
Una técnica de Storytelling que se puede aplicar a cualquier problema empresarial es estructurar el problema a través de realizar preguntas para generar una hipótesis que permita proponer soluciones a partir del manejo y análisis de los datos. Esto funciona para empresas o startups que tienen una cultura con base en los datos, también llamada Data Driven.
Para poder formar esta cultura en una empresa es necesario establecer una serie de acciones con base en los siguientes pasos:
1.- Crear una cultura de datos en donde todo el personal conozca para que sirve el uso de los datos, y comenzar a hacer que todos los empleados tomen y utilicen datos.
2.- Recolectar información. Todo lo que la empresa ya obtiene:
- Información de clientes.
- Transacciones.
- Navegación web de usuarios.
- Datos biométricos.
- GPS
- Otros datos que se manejen.
3.- Medir Todo. No basarse solamente en una parte de la información. Entender como se comportan los datos.
4.- Datos Relevantes y Precisos. Datos que realmente sirvan a la empresa, determinando cuales son los más relevantes para la empresa y los clientes.
5.- Hacer pruebas y crear hipótesis. Crear preguntas para obtener y dirigir el estudio que haremos. Cierto VS Falso.
6.- Desde los insights de datos a las acciones. Pensar en la pregunta, si se tiene la información para validarla y transformarla en acciones.
7.- Cumplir las regulaciones de datos. No se pueden tomar decisiones sesgadas en función del género, de información privada. Tener ética con los datos y cumplir reglamentos.
8.- Automatizar. Poder replicar los estudios cada vez que sea necesario.
Una vez que tenemos datos suficientes que nos permitan afrontar problemas, éstos se pueden abordar a partir de preguntas ¿Qué?, ¿Por qué? y ¿Cómo?
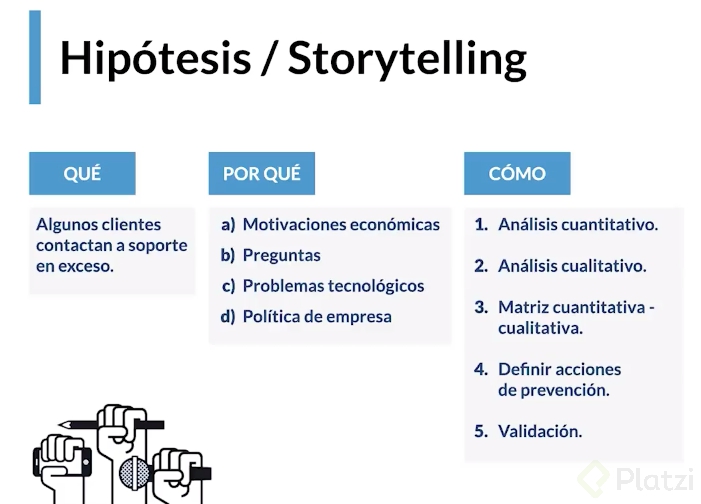
En el ejemplo que se propone en el curso se tiene un problema al recibir 6 millones de contactos de usuarios por lo que se quiere buscar las razones principales de los usuarios obteniendo además información geográfica relevante y tipo de usuarios que hacen las quejas.
Análisis Cuantitativo
Identificar las variables numéricas que nos ayudarán a resolver el ejercicio.
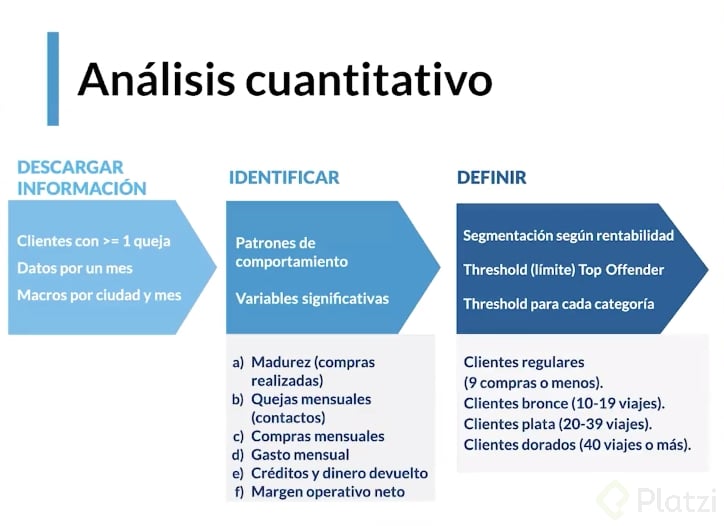
1.- ¿Qué?
