
Hola comunidad, vengo a mostrarles el resultado de aplicar un escalamiento tanh a un set de datos y los buenos resultados que obtuve, comparándolos con otros escaladores lineales.
Para este experimento tome de kaggle el dataset de California Housing Prices
El objetivo es predecir el valor medio de los inmuebles,
Iré al grano mostrando el proceso de escalamiento y los resultados, dejo acá el colab con el procedimiento completo.
Antes de escalar los datos dividiré en train y test y los escalare por separado, como comenta Carlos Alarcon en el curso de Curso de Fundamentos de Redes Neuronales con Python y Keras, los datos de test no deben poseer información de los datos de train, ya que incurrimos en faltas éticas y aparte conlleva a que nuestro modelo presente overfitting.
from sklearn.model_selection import train_test_split
X_train, X_test, y_train, y_test = train_test_split(features_fill, target, test_size=0.2)
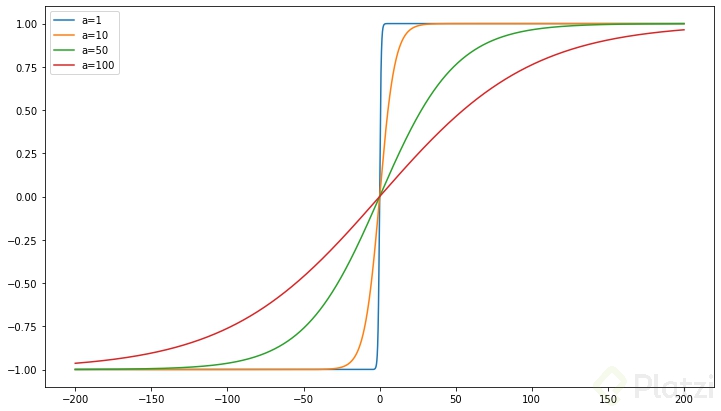
Para el escalamiento usé la función tanh(x/a)
Donde:
- x será la variable a escalar y
- a será la media de la misma variable, uso la media ya que me interesa el aporte de los datos sesgados.
Ésta solo arroja valores entre -1 y1, y dependiendo del tamaño de a el espectro de valores ira de valores que parecieran discretos a un espectro continuo.

Los métodos de escalamiento con los que haré las comparaciones son:
from sklearn.preprocessing import StandardScaler
from sklearn.preprocessing import MinMaxScaler
from sklearn.preprocessing import RobustScaler
También durante el proyecto decidí buscar con varios métodos de regresión, y ver cual me daba los mejores resultados.
Estos son los que use:
from sklearn.tree import DecisionTreeRegressor
from sklearn.ensemble import RandomForestRegressor
from sklearn.linear_model import LinearRegression
from sklearn.metrics import mean_squared_error
Observemos los resultados al evaluar:
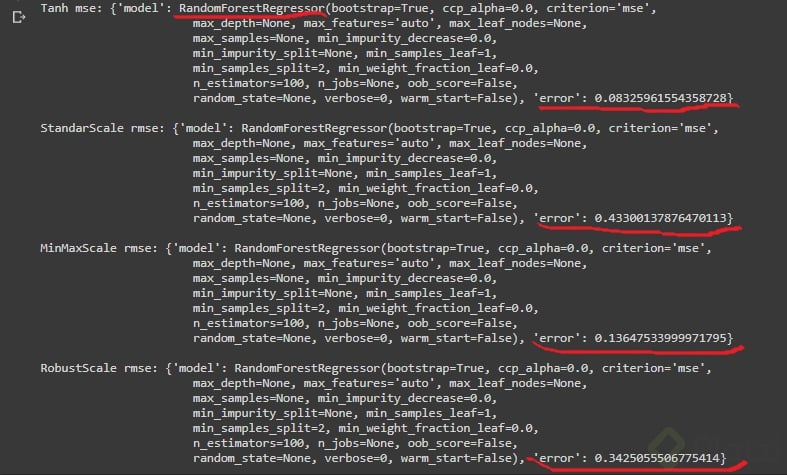
Obtenemos valores muy pequeños que a simple vista no representan valores de casas, entonces procedemos a re-escalar estos resultados. Para esto las funciones de Scikitlearn cuentan con el método inverse_transform. Solo lo aplicamos a nuestro resultado y obtenemos:
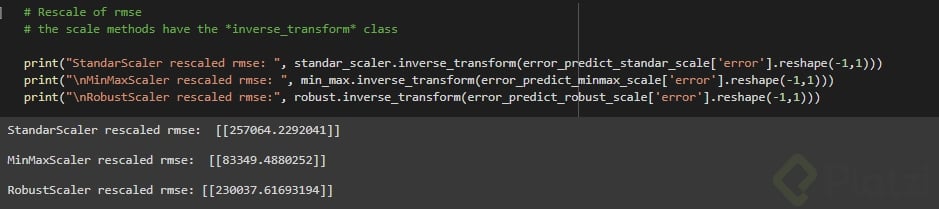
Y aquí viene la magia…
Cuando re-escalamos el resultado de la escala tanh
usando la fórmula


Como se puede observar es una gran mejora, casi $6000 USD de diferencia con el menor error obtenido con modelos alimentado con escaladores lineales.
Curso de Matemáticas para Data Science: Estadística Descriptiva
COMPARTE ESTE ARTÍCULO Y MUESTRA LO QUE APRENDISTE


