
Con este aporte me gustaría ampliar la clase #12 del profesor Francisco, "MLE en machine learning"
Introducción
Explicaré cuál es el método de máxima verosimilitud para la estimación de parámetros y pasaré por un ejemplo simple para demostrar el método. Parte del contenido requiere conocimiento de conceptos fundamentales de probabilidad, como la definición de probabilidad conjunta y la independencia de eventos que se vieron en clases anteriores con Pacho.
Para esto debemos definir primero ¿Qué son los parámetros? Regularmente, en Machine learning usamos un modelo para describir el proceso que da como resultado los datos que se observan. Por ejemplo, podemos usar un modelo lineal para predecir los ingresos que se generarán para una empresa dependiendo de cuánto puede gastar en publicidad (este sería un ejemplo de regresión lineal ). Cada modelo contiene su propio conjunto de parámetros que, en última instancia, define cómo se ve el modelo. Para un modelo lineal, podemos escribir esto como y = mx + c . En este ejemplo, x podría representar el gasto en publicidad e y podría ser el ingreso generado. m y c son parámetros de este modelo. Diferentes valores para estos parámetros darán diferentes líneas:
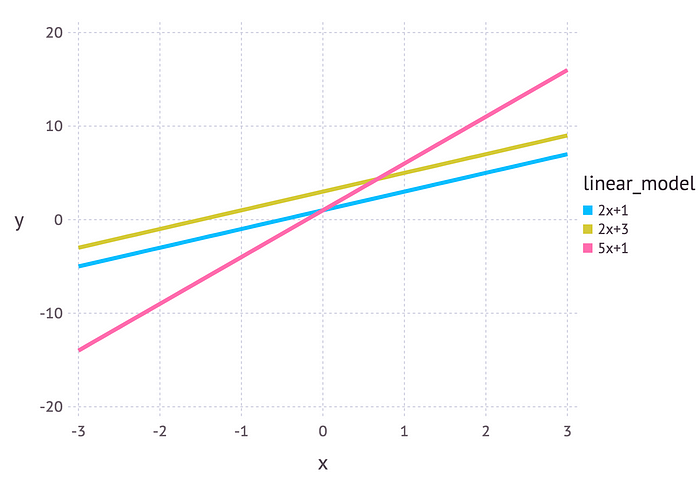
Entonces, los parámetros definen un plan para el modelo. Es solo cuando se eligen valores específicos para los parámetros que obtenemos una instanciación del modelo que describe un fenómeno dado.
Explicando ahora intuitivamente la **estimación de máxima verosimilitud **(likelihood): Es un método que determina valores para los parámetros de un modelo. Los valores de los parámetros se encuentran de manera que maximizan la probabilidad de que el proceso descrito por el modelo produzca los datos que realmente se observaron. La definición anterior aún puede sonar un poco engorrosa, así que colocaré un ejemplo para ayudar a comprender esto.
Supongamos que hemos observado 10 puntos de datos de algún proceso. Por ejemplo, cada punto de datos podría representar el tiempo en segundos que le toma a un estudiante responder una pregunta específica del examen. Estos 10 puntos de datos serían estos:
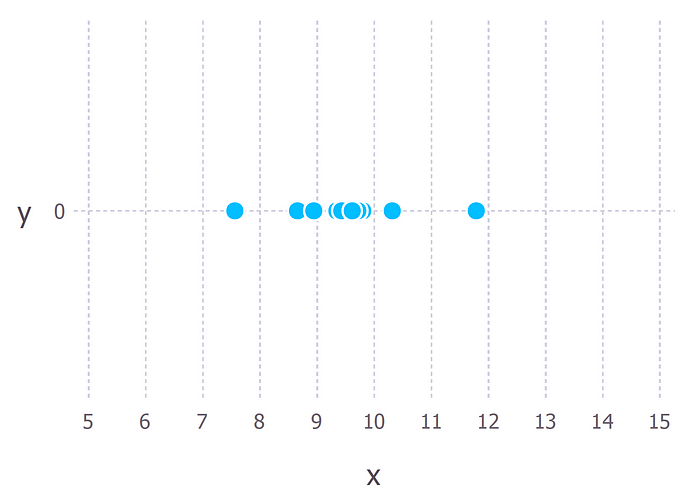
Primero tenemos que decidir qué modelo creemos que describe mejor el proceso de generación de datos. Para estos datos, asumiremos que el proceso de generación de datos puede describirse adecuadamente mediante una distribución gaussiana (normal). La inspección visual de la figura anterior sugiere que una distribución gaussiana es recomendable porque la mayoría de los 10 puntos están agrupados en el medio con algunos puntos dispersos a la izquierda y a la derecha.