-¿Quienes pueden ser los top offenders?
Para identificarlos debemos descargar la información de la manera más genérica posible y después se clasifican. Para que sea genérico tenemos que encontrar cualquier cliente que por lo menos haya hecho una queja en un mes, al equipo de soporte. Hacer macros o variables adaptables por ciudad y por mes. Esto servirá para replicarlo.
2.- Identificación
Para identificar quiénes son debemos encontrar patrones de comportamiento y variables significativas estos van a ser las variables que nos ayuden a definir si alguien es ofender top offender.
Hipótesis de variables
- Madurez. Experiencia del usuario utilizando la plataforma, lo evaluamos al verificar el número de comprar realizadas.
- Quejas mensuales. Número de quejas que hizo un cliente o usuario.
- Compras Mensuales. Evaluar el numero de compras y el número de quejas correspondientes a esas compras. Encontrar una relación de comportamiento.
- Gasto mensual. Tomar en cuenta el tipo de producto y su complejidad, lo cuál va relacionado muchas veces con el precio del mismo.
- Créditos y dinero devuelto. Identificar si es una persona que busca una compensación económica.
- Margen operativo neto. Es el Rendimiento. Que te queda como empresa a partir del comportamiento del usuario o cliente.
- (Lo que vendí x precio de lo que vendí)- recursos de soporte post venta - Dinero devuelto == Cuanto nos queda a la empresa.
3.- Fase de Definición
Objetivo = encontrar una segmentación con base en la rentabilidad.
Si un usuario es más rentable(compra más), le permito que se queje más.
Threshold(límite). Definir el límite entre una persona que sus quejas sean normales y otra que excede las quejas normales. Definir un Threshold para cada categoría.
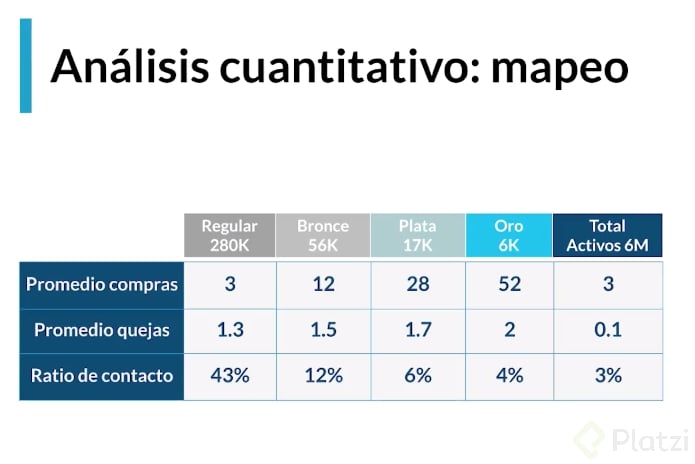
Mapeo: Identificar cuántos usuarios se tienen de cada tipo. Tener siempre la referencia de que es un comportamiento normal.
Hipótesis inicial: Los usuarios que más compran son los que se quejan menos porque ya conocen el sistema.
