
El procesamiento del lenguaje Natural (NLP por sus siglas en inglés) se define como el estudio que trata de entender, analizar e interpretar el significado del lenguaje humano con una computadora, siendo utilizado en la ciencia de datos, inteligencia artificial y la lingüística. Su idea principal es percibir de un conjunto de palabras la intensión de su creador.
Las aplicaciones que posee el NLP lo utilizas seguido en varias de las actividades del día a día, entre ellas se encuentran:
-Traducciones: es el más utilizado debido a que se puede entender en un corto periodo de tiempo un texto escrito en otro idioma.
- Resumen automático: cuya idea es reducir la versión de un texto creado por extracción o abstracción.
- Clasificación de texto: útil para asignar el etiquetado y trabajar con modelos supervisados.
- Chatbots: son sistemas capaces de tener una conversación coherente con una persona acerca de un tema específico.
- Análisis de sentimientos: permite identificar información subjetiva en textos como juicios u opiniones usado comúnmente por compañías y famosos que quieren conocer su reputación en las redes sociales.
Pero ¿Qué debemos hacer para aplicar el análisis de sentimiento? Sencillamente puedes seguir una serie de pasos que te ayudarán a conseguir esta meta. En este tutorial se utilizará Jupyter Notebook para ejecutar cada uno de los fragmentos de código. Puedes aprender más de este programa en los cursos que te ofrece la carrera de ciencia de datos de Platzi.
Paso 1: Extracción:
El primero paso es extraer la data que quieres analizar. Utiliza las librerías de tweepy, que da un acceso a la API de Twitter, y pandas para el manejo de las estructuras de datos. Comienza importando tweepy y obtén el OAuthHandler de la siguiente manera:

Para tener acceso a la API se debe crear una cuenta de desarrollador en Twitter la cual proporcionará unas credenciales que usarás en el siguiente fragmento de código, y crearás el acceso a la API con ellas:

Nota: twitterCredentials es un archivo que contiene las credenciales que me fueron entregadas de la cuenta de Twitter, por tal motivo solo debes de reemplazar el valor de esas variables por las credenciales que te fueron asignadas.
Para guardar todos los datos que quieres recolectar se utilizará un CSV. Además, le realizarás una pequeña limpieza al texto recolectado, en este caso solo eliminarás los emojis que contenga. Así que importa las librerías csv y emoji, y utiliza el método user_timeline de tweepy que contiene una serie de parámetros para recolectar los tweets a examinar, en este caso se tiene el nombre de la cuenta y la cantidad de tweets a extraer (estas secciones se encuentran enmarcadas en color rojo).
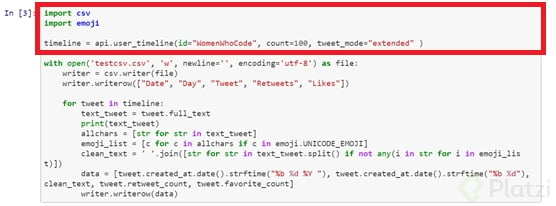
Luego crea el archivo CSV y configura una cabecera de referencia para el manejo de los datos.
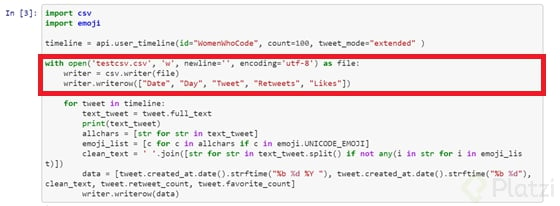
Seguidamente hay un ciclo donde se hace el llamado de cada uno de los tweets a los cuales se van limpiando de los emojis. Esto se realiza concatenando el texto y haciendo una comparación con el unicode de cada emoji. Al momento de encontrarlo solo lo reemplaza con un espacio en blanco. Por último, se crea un array para ordenar la estructura de los datos a guardar y se escribe en el CSV.
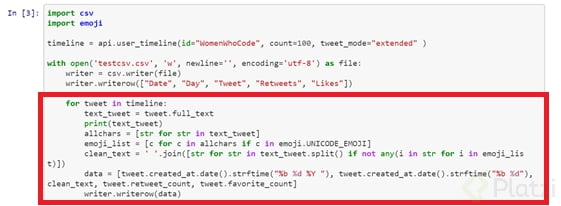
Este es un ejemplo de los tweets recolectados con el fragmento de código anterior:
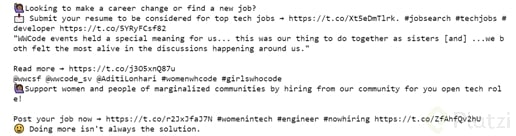
Ahora usa pandas para manejar todos los datos almacenados como un dataframe. Recuerda colocar el nombre del archivo entre comillas y con la extensión correspondiente.
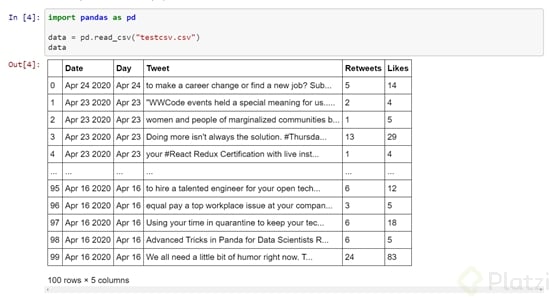
Como puedes ver, la cabecera agregada anteriormente te ayudará de referencia en este conjunto de datos.
Otro método que puedes utilizar para extraer información de Twitter es Twitter Archiver, que es una extensión de las hojas de cálculo de drive. También se puede hacer la extracción de los datos en otras redes sociales como Facebook con la librería de python Facebook Scrapper.
Si quieres aprender a hacer una extracción de datos en la web con Python, te invito a que veas el curso de Web Scraping: Extracción de Datos en la Web con el profesor Martín Sokolowicz.
Paso 2: Procesamiento:
El siguiente paso es el procesamiento de los datos. Aquí utilizarás la librería de python TextBlob que es el encargado de tratar y estimar el valor de sentimiento de cada tweet devolviendo una tupla con 2 valores: la polaridad que va en un rango de -1 a 1, donde 1 significa que el sentimiento es positivo y -1 que el sentimiento valorado en ese tweet es negativo; y la subjetividad que hace referencia al juicio u opinión que contiene ese tweet y va desde los rangos de 0 a 1.
En un nuevo slot de Jupyter Notebook importa la librería textblob y crea un array que te ayudará a almacenar el valor del sentimiento de cada tweet:

