
¿Qué son los modelos Naive Bayes?
Los modelos de Naive Bayes son una clase especial de algoritmos de clasificación de Machine Learning. Se basan en una técnica de clasificación estadística llamada “teorema de Bayes”. Estos modelos son llamados algoritmos “Naive”, o “Inocentes” en español. En ellos se asume que las variables predictoras son <ins>independientes</ins> entre sí. En otras palabras, que la presencia de una cierta característica en un conjunto de datos no está en absoluto relacionada con la presencia de cualquier otra característica. Proporcionan una manera fácil de construir modelos con un comportamiento muy bueno debido a su <ins>simplicidad</ins>. Lo consiguen proporcionando una forma de calcular la probabilidad ‘posterior’ de que ocurra un cierto evento A, dadas algunas probabilidades de eventos ‘anteriores’.

EJEMPLO
Consideremos el caso de dos compañeros que trabajan en la misma oficina: Alicia y Bruno. Sabemos que:
-
Alicia viene a la oficina 3 días a la semana.
-
Bruno viene a la oficina 1 día a la semana.
Esta sería nuestra información “anterior”. Estamos en la oficina y vemos pasar delante de nosotros a alguien muy rápido, tan rápido que no sabemos si es Alicia o Bruno. Dada la información que tenemos hasta ahora y asumiendo que solo trabajan 4 días a la semana, las probabilidades de que la persona vista sea Alicia o Bruno, son:
-
P(Alicia) = 3/4 = 0.75
-
P(Bruno) = 1/4 = 0.25
Cuando vimos a la persona pasar, vimos que él o ella llevaba una chaqueta roja. También sabemos lo siguiente:
-
Alicia viste de rojo 2 veces a la semana.
-
Bruno viste de rojo 3 veces a la semana.
Así que, para cada semana de trabajo, que tiene cinco días, podemos inferir lo siguiente:
-
La probabilidad de que Alicia vista de rojo es → P(Rojo|Alicia) = 2/5 = 0.4
-
La probabilidad de que Bruno vista de rojo → P(Rojo|Bruno) = 3/5 = 0.6
Entonces, con esta información, ¿a quién vimos pasar? (en forma de probabilidad).
Esta nueva probabilidad será la información ‘posterior’.

Inicialmente conocíamos las probabilidades P(Alicia) y P(Bruno), y después inferíamos las probabilidades de P(rojo|Alicia) y P(rojo|Bruno).
De forma que las probabilidades reales son:

Siendo rigurosos:
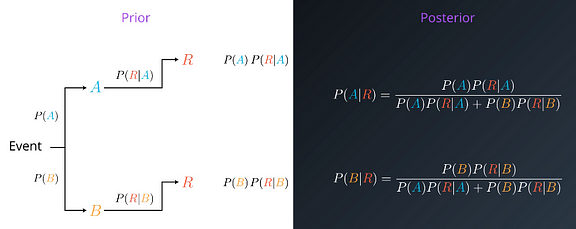
Algoritmo Naive Bayes Supervisado
A continuación se listan los pasos que hay que realizar para poder utilizar el algoritmo Naive Bayes en problemas de clasificación como el mostrado en el apartado anterior.
-
Convertir el conjunto de datos en una tabla de frecuencias.
-
Crear una tabla de probabilidad calculando las correspondientes a que ocurran los diversos eventos.
-
La ecuación Naive Bayes se usa para calcular la probabilidad posterior de cada clase.
-
La clase con la probabilidad posterior más alta es el resultado de la predicción.
Esto nos lleva a que este algoritmo tiene algunos puntos débiles y fuertes, observémoslos:
VENTAJAS
-
Un manera fácil y <ins>rápida</ins> de predecir clases, para problemas de clasificación binarios y multiclase.
-
En los casos en que sea apropiada una presunción de independencia, el algoritmo <ins>se comporta mejor</ins> que otros modelos de clasificación, incluso con menos datos de entrenamiento.
-
El desacoplamiento de las distribuciones de características condicionales de clase significan que cada distribución puede ser estimada independientemente como si tuviera una sola dimensión. Esto ayuda con problemas derivados de la dimensionalidad y mejora el rendimiento.
DESVENTAJAS
-
Aunque son unos clasificadores bastante buenos, los algoritmos Naive Bayes son conocidos por ser pobres estimadores. Por ello, no se deben tomar muy en serio las probabilidades que se obtienen.
-
La presunción de independencia Naive muy probablemente no reflejará cómo son los datos en el mundo real.
Cuando el conjunto de datos de prueba tiene una característica que no ha sido observada en el conjunto de entrenamiento, el modelo le asignará una probabilidad de cero y será inútil realizar predicciones. Uno de los principales métodos para evitar esto, es la técnica de suavizado, siendo la estimación de Laplace una de las más populares.
Así que si Platzi no tiene un curso de transformadas integrales, serviría bastante hacer uno para profundizar en estos métodos de Machine learning 😉
Curso de Matemáticas para Data Science: Probabilidad
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