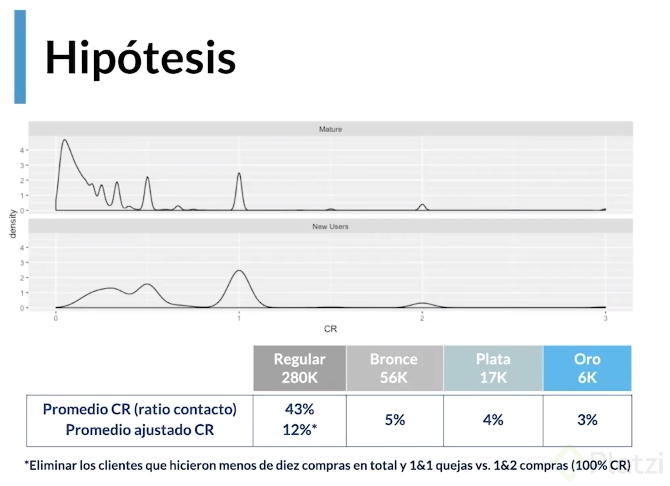
Con el análisis de la gráfica anterior se comprueba la hipótesis de que aquellos usuarios que ya tienen experiencia con nuestro producto se quejan menos. La importancia de la maduración en la experiencia se hace evidente por lo que se ajusta la relación de quejas quitando a los usuarios regulares nuevos, quedando el ratio de contacto para estos usuarios en 12%.
4.- Aplicación
Objetivo: Encontrar el número de top offenders de cada una de las categorías.
Para lograr este objetivo es necesario definir el límite(threshold), buscando impactar el mínimo de usuarios posibles y afectar el máximo volumen de quejas.

En el ejemplo anterior, si analizamos el 20% de los usuarios regulares que se quejaron, puedo definir el 35% de sus quejas y resolverlas. Para usuarios bronce, plata y oro el radio es muy amplio. Analizando pocos usuarios puedo resolver un gran número de quejas.
Esto se vuelve importante al tener un número de quejas muy alto, para el ejemplo el número total de quejas es de 6 millones. Con solo analizar a 43,250 clientes podemos resolver el 20% de las quejas.
Análisis Cualitativo
Identificar las categorías que disponemos para el análisis cualitativo
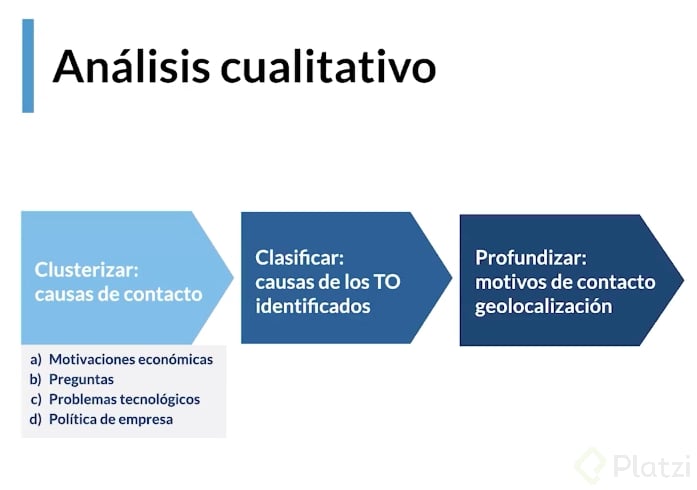
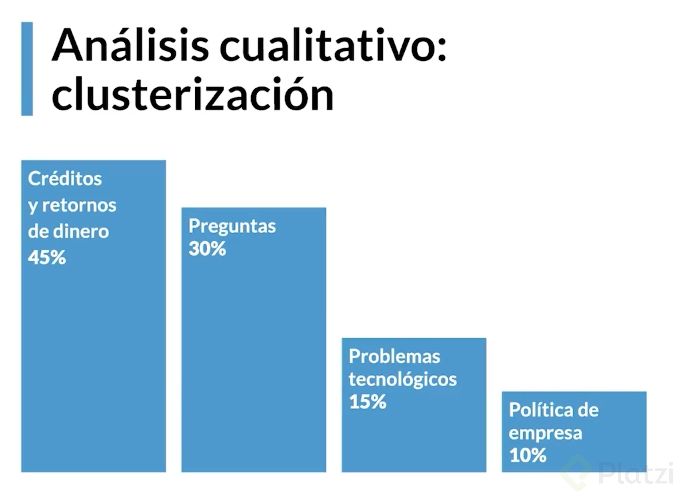
Clusterizar: Agrupar las problemáticas, motivaciones y contactos por parte de los clientes a las que nos enfrentamos. Este ejemplo se clasificaron en 4 categorías las más de 500 tipos contactos:
- Motivación económica. Buscan que se les devuelva el dinero. Ésta es la más grave ya que además de ser una queja, se les devuelve el dinero.
