Escuela de Data Science
Rutas (7)
Fundamentos de Data Science y AI
63 horas de contenidoCurso de Introducción a la Inteligencia ArtificialCurso Básico de Computadores e InformáticaCurso de Introducción a la Terminal y Línea de ComandosCurso de Fundamentos de Ingeniería de SoftwareCurso de Fundamentos de MatemáticasCurso de Lenguaje y Notación MatemáticaCurso Básico de Cálculo Diferencial para Data Science e Inteligencia ArtificialCurso de Funciones Matemáticas para Data Science e Inteligencia ArtificialCurso de Estadística y ProbabilidadCurso de Estadística DescriptivaCurso de Matemáticas para Data Science: Estadística DescriptivaCurso de Matemáticas para Data Science: ProbabilidadCurso de Estadística Inferencial para Data Science e Inteligencia ArtificialCurso de Ciencia de Datos para Análisis de NegocioCurso de Git y GitHubCurso de Python para Ciencia de DatosCurso de Entornos Virtuales con Anaconda y JupyterCurso de Fundamentos de Álgebra Lineal con PythonCurso de Herramientas de Inteligencia Artificial para Equipos de DatosCurso de Ética y Manejo de Datos para Data Science e Inteligencia ArtificialCurso de Fundamentos de Bases de Datos y SQLAnálisis y Visualización de Datos
51 horas de contenidoCurso de Excel BásicoCurso de Excel IntermedioCurso de Configuración Profesional de Entorno de Trabajo para Ciencia de DatosCurso de Ciencia de Datos para Análisis de NegocioCurso de Excel Analytics con AI y PythonCurso de Manejo de Datos Faltantes: Detección y ExploraciónCurso de Manejo de Datos Faltantes: ImputaciónCurso de Análisis Exploratorio de DatosCurso de Business Intelligence: Utilidad y Áreas de OportunidadCurso de Excel Avanzado para Análisis de DatosCurso de Excel Avanzado con MacrosCurso de Power BICurso de DAX para Power BICurso PowerBI AvanzadoCurso de Tableau: Visualización de Datos y Storytelling para NegociosCurso de Visualización de Datos para BICurso de Visualización de Datos y Storytelling con LatinometricsCurso de Looker StudioCurso de Toma de Decisiones Basadas en DatosMachine Learning y Deep Learning
52 horas de contenidoCurso de Fundamentos de Machine LearningCurso de Álgebra Lineal: Fundamentos y AplicacionesCurso de Álgebra Lineal Aplicada para Machine LearningCurso de Álgebra Lineal para Machine LearningCurso de Regresión Lineal con Python y scikit-learnCurso Avanzado de Álgebra Lineal y Machine Learning: PCA y SVDCurso de Decision Trees y Random Forest con Python y scikit-learnCurso Profesional de Machine Learning con scikit-learnCurso Profesional de Redes Neuronales con TensorFlowCurso de Redes Neuronales con PyTorchCurso de Visión Artificial con PythonCurso de Fundamentos de Procesamiento de Lenguaje Natural con Python y NLTKCurso de Algoritmos de Clasificación de TextoCurso de NLP con PythonCurso de Experimentación en Machine Learning con Hugging FaceCurso de MLOPS: Despliegue de Modelos de Machine LearningData Engineer
