
¿Sabias que puedes utilizar pySpark para leer información en formato JSON y convertirla en una estructura de datos (RDD o DataFrame)? En este tutorial te mostraré como manejar estos archivos con este maravilloso framework.
A continuación se presenta un diagrama de flujo que describe el proceso de cómo tratar los datos en formato JSON.
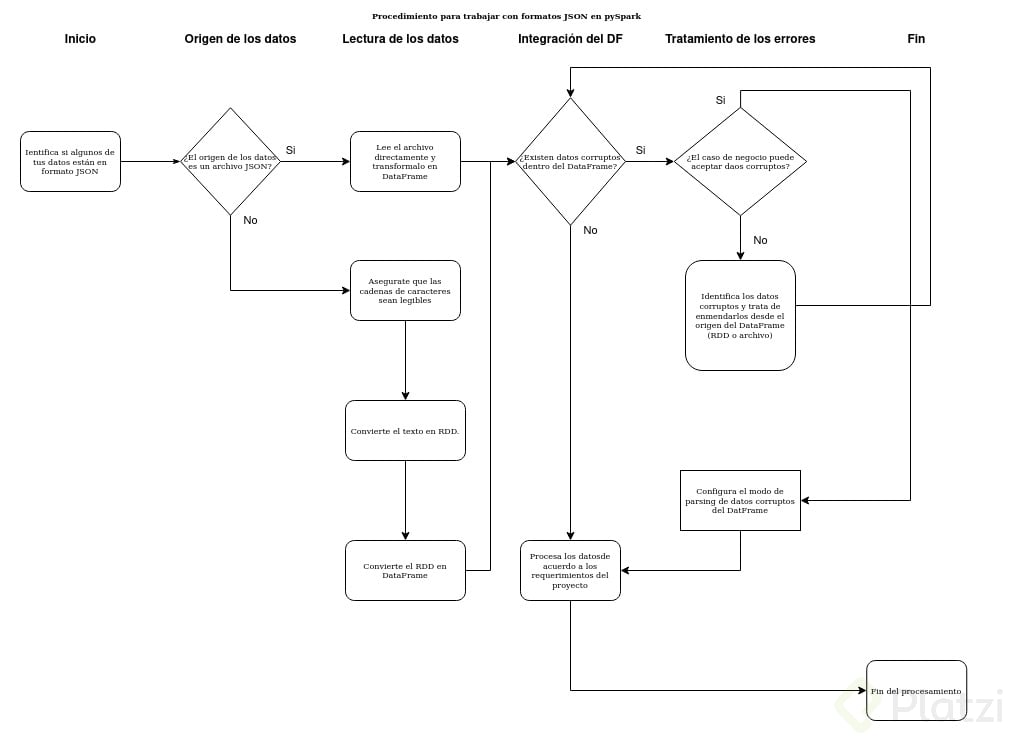
Fig 1. Diagrama de flujo del procedimiento para trabajar con archivos JSON en pySpark
Identifica si algunos de tus datos estan en formato JSON y cual es su origen
Es posible que dentro de tu dataset existan cadenas de caracteres que están escritas en formato JSON, incluso es posiblee que tu dataset esté presentado en uno o varios archivos *.json, es importante saber cual de estas dos presentaciones están expresados los datos, ya que esto determinará el origen de los DataFrames.
Es preciso notar, que pueden existir errores al momento de trabajar con Dataframes de distintos origenes (si proceden por RDDs o directamente de la lectura de algún archivo *.csv o *.json), por lo que definir desde el principio el origen de nuestros DF es muy importante.
Esta es la cabecera que debemos tener antes de trabajar en una sesión de pySpark.
from pyspark import SparkContext, SparkConf
from pyspark.sql import SparkSession
from pyspark.sql.types import StructType, StructField
from pyspark.sql.types import IntegerType, StringType, FloatType, TimestampType
from pyspark.sql.types import Row
from pyspark.sql.functions import *
from pyspark.sql import SQLContext
En caso de que el origen sea directamente un archivo
Si nuestro dataset posee un archivo con extensión *.json, entonces podemos hacer uso de las funciones de sql de pySpark y leer directamente el archivo y convertirlo en DF con el siguiente comando.
df1 = spark.read.json('path/to/filename.json')
Hay que notar, que la propia estructura del archivo JSON es suficiente para definir a la estructura, por lo que no es necesario declarar un schema para la creación del DF.