Dentro de un ciclo for recorre todos los tweets e imprime el resultado:

Como puedes ver, tienes el texto del comentario seguido de la tupla que contiene los valores de la polaridad y la subjetividad. Sin embargo, mostrar los datos de esta manera no es la forma más adecuada, por este motivo seguimos al siguiente paso.

Paso 3: Despliegue:
Para mostrar los datos, se necesita de la ayuda de las librerías matplolib, que posee una gran variedad de figuras para hacer un gráfico de los resultados, y wordcloud que como su nombre lo indica creará una nube de palabras con los textos suministrados.
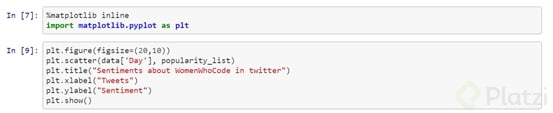
Con matplotlib realiza la configuración de los parámetros deseados. En este caso se configura el tamaño del gráfico, las etiquetas de los ejes y los datos a cruzar que pertenecen al día en qué se publicó el tweet contra el resultado del sentimiento obtenido en el paso anterior de la siguiente manera:
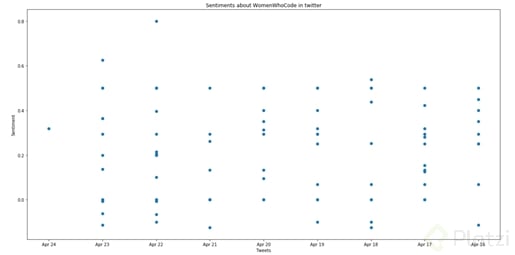
El resultado de tu gráfica se parecerá a la del ejemplo siguiente:
Por otra parte, importa la librería wordcloud y configura los parámetros requeridos de color de fondo, tamaño máximo de fuente, etiquetas y el texto a mostrar. En este caso solo se utilizará el texto de uno de los tweets de la siguiente manera:
Wordcloud principalmente se basa en la frecuencia de palabras que se han utilizado figurándolo en su tamaño, es decir, a mayor tamaño mayor cantidad de veces se repite la palabra en esa frase.

Ahora ¿cuáles serían los casos de uso del análisis de sentimiento? Realmente abarca muchas cosas como el monitoreo de marca, la detección y priorización de los servicios de clientes, análisis de productos, entre otras. Si quieres conocer más acerca del análisis de sentimiento y otras aplicaciones del NLP, te recomiendo el curso de Fundamentos de Procesamiento de Lenguaje Natural con Python y NLTK con el profesor Francisco Camacho y nunca pares de aprender.
Curso de Fundamentos de Procesamiento de Lenguaje Natural con Python y NLTK
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


