
Introducción.💚
Al fin hemos llegado al código, sé que estabas ansioso de llegar aquí, permíteme dar una breve introducción. Pandas es una extensión de Numpy, una herramienta que debes dominar si quieres adentrarte en la ciencia de datos con Python. Usamos Pandas para el manejo y análisis de datos pero su alcance va más allá.
⠀⠀⠀⠀⠀⠀⠀⠀⠀
En este ejercicio usaremos datos de consumo energético e intentaremos aplicar conceptos que hemos estudiado. Recuerda que es solo un trabajo introductorio y a medida que vayamos avanzando en los tutoriales iremos aumentando la dificultad y aprendiendo cosas más entretenidas.
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Yo trabajaré en Jupyter notebooks, también puedes usar google colab.
⠀⠀⠀⠀⠀⠀⠀⠀⠀
¿Qué necesito?😄👀
- Conocimientos básicos de Python.
- Los datos.
- Mucho ánimo.
Conociendo el conjunto de datos.🔎
Esto en ciencia de datos se llama EDA: Exploratory Data Analysis. Pero aún no entraremos en este campo.
⠀⠀⠀⠀⠀⠀⠀⠀⠀
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Lo primero es importar Pandas y Numpy, estas dos librerías junto a matplolib forman tu caja de herramientas. Importemos las librerías;
import pandas as pd
import numpy as np
Luego cargamos los datos.
df = pd.read_csv("Datos proyecto 1.csv", sep=";")
df #esta linea sirve para mostrar los datos
Recuerda que parte importante del trabajo es reconocer el tipo de variable y pandas tiene una función especial para esto.
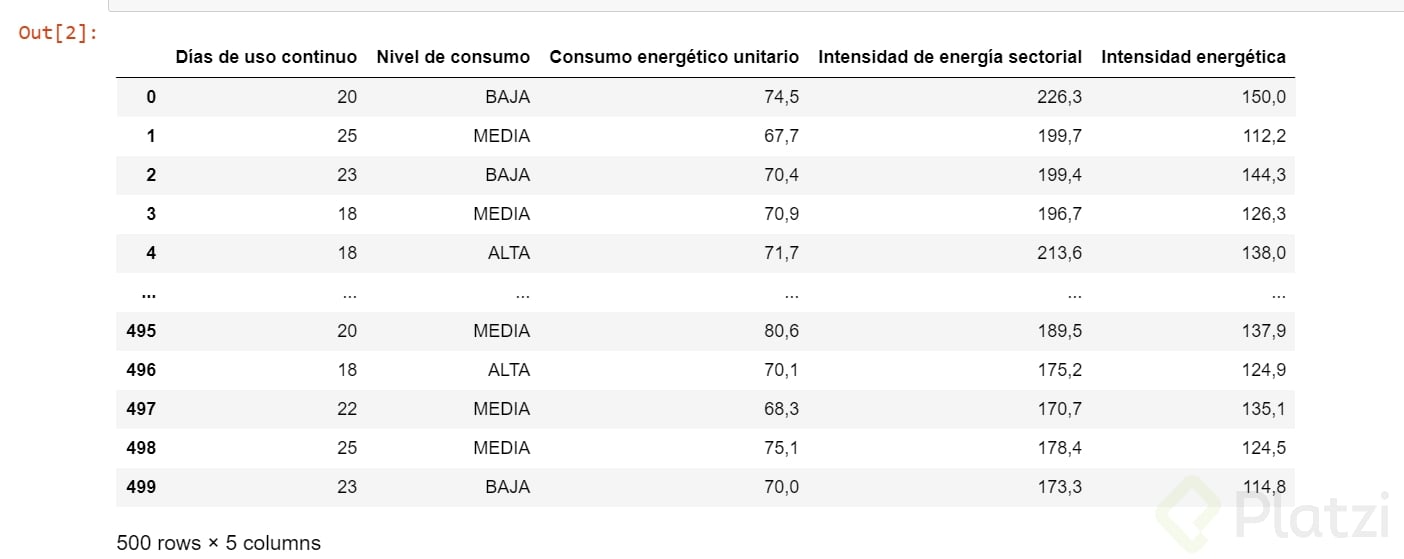
df.dtypes

⠀⠀⠀⠀⠀⠀⠀⠀⠀
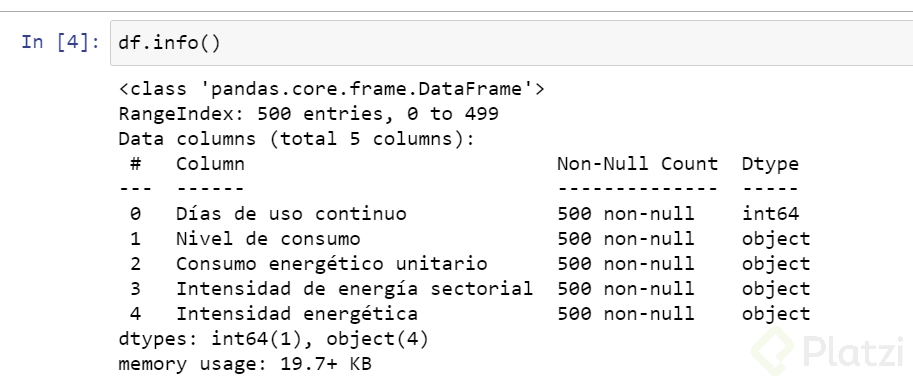
Tenemos datos object 😨 esto puede ser porque tenemos datos faltantes u otro error.
