¡Es hora de contribuir a la creación de mejores modelos LLM en nuestro idioma! Lo mejor es que sean open source para que podamos implementarlos en todos nuestros proyectos y organizaciones de una manera sencilla y gratuita.
Con el equipo de SOMOSNLP decidimos traducir y curar el dataset de Alpaca Standford para este objetivo. Nos apoyaremos de Hugging Face y otras herramientas para lograrlo.
Te invito a tomar el Curso De Transfer Learning con Hugging Face para entender mucho mejor como funciona la comunidad y la plataforma 🚀

Alpaca Stanford es un proyecto de LLM open source el cual se basa en LLaMA, un modelo open source del equipo de Meta AI. Para este reto, usaremos una versión traducida del dataset curado de Alpaca Standford.
El objetivo es evaluar el dataset y crear múltiples versiones con las contribuciones de todos los participantes, para luego unirlos y obtener un dataset de alta calidad con el cual entrenar encima de un modelo base como lo es LLaMA o Bloom o incluso GPT4.

Antes de iniciar, es indispensable que tengas una cuenta personal de Hugging Face 🤗. Puedes crearla aquí.
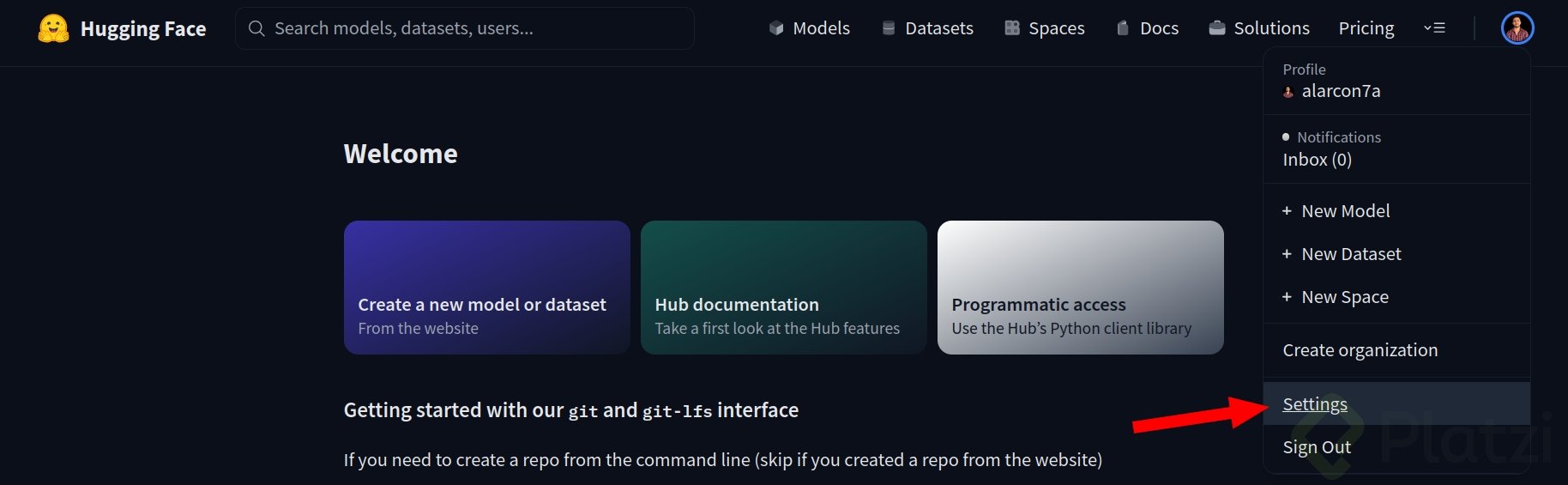
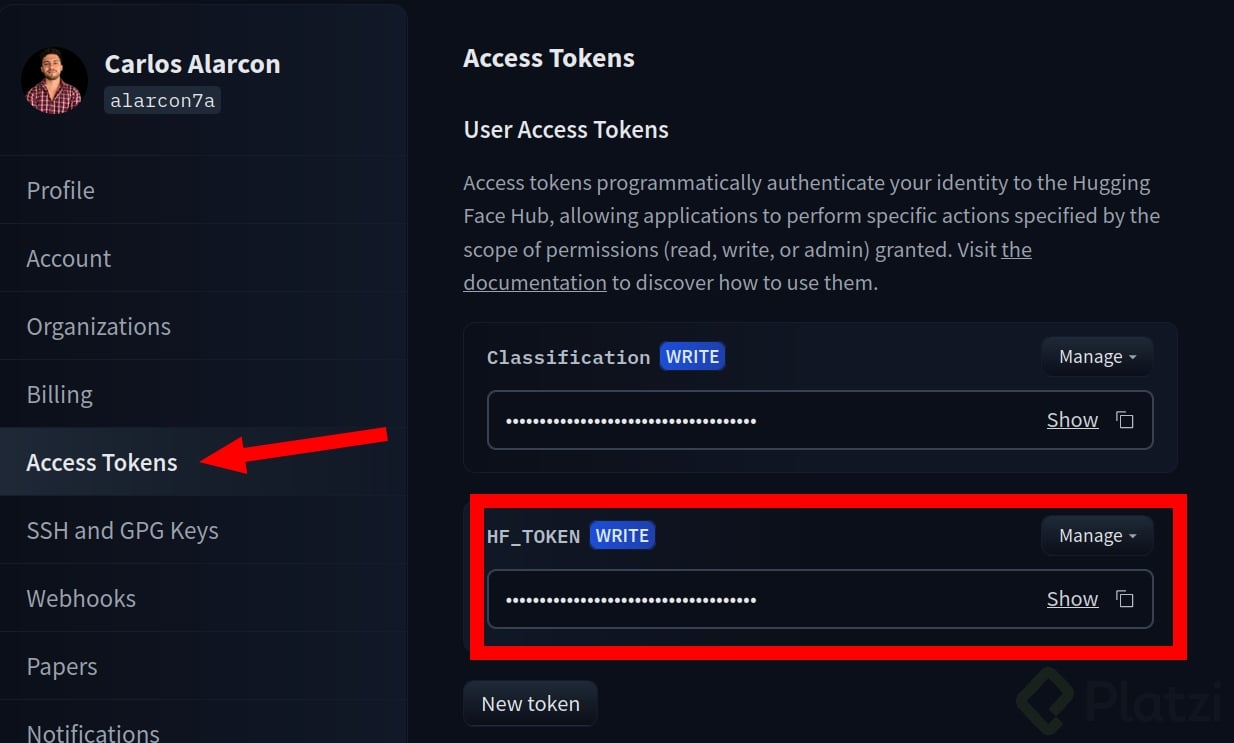
En las configuraciones o ajustes de tu cuenta de Hugging Face, dirígete a “Access Tokens” y crea un token de tipo escritura. Este lo usaremos más adelante.
💡 Si ya tienes este token, puedes saltarte este paso.
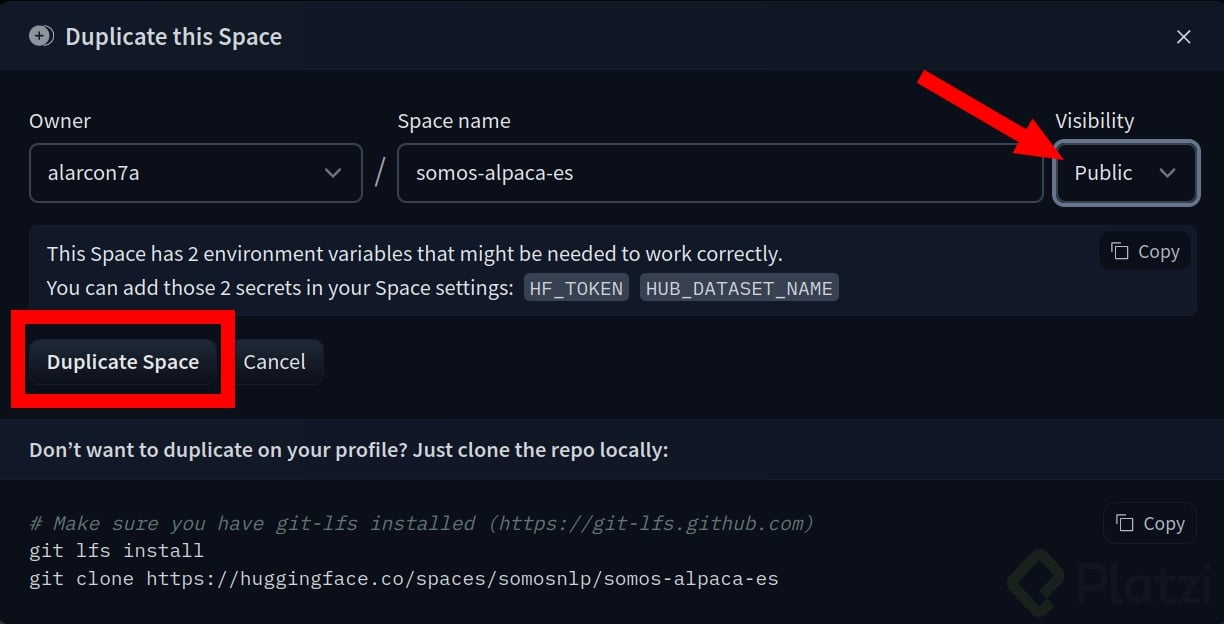
Usando este enlace y estando conectado desde tu cuenta en Hugging Face, duplica el espacio siguiendo la imagen de referencia. Es importante que el espacio esté como público 🚀.