Recuerde que la distribución gaussiana tiene 2 parámetros. La media, mu, y la desviación estándar, sigma. Los diferentes valores de estos parámetros dan como resultado diferentes curvas (al igual que con las líneas rectas de arriba). Queremos saber qué curva fue más probablemente responsable de crear los puntos de datos que observamos. La estimación de máxima verosimilitud es un método que encontrará los valores de mu y sigma que dan como resultado la curva que mejor se ajusta a los datos. Para la anterior figura asumiremos que sigue una distribución normal con media mu = 10 y sigma=2.25 -> N(10, 2.25)
Ahora que tienes una comprensión intuitiva de lo que es la estimación de máxima verosimilitud (eso espero!), podemos pasar a aprender a calcular los valores de los parámetros. Los valores que encontramos se denominan estimaciones de máxima verosimilitud (MLE). Nuevamente demostraremos esto con un ejemplo. Supongamos que esta vez tenemos tres puntos de datos y suponemos que se han generado a partir de un proceso que se describe adecuadamente mediante una distribución gaussiana. Estos puntos son 9, 9.5 y 11. ¿Cómo calculamos las estimaciones de máxima verosimilitud de los valores de los parámetros de la distribución gaussiana mu y sigma? Lo que queremos calcular es la probabilidad total de observar todos los datos, es decir, la distribución de probabilidad conjunta de todos los puntos de datos observados.
Vamos a suponer que cada punto de datos se genera independientemente de los demás . Esta suposición facilita mucho las matemáticas. Si los eventos (es decir, el proceso que genera los datos) son independientes, entonces la probabilidad total de observar todos los datos es el producto de observar cada punto de datos individualmente (es decir, el producto de las probabilidades marginales). La densidad de probabilidad de observar un único punto de datos x, que se genera a partir de una distribución gaussiana, viene dada por:
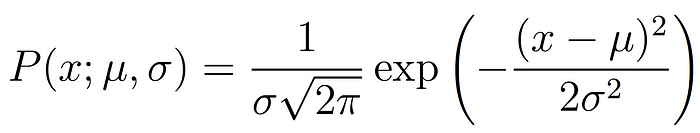
En nuestro ejemplo, la densidad de probabilidad total (conjunta) de observar los tres puntos de datos viene dada por:
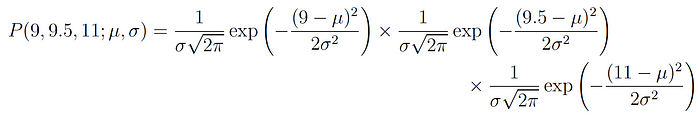
Tenemos que averiguar los valores de mu y sigma que dan como resultado el valor máximo de la expresión anterior. Todo lo que tenemos que hacer es encontrar la derivada de la función, establecer la función derivada en cero y luego despejar el parametro de interes (mu o sigma). De esta manera, tendremos nuestros valores MLE para nuestros parámetros.
usando leyes de logaritmos se obtiene esto:
y ahora aplicando derivada parcial a la expresión en función de mu:
Y cuando hacemos el lado izquierdo de la ecuación igual a cero (0), obtendremos nuestra estimación de máxima verosimilitud para mu, el cual será de 9.833.
CONCLUSIÓN
¿Cuándo es la minimización de mínimos cuadrados lo mismo que la estimación de máxima verosimilitud?
La minimización de mínimos cuadrados es otro método común para estimar valores de parámetros para un modelo en machine learning. Resulta que cuando se supone que el modelo es gaussiano como en los ejemplos anteriores, las estimaciones de MLE son equivalentes al método de mínimos cuadrados. Para la estimación de parámetros de mínimos cuadrados, queremos encontrar la línea que minimiza la distancia al cuadrado total entre los puntos de datos y la línea de regresión (recuerden el ruido gaussiano, -noise-, que Pacho menciona en la clase). En la estimación de máxima verosimilitud queremos maximizar la probabilidad total de los datos. Cuando se asume una distribución gaussiana, la probabilidad máxima se encuentra cuando los puntos de datos se acercan al valor medio. Dado que la distribución gaussiana es simétrica, esto equivale a minimizar la distancia entre los puntos de datos y el valor medio
Por último si quieren saber más del tema les dejo estos dos links que me fueron de gran utilidad:
Regresión
Curso de Matemáticas para Data Science: Probabilidad
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