df.info() #Podemosverenlafotoquenohaydatosfaltantes.
df.convert_dtypes().dtypes

Tenemos un error, en los datos tenemos números decimales con comas en vez de puntos.
cambiar_coma_punto = lambda x: (x.replace(",","."))
df["Consumo energético unitario"] = df["Consumo energético unitario"].apply(cambiar_coma_punto)
df["Intensidad de energía sectorial"] = df["Intensidad de energía sectorial"].apply(cambiar_coma_punto)
df["Intensidad energética"] = df["Intensidad energética"].apply(cambiar_coma_punto)
#convertimos los datos a número
df["Consumo energético unitario"] = pd.to_numeric(df["Consumo energético unitario"], errors='coerce')
df["Intensidad de energía sectorial"] = pd.to_numeric(df["Intensidad de energía sectorial"], errors='coerce')
df["Intensidad energética"] = pd.to_numeric(df["Intensidad energética"], errors='coerce')
df.dtypes

Hay formas más eficiente de hacer pero vamos paso a paso. Como te comentaba en los tutoriales anteriores este es un paso importante ya que, de esto depende que métodos de análisis usaremos.
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Población (ϑ): Hogares Chilenos consumidores de energía eléctrica.
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Muestra (s): 500 Hogares chilenos que consumen energía eléctrica ubicados en el norte del país.
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Días de uso continuo (X1): Corresponde al número de días los cuales se ocupó la energía eléctrica. (Variable cuantitativa discreta.)
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Nivel de consumo (X2): Se refiere al nivel en el cual se consume la energía eléctrica, donde existen tres niveles: bajo, medio y alto. (Variable cualitativa ordinal.)
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Consumo energético unitario (X3): Corresponde a la cantidad de energía medida en Watts consumida por el hogar en observación. (Variable cuantitativa continua)
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Intensidad de energía sectorial (X4): Corresponde a la intensidad de energía consumida en el sector el cual está ubicado el hogar en estudio. (Variable cuantitativa continua.)
⠀⠀⠀⠀⠀⠀⠀⠀⠀
Intensidad energética (X5) : es un indicador de la eficiencia energética de una economía. Se calcula como la relación entre el consumo energético (E) y el producto interno bruto (PIB) de un país. Se interpreta como “se necesitan x unidades de energía para producir 1 unidad de riqueza.” (Variable cuantitativa continua.)
- (X5) elevada: indica un coste alto en la “conversión” de energía en riqueza). Se consume mucha energía obteniendo un PIB bajo
- (X5) baja: indica un coste bajo. Se consume poca energía, obteniendo un PIB alto.
Daré por finalizada esta parte, pero no sin antes decirte que el EDA es todo un arte propio, mucho más entretenido y amplio de lo que hicimos aquí. Me comprometo a hacer un tutorial intermedio de EDA explicando muchas más facetas de esta etapa.
Tablas de frecuencia
Crear una tabla de frecuencia se vuelve un trabajo sencillo cuanto tenemos a pandas de nuestro lado. Analicemos una de las variables.
df["Días de uso continuo"].describe()
Tamaño_muestra=df.shape[0] #descubre que hace df.shape...
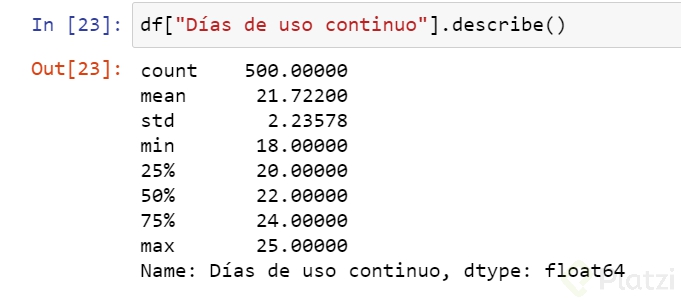
De aquí podemos obtener bastante información, pasemos a hacer la tabla de esta variable.