💡 (Este proceso puede tardar 10 minutos)
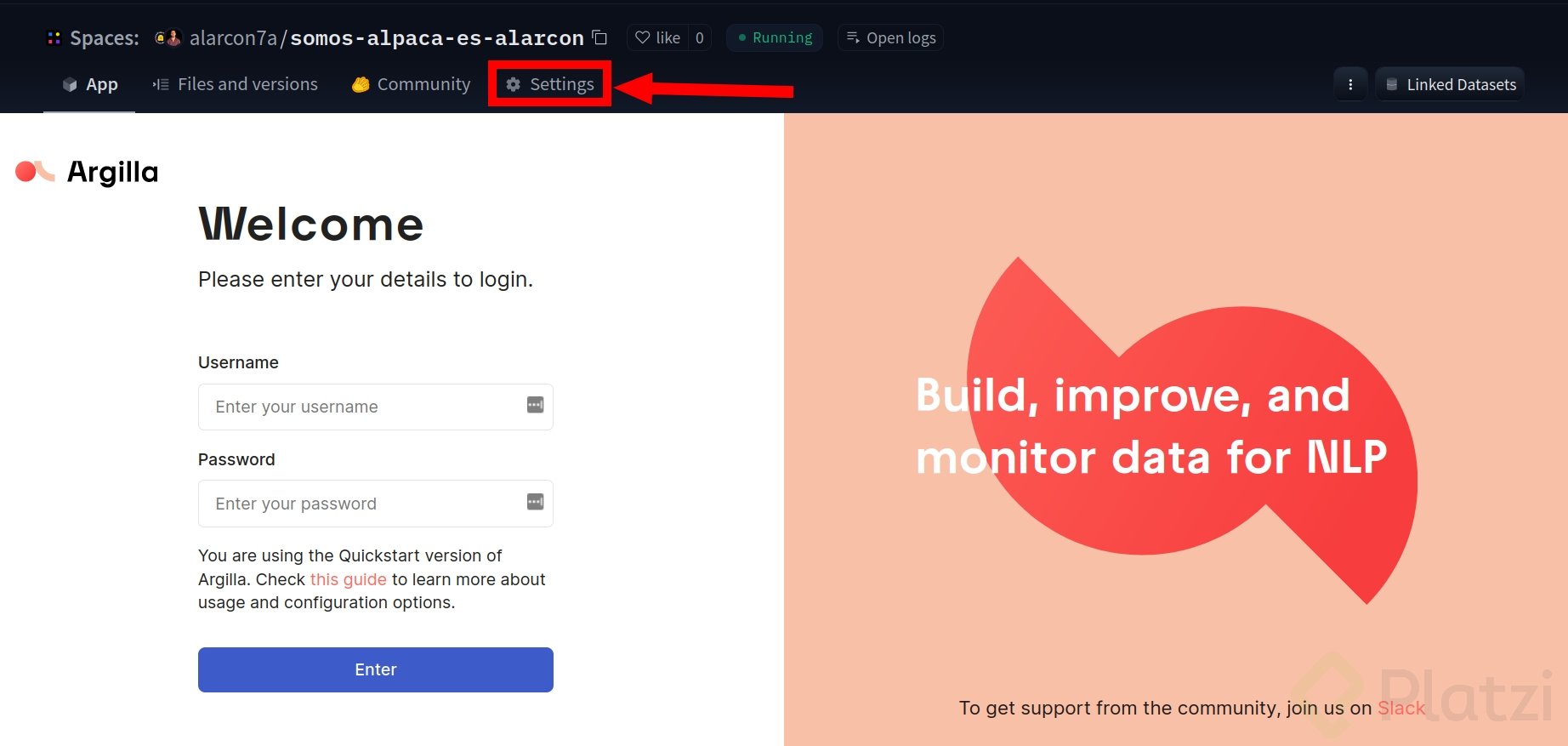
Una vez creado el espacio, deberás ver algo como en la imagen de referencia. Haz clic en “settings” y crea dos variables de entorno:
HF_TOKEN, que es nuestro token de escritura.HUB_DATASET_NAME, que es el dataset donde quieres guardarlo.Es importante incluir la