elemento es una palabra
parrafos =[re.sub( pattern,"",palabra.strip()) for palabra in parrafos]# Usamos para quitar signos de puntuacion
parrafos =[palabra for palabra in parrafos if len(palabra) >4] #eliminamos aquellas palabras con longitud menor a 4
parrafos =[palabra for palabra in parrafos if palabra.lower() not in stopwd]#Si es que nos queda alguna palabra que no aporta
# en nada la eliminamos con esto
vocabulario_parrafos = sorted(set(parrafos)) #creamos una lista de vocabulario donde ninguna palabra se repite
Ya tenemos nuestro texto limpio, ahora toca procesarlo y obtener algo de información.
fdist =nltk.FreqDist(parrafos) #Calculamos la frecuencia con la que una palabra sale en el texto, devuelve un diccionario
fdist_comunes = fdist.most_common(30) # obtendremos las 30 palabras que mas se repiten
palabras = [palabra[0] for palabra in fdist_comunes] #creamos una lista con las palabras mas repetidas
gs = goslate.Goslate() #Esto lo usaremos para hacer la traduccion
traduccion = list(gs.translate(palabras, 'en')) # traducimos las palabras mas frequentes
Si es que estás en la Escuela de Data Science sabrás que una parte importante es la visualización.
Ya con nuestro texto limpio y procesado usaremos este código para crear una nube de palabras,
las más frecuentes,en español.
nube = " ".join(parrafos)
wordcloud = WordCloud(background_color='white').generate(nube)
plt.imshow(wordcloud)
y este lo usaremos para el inglés.
cloud = " ".join(traduccion)
wordcloud = WordCloud(background_color='white').generate(cloud)
plt.imshow(wordcloud)
El resultado es el siguiente:

Para nuestra lista de palabras más frecuentes usaremos pandas para crear una tabla que nos permita ver de una forma amigable su traducción.
palabras_traducidas = {}
for i in range(len(traduccion)):
palabras_traducidas[palabras[i]]=traduccion [i]
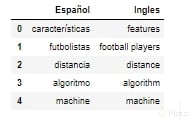
df = pd.DataFrame(list(palabras_traducidas.items()), columns = ["Español", "Ingles"])
El resultado es el siguiente, son solo las primeras 5 palabras de nuestra lista:
Ya podemos aprender el vocabulario necesario en nuestro campo de interés.
¿y que paso con nuestra lista de vocabulario?
Te reto a tomar los cursos que mencione y a crear tu propia lista de vocabulario traducida de tus lecturas más frecuentes.
Esta es una buena forma de aprender python, inglés y nunca parar de aprender.
Curso de Ingeniería de Datos con Python
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