36 horas de contenidoCurso de Fundamentos de Ingeniería de DatosCurso de PostgreSQL Aplicado a Ciencia de DatosCurso de Optimización de Bases de Datos en SQL ServerCurso de Modelado de Datos en MongoDBCurso de MongoDB: Aggregation FrameworkCurso de Fundamentos de Spark para Big DataCurso de Databricks: Arquitectura Delta LakeCurso de Fundamentos de Apache AirflowCurso de Big Data en AWSCurso de Amazon DynamoDBCurso de Big Data y Machine Learning con Google Cloud PlatformInteligencia Artificial para la Productividad
48 horas de contenidoCurso de Finanzas Personales con Inteligencia ArtificialCurso de Introducción a la Inteligencia ArtificialCurso Gratis de Introducción a la Inteligencia ArtificialCurso de Prompt EngineeringCurso de ChatGPTCurso de GeminiCurso de Claude AICurso de Windsurf AICurso de tips y trucos de IACurso de Creación de Páginas Web con v0Curso de Fundamentos de LLMsCurso de Inteligencia Artificial para Content MarketingCurso de Inteligencia Artificial para Servicio al ClienteCurso de Inteligencia Artificial para FinanzasCurso Gratis para Crear Agentes de AI con Copilot StudioCurso de Herramientas de Inteligencia Artificial para Equipos de DatosCurso de Inglés para el Uso de Inteligencia ArtificialCurso de Ética y Manejo de Datos para Data Science e Inteligencia ArtificialCurso de Diseño Ético para el Desarrollo de Productos Digitales con IACurso de Generación de Imágenes con Inteligencia ArtificialCurso de Prompt EngineeringCurso de Claude Code para No ProgramadoresCurso de Gemini en Google WorkspaceDesarrollo de Aplicaciones con IA
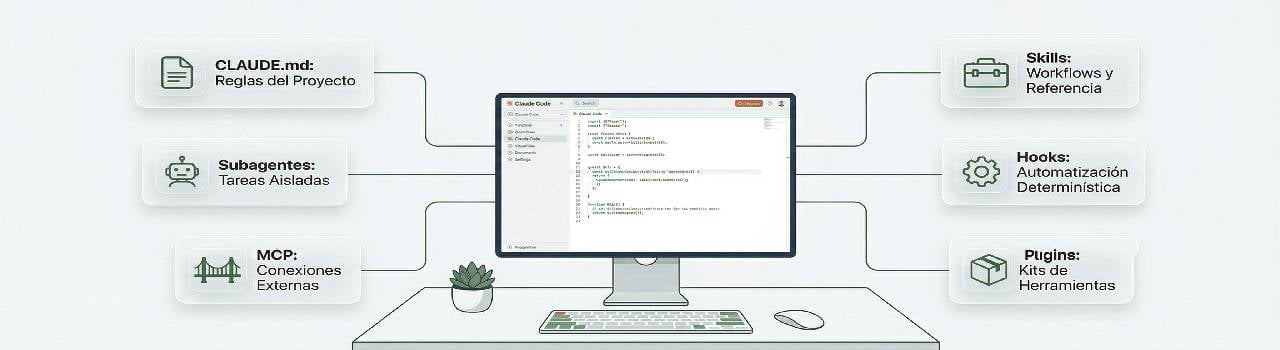
39 horas de contenidoCurso de Desarrollo de Chatbots con OpenAICurso de OpenAI APICurso de Desarrollo de Chatbots con AzureOpenAICurso de LangChainCurso de LangChain para Manejo y Recuperación de DocumentosCurso de RAG con Microsoft AzureCurso de MCP con Microsoft AzureCurso de Agentes AICurso de Cursor AI Code EditorCurso de Claude CodeCurso de Observabilidad de Agentes AI con LangSmithCurso de ChatBot con WhatsApp APICurso de RPA e Hiperautomatización con AIAI Software Engineer
60 horas de contenidoCurso de Introducción a la Inteligencia ArtificialCurso de Pensamiento LógicoCurso de Estadística y ProbabilidadCurso de Git y GitHubCurso de Fundamentos de PythonCurso de Python Intermedio para Entornos virtuales y PEP8Curso de Python Orientado a ObjetosCurso de Unit Testing en PythonCurso de FastAPICurso de Prompt EngineeringCurso de Fundamentos de LLMsCurso de Configuración de APIs de LLMsCurso de Herramientas de AI para DevelopersCurso de Fundamentos de Bases de Datos y SQLCurso de DockerCurso de MCP con Microsoft AzureCurso de RAG con Microsoft AzureCurso de Arquitectura de Software Aplicada
Profes de la escuela
Conoce quién enseña en esta escuela
Carolina Piedrahita
Luis Fernando Laris
Nicolas Molina
Profes AI
Roy Rojas
Renzo Cuadra
Miguel Torres
Enrique Devars
Platzi Team
Ricardo Celis
Jesús Vélez Santiago
Erasmo Hernández
Carli Code
Israel Vázquez Morales
Rodrigo Gómez
Rodrigo Rojo Pizarro
Comunidad
La comunidad es nuestro superpoder
Contenido adicional de la comunidad que nunca para de aprender