
La regresión lineal es un algoritmo de aprendizaje supervisado que se utiliza en Machine Learning y en estadística. En su versión más sencilla, lo que haremos es “dibujar una recta” que nos indicará la tendencia de un conjunto de datos continuos (si fueran discretos, utilizaríamos Regresión Logística).
En estadísticas, regresión lineal es una aproximación para modelar la relación entre una variable escalar dependiente “y” y una o mas variables explicativas nombradas con “X”.
Recordemos rápidamente la fórmula de la recta:
Y = mX + b
Donde Y es el resultado, X es la variable, m la pendiente (o coeficiente) de la recta y b la constante o también conocida como el “punto de corte con el eje Y” en la gráfica (cuando X=0)
¿Cómo funciona el algoritmo de regresión lineal en Machine Learning?
Recordemos que los algoritmos de Machine Learning Supervisados, aprenden por sí mismos y -en este caso- a obtener automáticamente esa “recta” que buscamos con la tendencia de predicción. Para hacerlo se mide el error con respecto a los puntos de entrada y el valor “Y” de salida real. El algoritmo deberá minimizar el coste de una función de error cuadrático y esos coeficientes corresponderán con la recta óptima. Hay diversos métodos para conseguir minimizar el coste. Lo más común es utilizar una versión vectorial y la llamada Ecuación Normal que nos dará un resultado directo.
Hagamos un Ejercicio Práctico
En este ejemplo cargaremos un archivo .csv de entrada obtenido por webscraping que contiene diversas URLs a artículos sobre Machine Learning de algunos sitios muy importantes como Techcrunch o KDnuggets y como características de entrada -las columnas- tendremos:
-
Title: Titulo del Artículo
-
url: ruta al artículo
-
Word count: la cantidad de palabras del artículo,
- <h1>of Links: los enlaces externos que contiene,</h1>
- <h1>of comments: cantidad de comentarios,</h1>
- <h1>Images video: suma de imágenes (o videos),</h1>
-
Elapsed days: la cantidad de días transcurridos (al momento de crear el archivo)
- <h1>Shares: nuestra columna de salida que será la “cantidad de veces que se compartió el artículo”</h1>
A partir de las características de un artículo de machine learning intentaremos predecir, cuantas veces será compartido en Redes Sociales.
Haremos una primer predicción de regresión lineal simple -con una sola variable predictora- para poder graficar en 2 dimensiones (ejes X e Y) y luego un ejemplo de regresión Lineal Múltiple, en la que utilizaremos 3 dimensiones (X,Y,Z) y predicciones.
NOTA: el archivo .csv contiene mitad de datos reales, y otra mitad los generé de manera aleatoria, por lo que las predicciones que obtendremos no serán reales. Intentaré en el futuro hacer webscrapping de los enlaces que me faltaban y reemplazar los resultados por valores reales.
Requerimientos para hacer el Ejercicio
Para realizar este ejercicio, crearemos una Jupyter notebook con código Python y la librería SkLearn muy utilizada en Data Science. Recomendamos utilizar la suite de Anaconda…
Predecir cuántas veces será compartido un artículo de Machine Learning.
Regresión lineal simple en Python (con 1 variable)
Comencemos por importar las librerías que utilizaremos:
# Imports necesarios
import numpy as np
import pandas as pd
import seaborn as sb
import matplotlib.pyplot as plt
%matplotlib inline
from mpl_toolkits.mplot3d import Axes3D
from matplotlib import cm
plt.rcParams['figure.figsize'] = (16, 9)
plt.style.use('ggplot')
from sklearn import linear_model
from sklearn.metrics import mean_squared_error, r2_score
Leemos el archivo csv y lo cargamos como un dataset de Pandas. Y vemos su tamaño
#cargamos los datos de entrada
data = pd.read_csv("./articulos_ml.csv")
#veamos cuantas dimensiones y registros contiene
data.shape
Nos devuelve (161,8)
Veamos esas primeras filas:
#son 161 registros con 8 columnas. Veamos los primeros registros
data.head()

Se ven algunos campos con valores NaN (nulos) por ejemplo algunas urls o en comentarios.
Veamos algunas estadísticas básicas de nuestros datos de entrada:
# Ahora veamos algunas estadísticas de nuestros datos
data.describe()