organización o persona seguido de un / y el nombre del dataset. Por ejemplo: alarcon7a/somos-clean-alpaca-es-validations o miempresa/somos-clean-alpaca-es-validations.
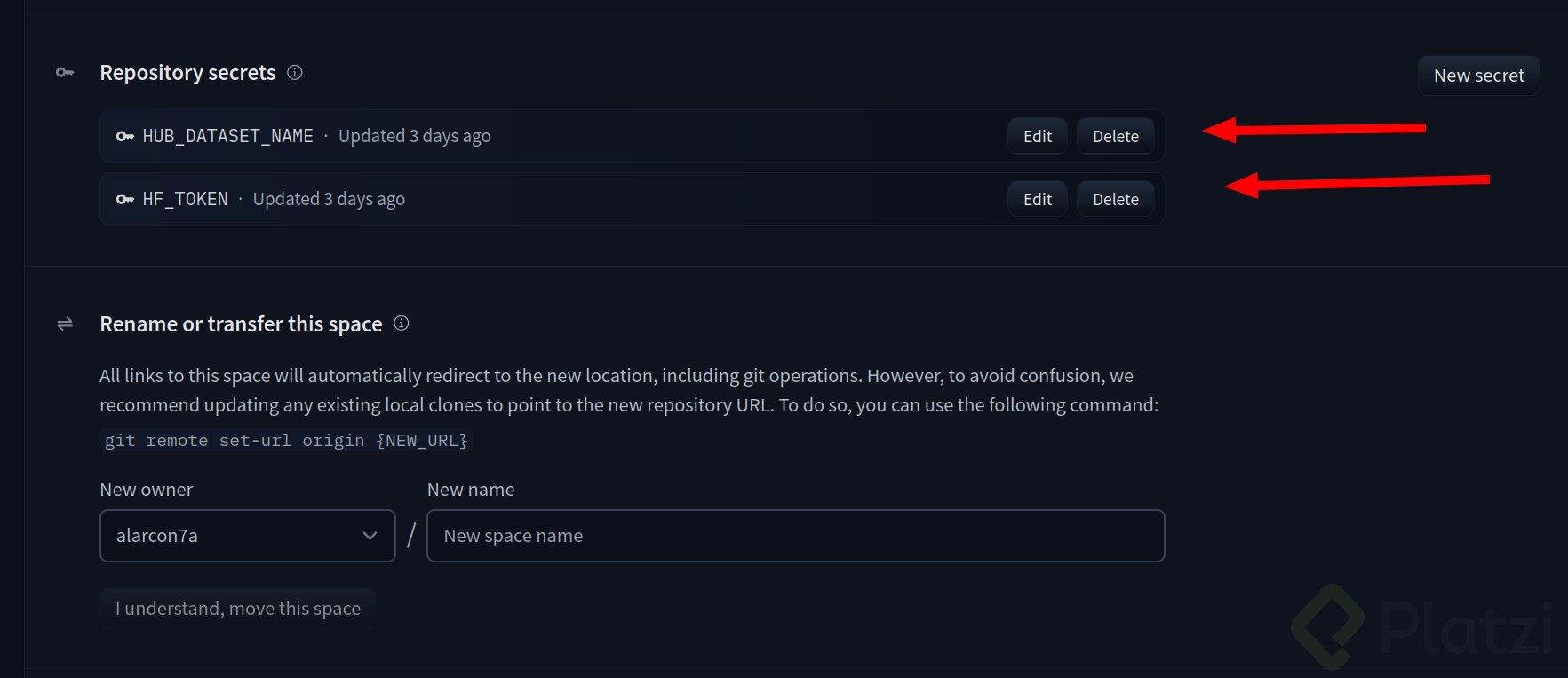
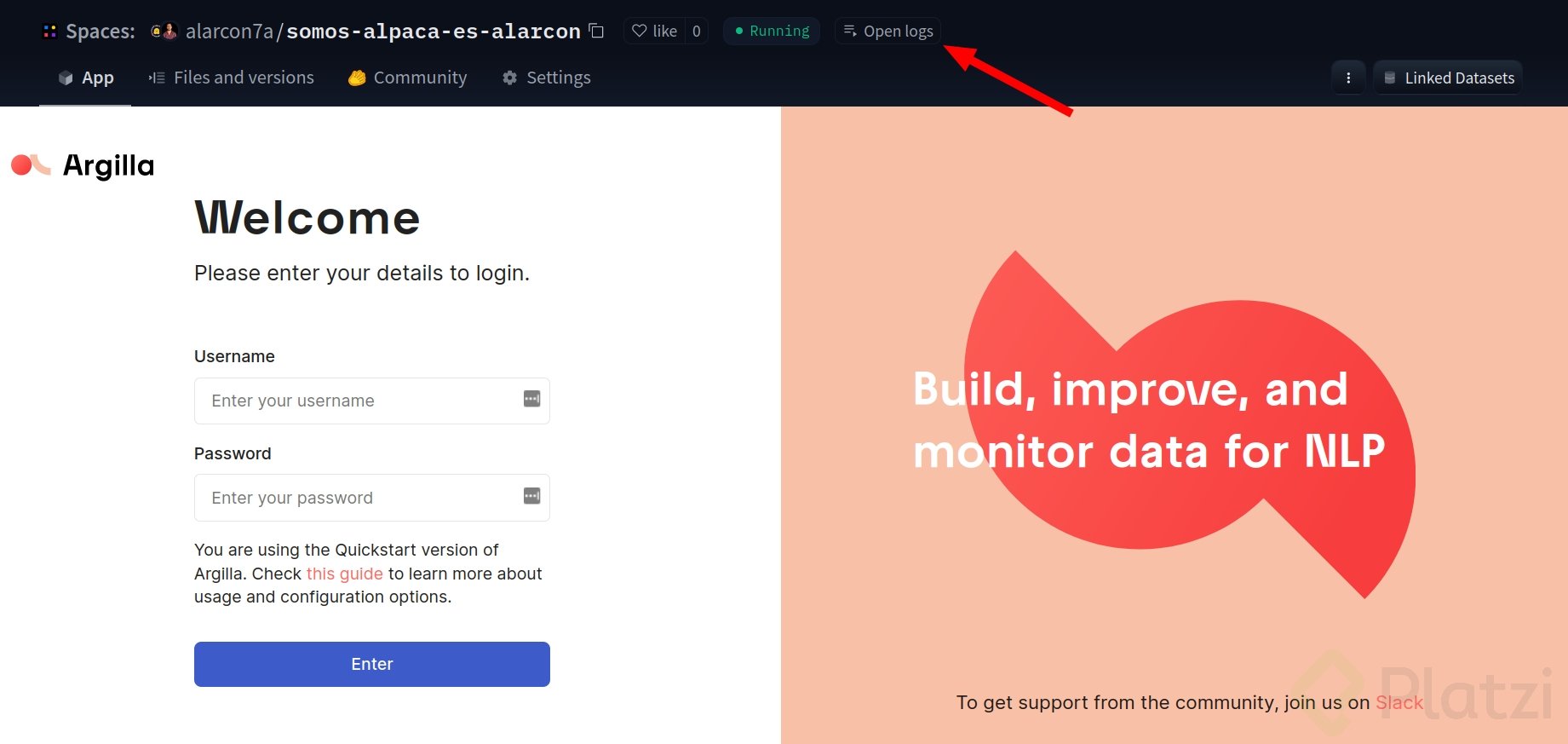
💡 Puedes ver los registros del Space para validar si se aplicaron las claves correctamente.