- Preguntas. Los clientes tienen dudas.
- Problemas tecnológicos. Relevante para identificar fallas técnicas del servicio o producto.
- Política de empresa.
Clasificación
Definir los motivos detrás de los mensajes, cuando los hayamos clasificado dentro de una categoría profundizaremos en los motivos de contacto de una manera geolocalizada por lo que tendremos especificidad en cada contexto social.
Fusión Cuanti-Cualitativa en un caso de Negocio
Resolver de manera conjunta la información cuantitativa y cualitativa para sacar conclusiones.
Una vez que tenemos información sobre cuáles son las razones por las que los clientes nos contactan así como una clasificación de los top offenders vamos a ver por qué se queja cada uno de los tipos de top offenders para encontrar las claves del análisis.
Para este análisis se utiliza una tabla con un mapa de calor para resaltar los porcentajes más elevados y poder concentrar nuestra atención en los problemas mayores más rapidamente.
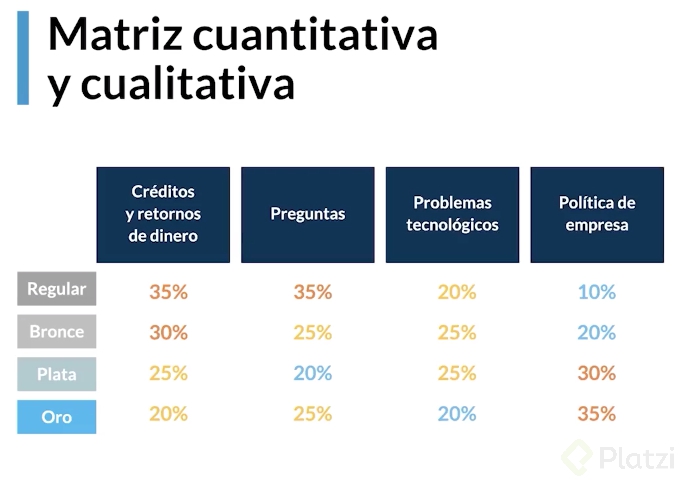
Observando los resultados podemos ver un comportamiento de matriz opuesta entre los clientes regulares y los clientes oro. Los regulares, que menos compran, son aquellos que más contactan a la empresa para recuperar su dinero.
En el caso de los clientes plata y oro podemos identificar que las quejas se distribuyen entre los diferentes problemas acumulándose en problemas de políticas de empresa, lo que podemos etiquetar como un comportamiento bueno pero inquietante.
¿Qué es minería de texto?
¿Cómo utilizarla para obtener información adicional?
Minería de texto. Nos ayuda a leer los mensajes y poder encontrar información que no teníamos.
La minería de textos es una rama específica de la minería de datos que se refiere al proceso de analizar y derivar información nueva de textos. Por medio de la identificación de patrones o correlaciones entre los términos se logra encontrar información que no está explícita dentro del texto. Los textos que se usan como recursos pueden ser páginas web, libros, correos electrónicos, reseñas de clientes, artículos, entre otros.
La minería de textos es un área multidisciplinaria basada en la recuperación de información, aprendizaje automático, estadísticas y la lingüística computacional. Como la mayor parte de la información (más de un 80%) se encuentra actualmente almacenada como texto, se cree que la minería de textos tiene un gran valor comercial.
Por ejemplo: Twitter, tiene su base de negocio en la exploración de los mensajes.
<h3>Recolección de datos</h3>Se deben recolectar los datos que se desean estudiar. Pueden ser de diferentes recursos como páginas web, libros, correos electrónicos, reseñas de clientes, artículos, entre otros.