Aqui vemos que la media de palabras en los artículos es de 1808. El artículo más corto tiene 250 palabras y el más extenso 8401. Intentaremos ver con nuestra relación lineal, si hay una correlación entre la cantidad de palabras del texto y la cantidad de Shares obtenidos.
Hacemos una visualización en general de los datos de entrada:
# Visualizamos rápidamente las caraterísticas de entrada
data.drop(['Title','url', 'Elapsed days'],1).hist()
plt.show()
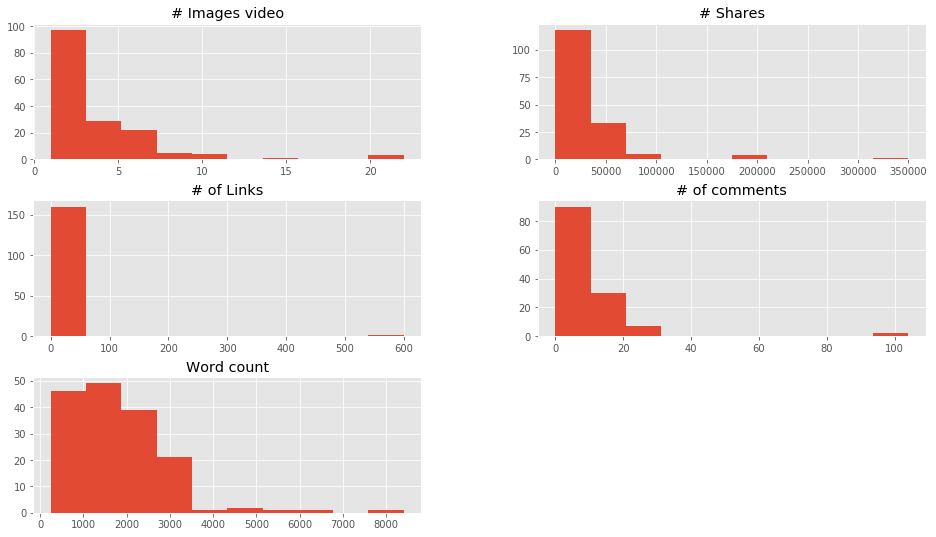
En estas gráficas vemos entre qué valores se concentran la mayoría de registros.
Vamos a filtrar los datos de cantidad de palabras para quedarnos con los registros con menos de 3500 palabras y también con los que tengan Cantidad de compartidos menos a 80.000. Lo gratificaremos pintando en azul los puntos con menos de 1808 palabras (la media) y en naranja los que tengan más.
# Vamos a RECORTAR los datos en la zona donde se concentran más los puntos
# esto es en el eje X: entre 0 y 3.500
# y en el eje Y: entre 0 y 80.000
filtered_data = data[(data['Word count'] <= 3500) & (data['# Shares'] <= 80000)]
colores=['orange','blue']
tamanios=[30,60]
f1 = filtered_data['Word count'].values
f2 = filtered_data['# Shares'].values
# Vamos a pintar en colores los puntos por debajo y por encima de la media de Cantidad de Palabras
asignar=[]
for index, row in filtered_data.iterrows():
if(row['Word count']>1808):
asignar.append(colores[0])
else:
asignar.append(colores[1])
plt.scatter(f1, f2, c=asignar, s=tamanios[0])
plt.show()

Regresión Lineal con Python y SKLearn
Vamos a crear nuestros datos de entrada por el momento sólo Word Count y como etiquetas los # Shares. Creamos el objeto LinearRegression y lo hacemos “encajar” (entrenar) con el método fit(). Finalmente imprimimos los coeficientes y puntajes obtenidos.
# Asignamos nuestra variable de entrada X para entrenamiento y las etiquetas Y.
dataX =filtered_data[["Word count"]]
X_train = np.array(dataX)
y_train = filtered_data['# Shares'].values
# Creamos el objeto de Regresión Linear
regr = linear_model.LinearRegression()
# Entrenamos nuestro modelo
regr.fit(X_train, y_train)
# Hacemos las predicciones que en definitiva una línea (en este caso, al ser 2D)
y_pred = regr.predict(X_train)
# Veamos los coeficienetes obtenidos, En nuestro caso, serán la Tangente
print('Coefficients: \n', regr.coef_)
# Este es el valor donde corta el eje Y (en X=0)
print('Independent term: \n', regr.intercept_)
# Error Cuadrado Medio
print("Mean squared error: %.2f" % mean_squared_error(y_train, y_pred))
# Puntaje de Varianza. El mejor puntaje es un 1.0
print('Variance score: %.2f' % r2_score(y_train, y_pred))
De la ecuación de la recta y = mX + b nuestra pendiente “m” es el coeficiente 5,69 y el término independiente “b” es 11200. Tenemos un Error Cuadrático medio enorme… por lo que en realidad este modelo no será muy bueno 😉 Pero estamos aprendiendo a usarlo, que es lo que nos importa ahora 🙂 Esto también se ve reflejado en el puntaje de Varianza que debería ser cercano a 1.0.

Predicción en regresión lineal simple
Vamos a intentar probar nuestro algoritmo, suponiendo que quisiéramos predecir cuántos “compartir” obtendrá un articulo sobre ML de 2000 palabras
#Vamos a comprobar:
# Quiero predecir cuántos "Shares" voy a obtener por un artículo con 2.000 palabras,
# según nuestro modelo, hacemos:
y_Dosmil = regr.predict([[2000]])
print(int(y_Dosmil))
Nos devuelve una predicción de 22595 “Shares” para un artículo de 2000 palabras
Curso de Introducción a Machine Learning 2019
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