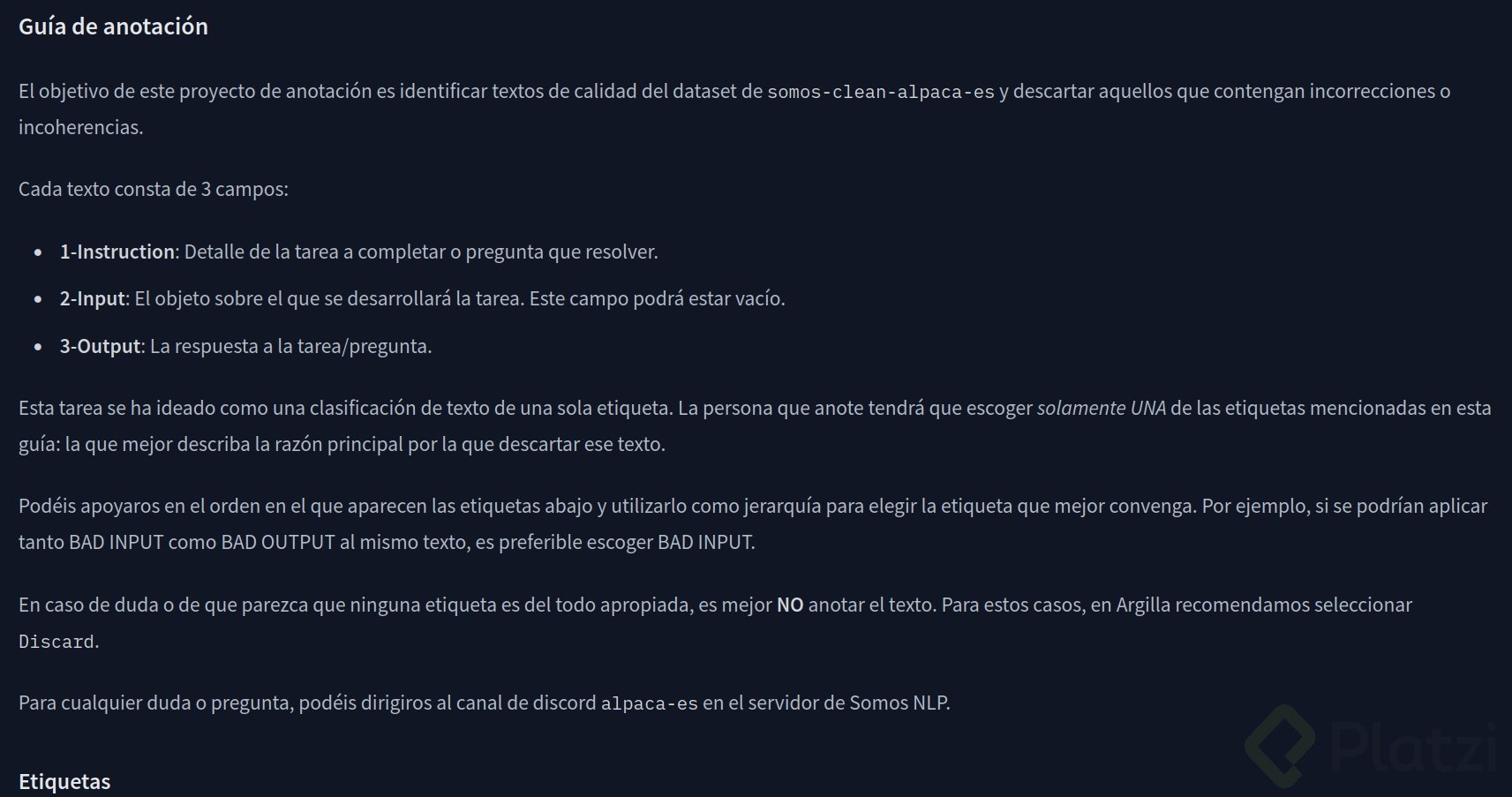
En este enlace podrás leer la guía de anotación para entender correctamente la estructura de etiquetado que vamos a manejar como comunidad.
💡 Lee la guía completa y no solo la referencia de la imagen en este blog.