<h3>Preprocesamiento</h3>Los datos que se obtienen generalmente deben ser limpiados y estructurados de tal manera que puedan ser usados más adelante. El preprocesamiento incluye eliminar todas las partes del texto que no son necesarias. Por ejemplo, se pueden eliminar las palabras como “y”, “pero”, “es”, que son palabras que no aportan al contenido del texto. Además, se pueden eliminar los signos de puntuación, o incluso reducir las palabras a sus raíces.
<h3>Enriquecimiento</h3>Cada término que se encuentra dentro del texto puede ser enriquecido al agregarle una etiqueta. Esta etiqueta puede ser del tipo de Partes del Discurso o POS, por sus siglas en inglés. En este caso, las palabras obtienen una etiqueta que las define como “sustantivos”, “adjetivos”, “adverbios”, entre otros. Otro tipo de etiquetas es el de Entidades Nombradas o NE, por sus siglas en inglés. En este caso las etiquetas que se agregan pueden ser del tipo “personas”, “organizaciones”, entre otras.
<h3>Transformación</h3>Para poder analizar los textos con algoritmos que se emplean a la hora de analizar datos numéricos, como algoritmos estadísticos o de inteligencia artificial, el texto debe ser convertido a números. Esto puede llevarse a cabo convirtiendo los textos en vectores que sean de bits o numéricos.
<h3>Extracción de características</h3>Cuando ya finalmente se tiene el texto original en una forma numérica, se pueden aplicar diferentes algoritmos para poder extraer lo que se desea. Algoritmos comunes incluyen aquellos que usan los principios estadísticos para extraer información clave o algoritmos de inteligencia artificial.

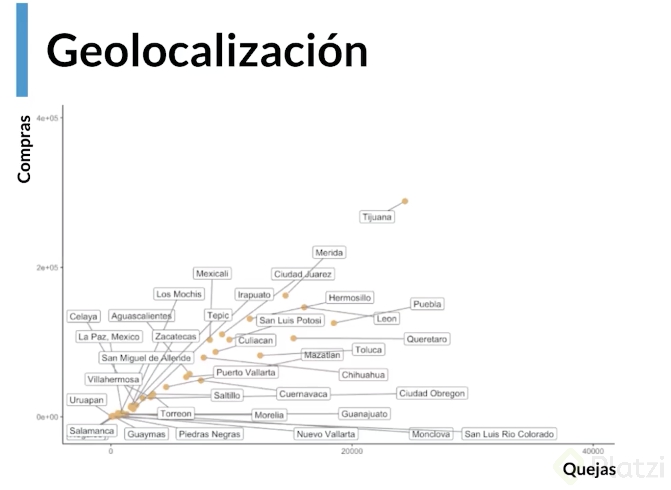
Variación de comportamientos a partir de la Geolocalización
Relevancia del comportamiento de acuerdo al origen geográfico por país, ciudad, distrito.
En el caso de top offenders se creó un gráfico que compara las quejas vs compras de acuerdo al origen geográfico de las mismas, en este caso a nivel de ciudad. Se espera obtener una línea de 45º si el comportamiento de los resultados es normal.
Aquellas ciudades que se alejen de la línea son aquellas que tienen más top offenders de lo normal. Las ciudades con más top offenders son Puebla, Querétaro, Toluca; esto se define al observar que las ciudades se encuentran más alejadas del eje normal y más cercanas al eje de las quejas.
Toma de decisiones según los resultados del análisis
Convertir la información obtenida del análisis en una estrategia o toma de decisiones.
Acciones derivadas del análisis
Algoritmos utilizados
- Minería de datos para clasificación de motivos de contacto.
- Correlaciones y patrones de comportamiento.
- Árboles de decisión y teoría de juegos para predecir y tomar decisiones.
- Validación con bayesianos y cadenas de Montecarlo(MCMC).
Acciones
- Taggear a los Top Offenders ydentificados mensualmente.
- Advertirlos.
- Llamar a usuarios.
- Bloquear a usuarios.
- Validación con A/B test.
Resultados de las acciones: Disminuyeron las quejas un 30% a nivel Latam.
Curso de Análisis de Negocios para Ciencia de Datos
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE