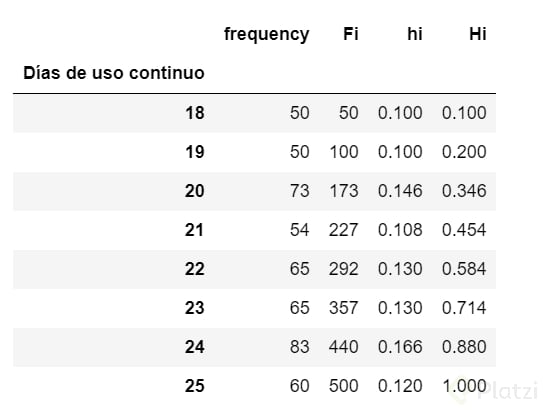
Tabla_Días_uso_continuo =df.groupby("Días de uso continuo").agg(frequency=("Días de uso continuo", "count"))
Tabla_Días_uso_continuo["Fi"]=Tabla_Días_uso_continuo["frequency"].cumsum()
Tabla_Días_uso_continuo["hi"]=(Tabla_Días_uso_continuo["frequency"]/Tamaño_muestra)
Tabla_Días_uso_continuo["Hi"]=Tabla_Días_uso_continuo["hi"].cumsum()
Tabla_Días_uso_continuo
❌Grafiquemos
Tabla_Días_uso_continuo["frequency"].plot()
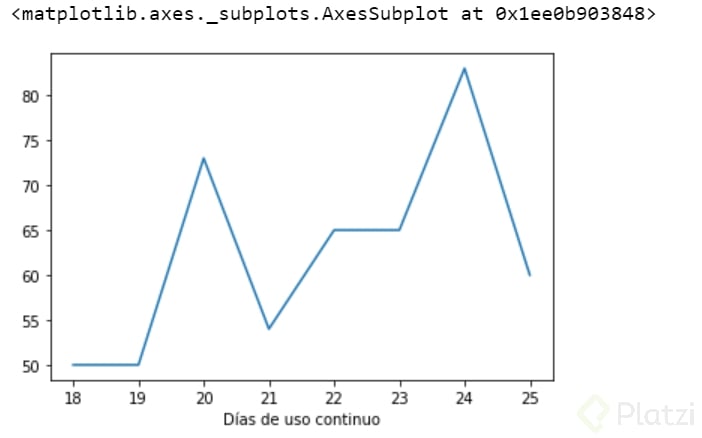
Como puedes ver usamos un gráfico erróneo para representar nuestra variable, ahora si usemos el correcto.
Tabla_Días_uso_continuo["frequency"].plot(kind="bar")
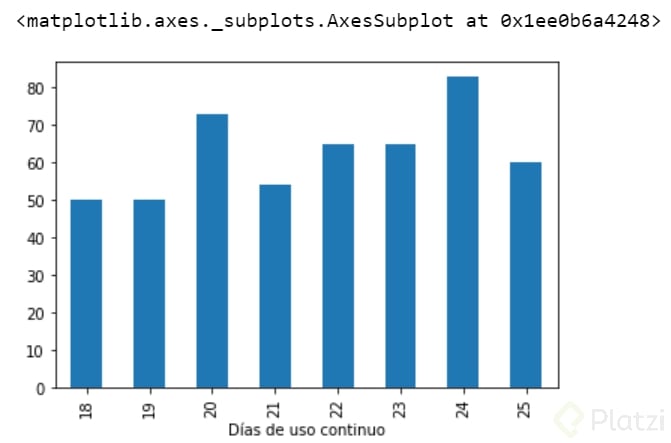
También podemos observar el conjunto en su conjunto
df.hist()
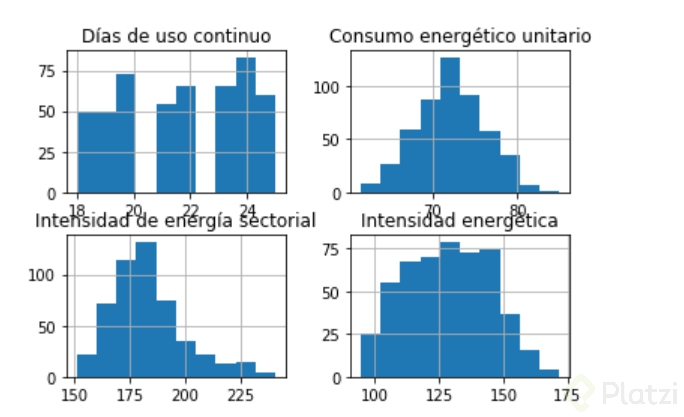
¿Puedes observar que ciertas variables tiene una forma en particular? De esto y correlación entre variables hablaremos en futuros post, no pierdas tu trabajo.
Te toca hacer el resto de variables y pues claro presentar una conclusión ¿Qué información podemos sacar al respecto?
Si quieres mejorar tu habilidad con Pandas debes tomar el Curso de Manipulación y Análisis de Datos con Pandas y Python
Curso de Estadística Computacional con Python
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