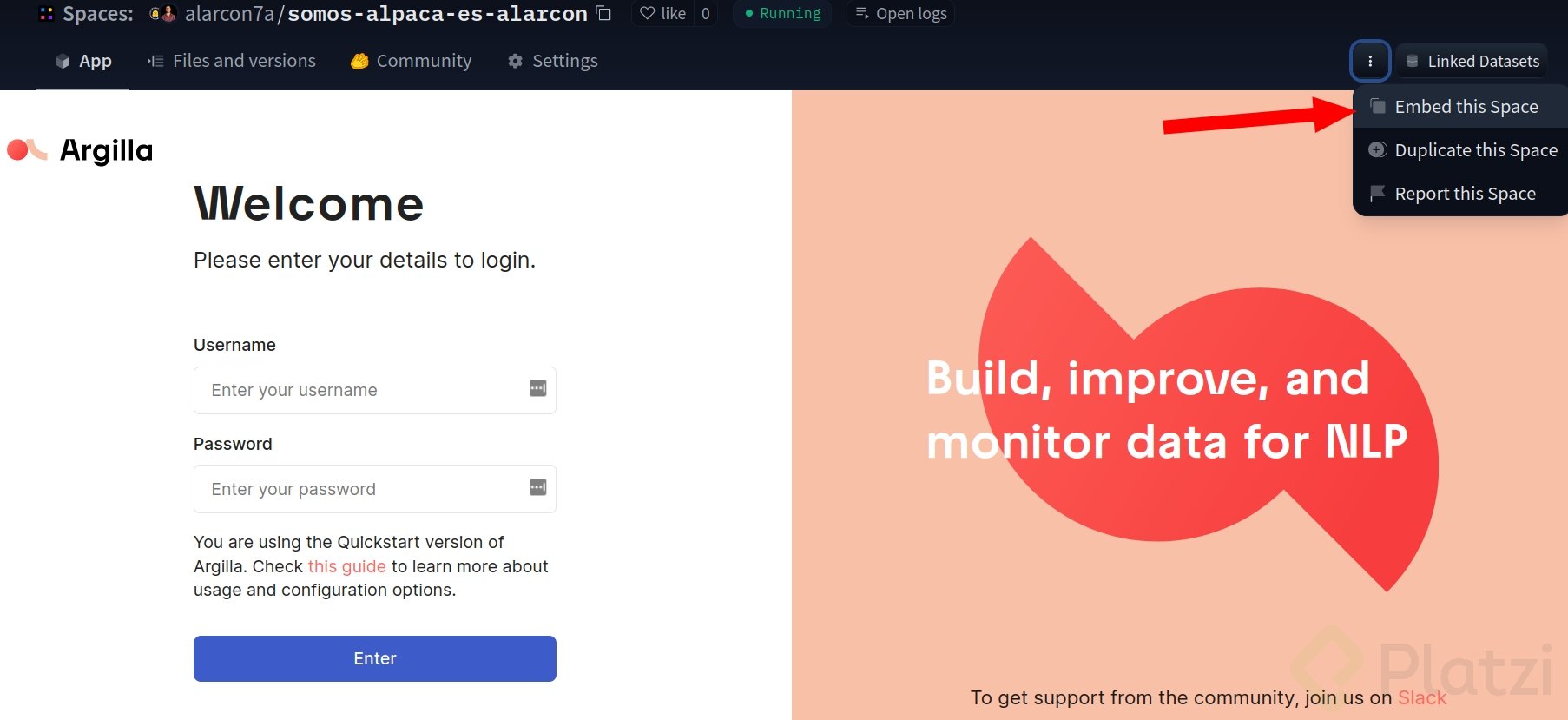
Para ingresar a etiquetar y aportar a la comunidad, debes conseguir en enlace web de Argilla, el cual puedes encontrar en “Embebed this space”.
💡 Argilla es un framework para el etiquetado y manipulación de dataset para procesos de NLP.
Copia la siguiente URL y llévala a tu navegador.
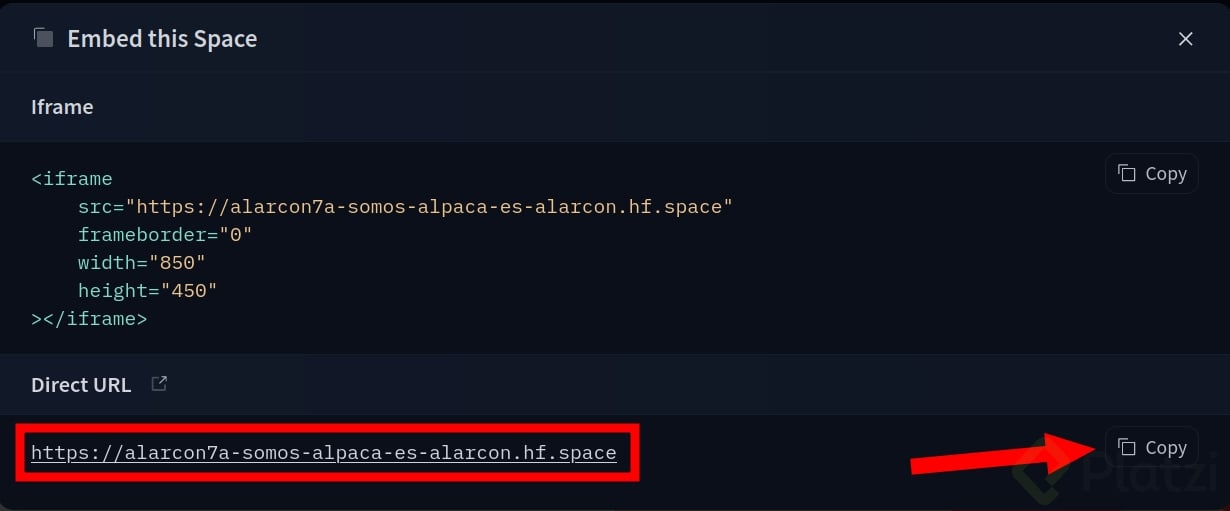
Ingresa al dataset de Alpaca que deberá estar en tu espacio.