En caso de que el origen sea una cadena de caracteres
Por otro lado, si nuestros datos están expresados como una cadena de caracteres con la estructura propia de un JSON, e implicita dentro de un archivo (como en un csv, por ejemplo). Entonces debemos transformar esas cadenas con formato en un RDD, posteriormente transformar ese RDD en un DF
onlyJsonData_DF = spark.read.json(RDD_OnlyJsonData, mode="PERMISSIVE",multiLine = "true")
Es importante aclarar que antes de transformar el RDD a DF, las cadenas de caracteres deben ser legibles, homogeneas y deben cumplir con el formato propio de un archivo JSON, de lo contario es posible que se presenten datos corruptos dentro del DF.
Integración de los DataFrames
Recordemos que Spark trabaja de manera lazy, por lo que hacer una operación de conteo o imprimiendo el esquema de la estrucura nos permitirá saber la integridad del DataFrame.
Para imprimir el esquema de un DataFrame, hacemos uso del siguiente comando:
onlyJsonData_DF.printSchema()
Un esquema típico de un DF que tiene datos en formato JSON como origen luce de la siguiente manera:
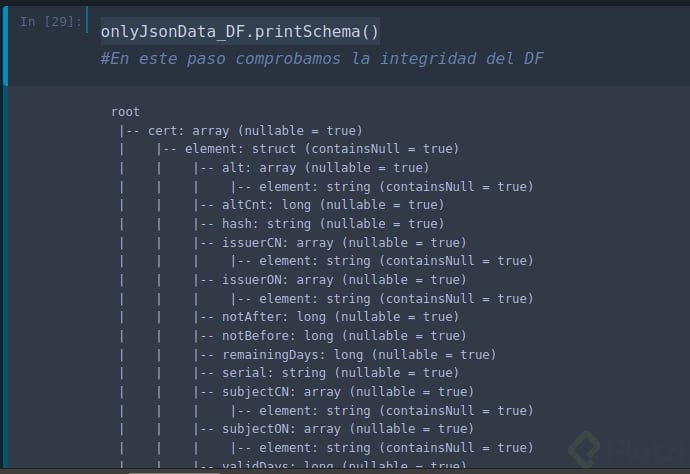
Fig 2. Esquema típico de un DF que contiene datos en formato JSON
Notese que este tipo de esquemas están ramificados en niveles. Esta estructura nos obliga a trabajar en niveles y con diferentes DF para poder visualizar los datos de mayor profundidad.
Procesamiento
Para seleccionar campos del mismo nivel de jerarquía, hacemos uso de la función select:
srcIP_DF = onlyJsonData_DF.select("srcIP","srcBytes","totBytes","length")
Para poder explorar niveles más profundos de la estructura principal, hacemos uso de la función explode, esta función toma como argumento el campo que se desea explorar:
Protocol_DF = onlyJsonData_DF.select("srcIP",explode("protocol").alias("hierarchy")\
,"srcBytes","totBytes","length")
Manejo de datos corruptos
Si nuestro modelo de negocio nos permite tener datos corruptos, entonces debemos definir un modo de parsing para estos casos. Lo ideal es que nuestro dataset no contenga datos corruptos, ya que esto representa pérdida de información. Si nuestro modelo de negocio no acepta datos corruptos, entonces debemos de buscar los errores de los archivos o de la cadena de caracteres y tratar de enmendarlos desde el origen.
Documentación
Para este tutorial, consulté las siguientes fuentes:
-
Artículo de Medium, con un ejemplo incluido: https://medium.com/expedia-group-tech/working-with-json-in-apache-spark-1ecf553c2a8c
-
Documentación oficial del framework: https://spark.apache.org/docs/latest/api/python/reference/api/pyspark.sql.DataFrameReader.json.html?highlight=json#pyspark.sql.DataFrameReader.json
-
Repositorio de GitHub: https://github.com/Meluiscruz/Technical_Test_for_Seguritech
Curso de Fundamentos de Spark para Big Data
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