💡 Ingresa con:
usuario: argilla
pass: 1234
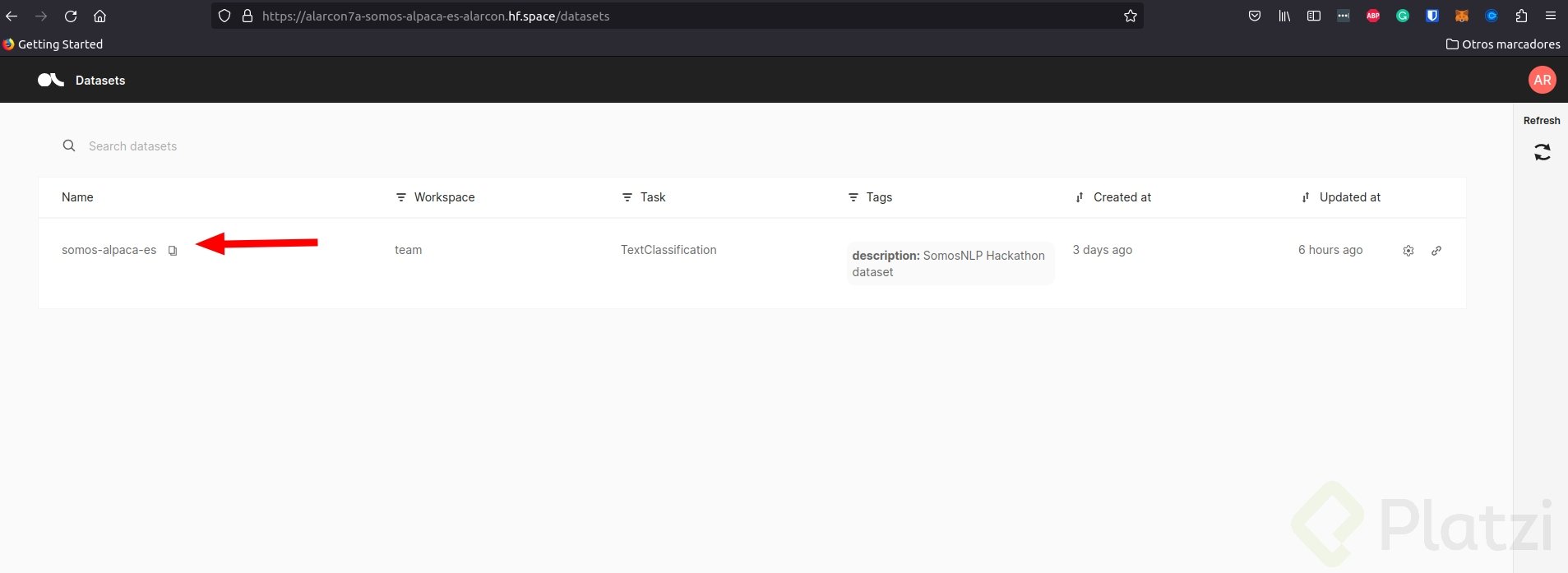
Comienza a validar y etiquetar el dataset según la guía.
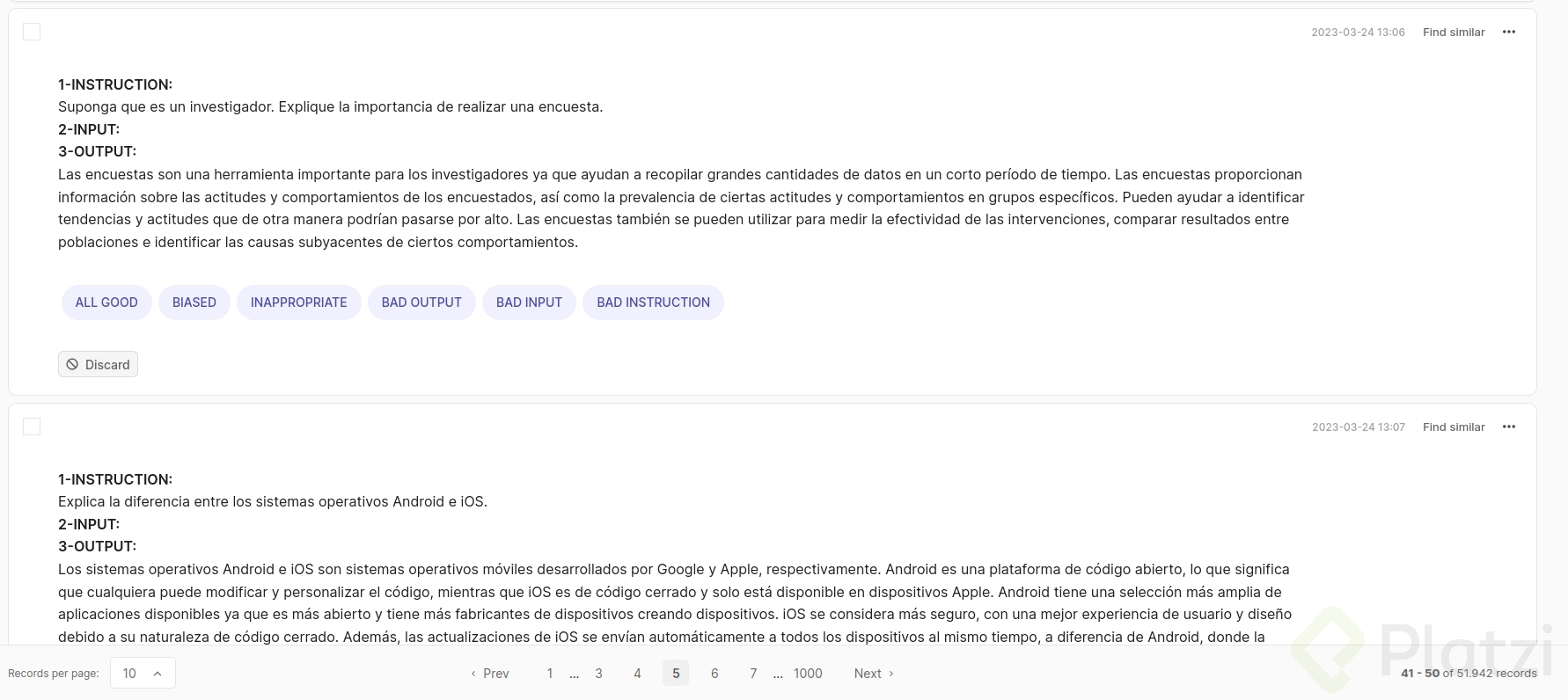
Si llegas a encontrar una instrucción o sentencia que este mal redactada o tenga errores, violencia o necesite revisión de alguna manera puedes usar “Find similar” para que te ayude a buscar sentencias parecidas y corregirlas de manera mas eficiente.
Un ejemplo de ello es esta instrucción que se encuentra en francés 🇫🇷

Aunque se ha configurado el espacio para que se sincronice con un dataset del Hub a tu elección, para tener más seguridad se recomienda guardar una copia del dataset en el Hub ejecutando el siguiente código.
Es necesario hacer login con Python usando from huggingface_hub import notebook_login o añadir el token directamente al hacer el push_to_hub.
import argilla as rg
# usar rg.init() para definir la API_URL (la direct URL de tu Space de Argilla) y API_KEY
rg.init(
api_url="https://tu-space-de-argilla.hf.space", ### en mi caso https://alarcon7a-somos-alpaca-es-alarcon.hf.space
api_key="team.apikey"
)
# Leer dataset con validaciones de Argilla
rg_dataset = rg.load("somos-clean-alpaca-es-team", query="status:Validated")
# Transformar a formato datasets
dataset = rg_dataset.to_datasets()
# Publicar en el Hub, puedes usar cualquier nombre de dataset que elijas
dataset.push_to_hub("somos-clean-alpaca-es", token="TU TOKEN WRITE EN SETTINGS HUB. NO NECESARIO SI HAS HECHO LOGIN")
El objetivo no es solo etiquetar un dataset, el gran objetivo es apoyarnos de ese dataset para mediante modelos como LLaMA, Bloom u otros modelos open source realizar tareas de fine tuning y crear modelos prácticos, útiles y gratuitos para nuestra comunidad. Uno de ellos es Chivoom un modelo que ya se encuentra en el repositorio de Platzipero aun requiere de afinamiento en su entrenamiento.

En esta sección te dejo algunos enlaces que te pueden interesar para aterrizar mucho mejor lo aprendido en este tutorial.
¡Sígueme en Instagram/Twitter/TikTok como @alarcon7a para hablar sobre IA y temas relacionados a los datos!







Estoy dentro,
open source ❤️
Buenas tardes;
Quizás las preguntas esté de sobra, pero:
¿Esto es posible con los modelos Alpaca, o es posible hacer este proceso con los modelos LLaMa -2?, específicamente con el 7b.
¿Es posible “entrenarlos” con cualquier información siempre y cuando esté realizada por profesionales?
Pregunto, porque no me queda del todo claro al 100% el proceso, y me interesa muchísimo el tema para entrenarlo y depurarlo con información que he corroborado que es erronea.
Saludos y gracias.
Buenas tardes. Me genero la URL: https://caveli-somos-alpaca-es.hf.space/login?redirect=%2F. Digito Usuario: arguilla y pwd: 1234. Sale: “Wrong username or password. Try again”
De otra parte se indica que “Puedes ver los registros del Space para validar si se aplicaron las claves correctamente.”. Al revisar el log aparece:
INFO: 127.0.0.1:35152 - “GET / HTTP/1.1” 200 OK
INFO: 127.0.0.1:35156 - “GET /api/me HTTP/1.1” 200 OK
INFO: 127.0.0.1:35156 - “GET /api/me HTTP/1.1” 200 OK
INFO: 127.0.0.1:35156 - “GET /api/workspaces HTTP/1.1” 200 OK
etc,
Pregunta: Estara ok?